

Inleiding tot lineaire algebra in machinaal leren
Lineaire algebra is een onderdeel van de wiskunde dat lineaire vergelijkingen en hun representaties door matrices en vectorruimten omvat. Het helpt bij het beschrijven van de functies van algoritmen en het implementeren ervan. Het wordt gebruikt met gegevens of afbeeldingen in tabelvorm om de algoritmen beter te tweaken om er het beste resultaat uit te halen. In dit onderwerp gaan we meer te weten over lineaire algebra in machine learning.
Matrix: het is een reeks getallen in een rechthoekige vorm, voorgesteld door rijen en kolommen.
Voorbeeld:
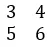
Vector: een vector is een rij of kolom van een matrix.
Voorbeeld:
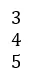
Tensor: Tensoren zijn een reeks getallen of functies die met bepaalde regels transmuteren wanneer coördinaten worden gewijzigd.
Hoe werkt lineaire algebra in machine learning?
Aangezien Machine Learning het aanspreekpunt is voor informatica en statistiek, helpt Linear Algebra bij het combineren van wetenschap, technologie, financiën en accounts en commercie. Numpy is een bibliotheek in Python die werkt op multidimensionale arrays voor wetenschappelijke berekeningen in Data Science en ML.
Lineaire algebra werkt op verschillende manieren, zoals wordt weerspiegeld in enkele voorbeelden hieronder:
1. Dataset en gegevensbestanden
Een data is een matrix of een datastructuur in lineaire algebra. Een gegevensset bevat een set getallen of gegevens in tabelvorm. Rijen vertegenwoordigen observaties, terwijl kolommen kenmerken ervan vertegenwoordigen. Elke rij heeft dezelfde lengte. Gegevens zijn dus gevectoriseerd. Rijen zijn vooraf geconfigureerd en worden één voor één in het model ingevoegd voor eenvoudigere en authentieke berekeningen.
2. Afbeeldingen en foto's
Alle afbeeldingen hebben een tabelstructuur. Elke cel in zwart-witafbeeldingen bestaat uit hoogte, breedte en één pixelwaarde. Op dezelfde manier hebben kleurenafbeeldingen 3 pixels naast de hoogte en breedte. Het vormt een matrix in lineaire algebra. Allerlei bewerkingen zoals bijsnijden, schalen, enz. En manipulatietechnieken worden uitgevoerd met behulp van algebraïsche bewerkingen.
3. Regularisatie
Regularisatie is een methode die de grootte van coëfficiënten minimaliseert terwijl deze in gegevens wordt ingevoegd. L1 en L2 zijn van enkele veel voorkomende implementatiemethoden bij regularisatie, die maatstaven zijn van de grootte van coëfficiënten in een vector.
4. Diep leren
Deze methode wordt meestal gebruikt in neurale netwerken met verschillende real-life oplossingen, zoals machinevertaling, fotobijschriften, spraakherkenning en vele andere gebieden. Het werkt met vectoren, matrices en zelfs tensoren, omdat lineaire datastructuren moeten worden toegevoegd en vermenigvuldigd.
5. Een hete codering
Het is een populaire codering voor categorische variabelen voor eenvoudigere bewerkingen in algebra. Een tabel is opgebouwd met één kolom voor elke categorie en rij voor elk voorbeeld. Cijfer 1 wordt toegevoegd voor categorische waarde, opgevolgd door 0 in de rest enzovoort, zoals hieronder aangehaald:

6. Lineaire regressie
Lineaire regressie, een van de statistische methoden, wordt gebruikt voor het voorspellen van numerieke waarden voor regressieproblemen en voor het beschrijven van de relatie tussen variabelen.
Voorbeeld: y = A. b waarbij A een gegevensset of matrix is, b is coëfficiënt en y is de uitvoer.
7. Hoofdcomponentanalyse of PCA
Belangrijkste componentenanalyse is van toepassing tijdens het werken met hoogdimensionale gegevens voor visualisatie en modelbewerkingen. Wanneer we irrelevante gegevens vinden, hebben we de neiging om de overbodige kolom (men) te verwijderen. Dus PCA fungeert als een oplossing. Matrixfactorisatie is het hoofddoel van PCA.
8. Decompositie met enkele waarde of SVD
Het is ook een matrixfactorisatie-methode die meestal wordt gebruikt bij visualisatie, ruisreductie, etc.
9. Latente semantische analyse
In dit proces worden documenten weergegeven als grote matrices. Document verwerkt in deze matrices is eenvoudig te vergelijken, op te vragen en te gebruiken. Een matrix is opgebouwd waarbij rijen woorden vertegenwoordigen en kolommen documenten vertegenwoordigen. SVD wordt gebruikt om het aantal kolommen te verminderen met behoud van de gelijkenis.
10. Aanbevelingssystemen
Voorspellende modellen vertrouwen op de aanbeveling van producten. Met behulp van Linear Algebra functioneert SVD om gegevens te zuiveren met behulp van Euclidische afstands- of puntproducten. Wanneer we bijvoorbeeld een boek op Amazon kopen, zijn aanbevelingen gebaseerd op onze aankoopgeschiedenis, waarbij andere irrelevante items buiten beschouwing worden gelaten.
Voordelen van lineaire algebra bij machinaal leren
- Fungeert als een solide basis voor machine learning met zowel wiskunde als statistiek.
Zowel in tabelvorm als in afbeeldingen kunnen in lineaire gegevensstructuren worden gebruikt. - Het is ook distributief, associatief en communicatief.
- Het is een eenvoudige, constructieve en veelzijdige aanpak in ML.
- Lineaire algebra is toepasbaar op vele gebieden, zoals voorspellingen, signaalanalyse, gezichtsherkenning, enz.
Lineaire Algebra-functies in Machine Learning
Er zijn enkele Lineaire Algebra-functies die van vitaal belang zijn in ML- en Data Science-bewerkingen zoals hieronder beschreven:
1. Lineaire functie
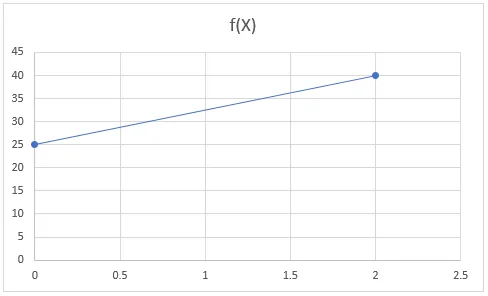
Het lineaire regressie-algoritme gebruikt een lineaire functie waarbij de uitvoer continu is en een constante helling heeft. Lineaire functies hebben een rechte lijn in de grafiek.
F (x) = mx + b
Waar, F (x) de waarde van de functie is,
m is de helling van de lijn,
b is de waarde van de functie wanneer x = 0,
x is de waarde van x-coördinaat.
Voorbeeld: y = 5x + 25
Laat x = 0 en dan y = 5 * 1 + 25 = 25
Laat x = 2 en dan y = 5 * 2 + 25 = 40
2. Identiteitsfunctie
Identiteitsfunctie valt onder het niet-gecontroleerde algoritme en wordt meestal gebruikt in neurale netwerken in ML waar de output van het meerlagige neurale netwerk gelijk is aan zijn input, zoals hieronder aangehaald:
Voor elke x, f (x) kaarten naar x dwz x kaarten naar zichzelf.
Voorbeeld: x + 0 = x
x / 1 x =
1 ---> 1
2 ---> 2
3 ---> 3
3. Samenstelling
ML gebruikt hogere-orde samenstelling en pipelining-functies in zijn algoritmen voor wiskundige berekeningen en visualisaties. Samenstelling functie wordt hieronder beschreven:
(GOF) (x) = g (f (x))
Voorbeeld: let g (y) = y
f (x) = x + 1
gof (x + 1) = x + 1
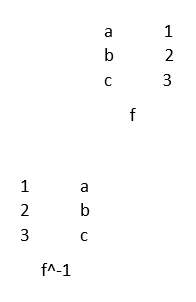
4. Omgekeerde functie
Het omgekeerde is een functie die zichzelf omkeert. Functies f en g zijn omgekeerd als mist en gof zijn gedefinieerd en identiteitsfuncties zijn
Voorbeeld:
5. Omkeerbare functie
Een inverse functie is omkeerbaar.
een op een

naar
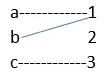
Conclusie
Lineaire Algebra is een subveld van de wiskunde. Het wordt echter breder gebruikt in Machine Learning van notatie tot de implementatie van algoritmen in datasets en afbeeldingen. Met behulp van ML heeft algebra een grotere impact in real-life applicaties zoals zoekmachine-analyse, gezichtsherkenning, voorspellingen, computer graphics, etc.
Aanbevolen artikelen
Dit is een gids voor lineaire algebra in machine learning. Hier bespreken we hoe Lineaire Algebra werkte in Machine Learning met de voordelen en enkele voorbeelden. U kunt ook het volgende artikel bekijken.
- Machine leren van hyperparameter
- Clustering in machine learning
- Data Science Machine Learning
- Machinaal leren zonder toezicht
- Verschil tussen lineaire regressie versus logistieke regressie