

Inleiding tot Hadoop Architecture
Hadoop Architecture is een open source framework dat helpt bij het gemakkelijk verwerken van grote datasets. Het helpt bij het maken van applicaties die enorme gegevens sneller verwerken. Het maakt gebruik van de gedistribueerde computerconcepten waarbij gegevens worden verspreid over verschillende knooppunten van een cluster. De applicaties die zijn gebouwd met Hadoop maken gebruik van basiscomputers. Deze computers zijn gemakkelijk verkrijgbaar in de markt tegen goedkope tarieven. Dit resultaat levert een grotere rekenkracht op tegen lage kosten. Alle gegevens in Hadoop bevinden zich op HDFS in plaats van op een lokaal bestandssysteem. HDFS is een Hadoop gedistribueerd bestandssysteem. Dit model is gebaseerd op datalocatie waarbij de rekenlogica wordt verzonden naar de knooppunten in een cluster die de gegevens bevat. Deze logica is niets anders dan een logica die het programma compileert.
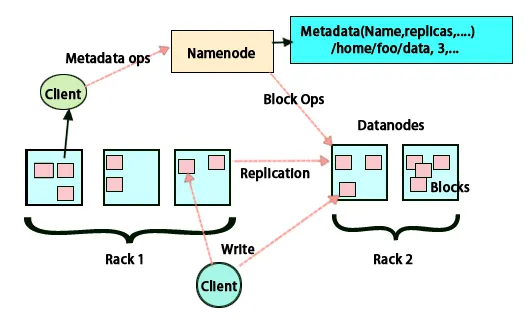
Hadoop-architectuur
Het basisidee van deze architectuur is dat het gehele opslaan en verwerken in twee stappen en op twee manieren gebeurt. De eerste stap is de verwerking die wordt uitgevoerd door Map reduceer programmeren en de tweede stap is het opslaan van de gegevens die op HDFS worden gedaan. Het heeft een master-slave-architectuur voor opslag en gegevensverwerking. Het hoofdknooppunt voor gegevensopslag in Hadoop is het naamknooppunt. Er is ook een masterknooppunt dat het werk doet van monitoring en parallel loopt aan gegevensverwerking door gebruik te maken van Hadoop Map Reduce. De slaves zijn andere machines in het Hadoop-cluster die helpen bij het opslaan van gegevens en ook complexe berekeningen uitvoeren. Aan elk slaafknooppunt is een taakvolger toegewezen en een gegevensknooppunt heeft een opdrachtvolger die helpt bij het uitvoeren van de processen en het effectief synchroniseren ervan. Dit type systeem kan in de cloud of op locatie worden ingesteld. Het knooppunt Naam is een enkel storingspunt wanneer het niet wordt uitgevoerd in de modus voor hoge beschikbaarheid. De Hadoop-architectuur biedt ook de mogelijkheid om een stand-by-knooppunt te behouden om het systeem tegen storingen te beschermen. Voorheen waren er secundaire naamknooppunten die fungeerden als back-up toen het primaire naamknooppunt niet actief was.
FSimage en logboek bewerken
FSimage en het bewerkingslogboek zorgen voor persistentie van de metagegevens van het bestandssysteem om alle informatie bij te houden en de naamknooppunt slaat de metagegevens op in twee bestanden. Deze bestanden zijn de FSimage en het bewerkingslogboek. De taak van FSimage is om op een gegeven moment een complete momentopname van het bestandssysteem te houden. De wijzigingen die voortdurend in een systeem worden aangebracht, moeten worden geregistreerd. Deze incrementele wijzigingen zoals het hernoemen of toevoegen van details aan het bestand worden opgeslagen in het bewerkingslogboek. Het framework biedt een betere optie dan elke keer een nieuw FSimage te maken, een betere optie om de gegevens op te slaan terwijl een nieuw bestand voor FSimage. FSimage maakt een nieuwe momentopname telkens wanneer wijzigingen worden aangebracht Als het knooppunt Naam mislukt, kan het de vorige status herstellen. Het secundaire naamknooppunt kan zijn kopie ook bijwerken wanneer er wijzigingen zijn in FSimage en logs bewerken. Het zorgt er dus voor dat, hoewel het naamknooppunt niet actief is, er in de aanwezigheid van een secundair naamknooppunt geen gegevensverlies optreedt. Voor het naamknooppunt hoeven deze afbeeldingen niet opnieuw te worden geladen op het secundaire naamknooppunt.
Gegevensreplicatie
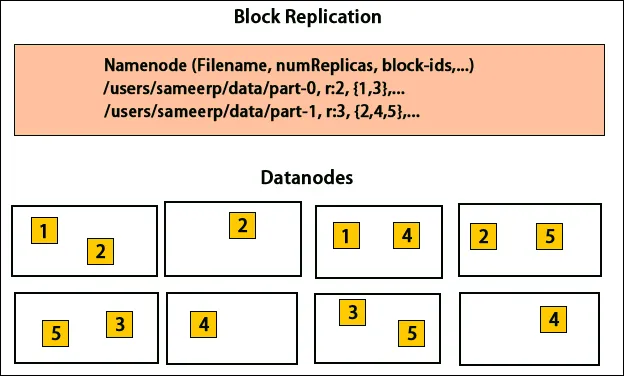
HDFS is ontworpen om gegevens snel te verwerken en betrouwbare gegevens te bieden. Het slaat gegevens op machines en in grote clusters op. Alle bestanden worden opgeslagen in een reeks blokken. Deze blokken worden gerepliceerd voor fouttolerantie. De blokgrootte en replicatiefactor kunnen door de gebruikers worden bepaald en worden geconfigureerd volgens de gebruikersvereisten. Standaard is de replicatiefactor 3. De replicatiefactor kan worden opgegeven bij het maken van het bestand en kan later worden gewijzigd. Alle beslissingen met betrekking tot deze replica's worden genomen door het naamknooppunt. Het naamknooppunt verzendt regelmatig hartslagen en blokkeert rapportage voor alle gegevensknooppunten in het cluster. De ontvangst van een hartslag houdt in dat het dataknooppunt correct werkt. Blokrapport geeft de lijst aan van alle blokken op het gegevensknooppunt.
Plaatsing van replica's
Het plaatsen van replica's is een zeer belangrijke taak in Hadoop voor betrouwbaarheid en prestaties. Alle verschillende gegevensblokken worden op verschillende rekken geplaatst. De implementatie van replicaplaatsing kan worden gedaan op basis van betrouwbaarheid, beschikbaarheid en gebruik van netwerkbandbreedte. Het cluster van computers kan over verschillende racks worden verdeeld. Er kunnen niet meer dan twee knopen op hetzelfde rek worden geplaatst. De derde replica moet op een ander rek worden geplaatst om meer betrouwbaarheid van gegevens te garanderen. De twee knooppunten op het rek communiceren via verschillende schakelaars. Het naamknooppunt heeft het rack-ID voor elk gegevensknooppunt. Maar het plaatsen van alle knooppunten op verschillende racks voorkomt verlies van gegevens en maakt het gebruik van bandbreedte van meerdere racks mogelijk. Het vermindert ook het verkeer tussen racks en verbetert de prestaties. Ook is de kans op rackstoring zeer kleiner in vergelijking met die van knoopstoring. Het vermindert de totale netwerkbandbreedte wanneer gegevens worden gelezen van twee unieke racks in plaats van drie.
Kaart verkleinen
Map Reduce wordt gebruikt voor het verwerken van gegevens die zijn opgeslagen op HDFS. Het schrijft gedistribueerde gegevens over gedistribueerde toepassingen die zorgen voor een efficiënte verwerking van grote hoeveelheden gegevens. Ze verwerken op grote clusters en vereisen grondstoffen die betrouwbaar en fouttolerant zijn. De kern van Map-verkleinen kan drie bewerkingen zijn, zoals kaarten, het verzamelen van paren en het schudden van de resulterende gegevens.
Conclusie - Hadoop-architectuur
Hadoop is een open source framework dat helpt bij een fouttolerant systeem. Het kan grote hoeveelheden gegevens opslaan en helpt bij het opslaan van betrouwbare gegevens. De twee delen van het opslaan van gegevens in HDFS en het verwerken ervan door middel van kaarten verminderen de hulp bij het correct en efficiënt werken. Het heeft een architectuur die helpt bij het beheer van alle gegevensblokken en heeft ook de meest recente kopie door het op te slaan in FSimage en logs te bewerken. De replicatiefactor helpt ook bij het hebben van kopieën van gegevens en deze terug te krijgen wanneer er een storing is. HDFS verplaatst ook verwijderde bestanden naar de prullenbak voor optimaal ruimtegebruik.
Aanbevolen artikelen
Dit is een gids voor Hadoop Architecture geweest. Hier hebben we de architectuur, kaartvermindering, plaatsing van replica's en gegevensreplicatie besproken. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Word een Hadoop-ontwikkelaar
- Introductie tot Android
- Wat is Tableau? | Een overzicht
- Wat is MapReduce in Hadoop?