

Verschil tussen Apache Hive en Apache HBase -
Het Apache Hive-verhaal begint in het jaar 2007, wanneer niet-Java-programmeurs moeten worstelen tijdens het gebruik van Hadoop MapReduce. Onderzoekers en ontwikkelaars voorspelden dat morgen een tijdperk van Big Data is. Reeds verschillende formaten van data zoals gestructureerd, semi-gestructureerd en ongestructureerd stapelden zich op. Zelfs Facebook worstelde met de grotere hoeveelheid gegevensverwerking. Onderzoekers van Facebook introduceerden Apache Hive voor gegevensverwerking op Hadoop Cluster. Facebook was het eerste bedrijf dat Apache Hive bedacht.
Het verhaal van Apache HBase begint in 2006, toen de in San Francisco gevestigde startup Powerset een natuurlijke taalzoekmachine voor het web probeerde te bouwen. HBase is een implementatie van Google's Bigtable. Hebben we ons ooit gerealiseerd, waarom er behoefte was aan een nieuwe opslagarchitectuur? Relational Database Management System bestaat al sinds het begin van de jaren zeventig. Er zijn veel gebruikssituaties waarvoor relationele databases volkomen logisch zijn, maar voor sommige specifieke problemen past het relationele model niet zo goed.
Laat me meer uitleg geven over Apache Hive en Apache HBase.
Verschillen tussen Apache Hive en Apache HBase
Apache Hive is een open source-project van Apache dat bovenop Hadoop is gebouwd voor het opvragen, samenvatten en analyseren van grote gegevenssets met behulp van een SQL-achtige interface. Apache Hive biedt een SQL-achtige taal genaamd HiveQL, die query's transparant converteert naar MapReduce voor uitvoering op grote datasets die zijn opgeslagen in Hadoop Distributed File System (HDFS). Apache Hive is een Hadoop-clustercomponent die normaal wordt gebruikt door gegevensanalisten. Apache-component wordt gebruikt voor batchverwerking van grote ETL-taken. Apache Hive ondersteunt ook batch-SQL-query's op zeer grote gegevenssets. Apache Hive verhoogt de schemaontwerpflexibiliteit en ook gegevensserialisatie en deserialisatie. Apache Hive biedt geen ondersteuning voor Online Transaction Processing (OLTP) omdat Hive geen vragen ondersteunt in realtime en updates op rijniveau.
Apache HBase is een open source NoSQL-database die realtime lees- en schrijftoegang biedt tot grote datasets. NoSQL is een niet-relationele database. Apache HBase is een gedistribueerde kolomgerichte database die wordt uitgevoerd bovenop Hadoop Distributed File System (HDFS). HBase brengt dus voordelen van NoSQL naar Hadoop. Apache HBase biedt mogelijkheden voor willekeurige toegang tot gegevens in HDFS. Het maakt gebruik van de fouttolerantie die wordt geboden door de HDFS. De gebruiker kan de gegevens rechtstreeks of via HBase in HDFS opslaan.
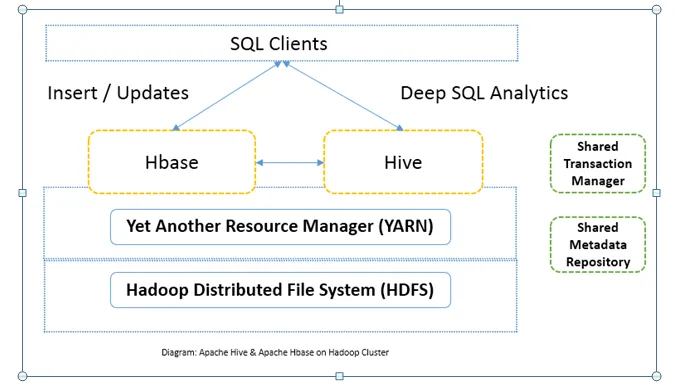
Head to Head-vergelijking tussen Apache Hive versus Apache HBase (Infographics)
Hieronder staat het top 12 verschil tussen Apache Hive en Apache HBase

Belangrijkste verschillen - Apache Hive versus Apache HBase
Hieronder staan de lijst met punten, beschrijf de belangrijkste verschillen tussen Apache Hive en Apache HBase:
- Apache HBase is een database, terwijl Apache Hive een database-engine is.
- Apache Hive wordt voornamelijk gebruikt voor batchverwerking (OLAP), terwijl Apache HBase voornamelijk wordt gebruikt voor transactieverwerking (OLTP).
- Apache Hive voert de meeste SQL-query's uit, terwijl Apache HBase SQL-query's niet rechtstreeks toestaat.
- Apache Hive ondersteunt geen bewerkingen op recordniveau zoals bijwerken, invoegen en verwijderen, terwijl Apache HBase bewerkingen op recordniveau ondersteunt zoals bijwerken, invoegen en verwijderen.
- Apache Hive wordt uitgevoerd op MapReduce, terwijl Apache HBase wordt uitgevoerd op Hadoop Distributed File System (HDFS).
Apache Hive doorzoekt de bestanden door een virtuele tabel te definiëren en daar bovenop HQL-query's uit te voeren. Het is een proces waarbij bestanden virtueel zijn verbonden met een tabelachtige structuur en de gebruiker Hive Query Language (HQL) kan uitvoeren en deze query's worden geconverteerd naar MapReduce Job by Hive. De gebruiker hoeft geen MapReduce-taak te schrijven, HQL-query's worden intern geconverteerd naar jar-bestanden en deze jar-bestanden worden geïmplementeerd in datasets.
In Apache HBase worden tabellen opgesplitst in regio's en worden bediend door de regioservers. Verdere regio's zijn verticaal onderverdeeld door kolomfamilies in winkels en Stores worden opgeslagen als bestanden in HDFS.
Wanneer Apache Hive gebruiken:
- Vereisten voor gegevensopslag
- Analytische vragen
- Gegevensanalyse die bekend zijn met SQL
Wanneer Apache HBase gebruiken:
- Snelle en interactieve gegevensverwerking
- Realtime vragen
- Snelle opzoekingen
- Server-side verwerking
- Willekeurige lees- / schrijftoegang tot Big Data
- Schaalbaarheid van applicaties
Apache Hive kan worden gebruikt om trends en logs van e-commerce websites te berekenen voor een bepaalde duur, regio of tijdzone. Het kan worden gebruikt om batchquery's over historische gegevens te verwerken, terwijl Apache HBase door Facebook of LinkedIn kan worden gebruikt voor berichten en realtime analyses. Het kan ook worden gebruikt voor het tellen van likes.
Apache Hive vs Apache HBase Vergelijkingstabel
Ik bespreek belangrijke artefacten en maak onderscheid tussen Apache Hive en Apache HBase.
| Apache Hive | Apache HBase | |
| Gegevensverwerking | Apache Hive wordt gebruikt voor
batchverwerking dwz Online Analytical Processing (OLAP) | Apache HBase wordt gebruikt voor transactieverwerking, dwz online transactieverwerking (OLTP) |
| Verwerkingssnelheid | Apache Hive heeft een hogere latentie vanwege het uitvoeren van een MapReduce-taak op de achtergrond | Apache HBase werkt op real-time query's en veel sneller dan Apache Hive |
| Compatibiliteit met Hadoop | Apache Hive wordt uitgevoerd op MapReduce | Apache HBase draait op HDFS |
| Definitie | Apache Hive is open source en vergelijkbaar met SQL die wordt gebruikt voor analytische zoekopdrachten | Apache HBase is een open source NoSQL-database die wordt gebruikt voor realtime query's |
| Gedeelde metagegevens | Gegevens gemaakt in Apache Hive zijn automatisch zichtbaar voor Apache HBase | Gegevens gemaakt in Apache HBase zijn automatisch zichtbaar voor Apache Hive |
| Schema | Apache hive ondersteunt Schema voor het invoegen van gegevens in tabellen | Apache HBase is een schemavrije database. |
| Update functie | De updatefunctie is ingewikkeld in Apache Hive | De gebruiker kan de gegevens in Apache HBase heel gemakkelijk bijwerken |
| Activiteiten | Bewerkingen in Apache Hive worden niet in realtime uitgevoerd | Bewerkingen in Apache HBase worden in realtime uitgevoerd |
| Gegevenstypen | Apache Hive is bedoeld voor gestructureerde en semi-gestructureerde gegevens | Apache HBase is voor ongestructureerde gegevens. |
| Consistentie niveau | Apache-bijenkorf ondersteunt Eventuele consistentie | Apache HBase ondersteunt onmiddellijke consistentie |
| Partitie methoden | Apache Hive ondersteunt Sharding-functies | Apache HBase ondersteunt ook Sharding-functies |
| Gegevens opslag | De datum wordt opgeslagen in Hive Metastore, partities en emmers in Apache Hive | Gegevens worden opgeslagen in Kolom en Rij-gewijs van tabellen in Apache HBase |
Conclusie - Apache Hive vs Apache HBase
Gewoonlijk wordt Apache Hive versus Apache HBase samen in hetzelfde cluster gebruikt. Beide kunnen samen worden gebruikt om de verwerkingskracht te vergroten. Omdat bijenkorf de analytische kanten van HDFS verbetert, terwijl HBase transacties in realtime verbetert. De gebruiker kan Hive gebruiken als een ETL-tool voor batchinvoegingen met de gegevens in HBase en vervolgens om query's uit te voeren die gegevens die aanwezig zijn in HBase-tabellen verder kunnen combineren met de gegevens die al aanwezig zijn op HDFS. Gegevens kunnen worden gelezen en geschreven van Apache Hive naar HBase en weer terug. De interface tussen Apache Hive en Apache HBase is nog aan het rijpen. Er komt nog veel meer. Toch kan ik zeggen dat zowel Apache Hive versus Apache HBase het Hadoop-cluster robuuster en krachtiger maakt.
Gerelateerde artikelen:
Dit is een leidraad geweest voor Apache Hive versus Apache HBase, hun betekenis, Head to Head Comparison, Key Differences, Comparision Table en Conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Top 5 Big Data-trends
- 5 uitdagingen van Big Data Analytics
- Hoe het Hadoop-ontwikkelaarsinterview te kraken?
- 5 uitdagingen van Big Data Analytics