

Inleiding tot beslissingsboom in datamining
In de wereld van vandaag over "Big Data" betekent de term "Datamining" dat we naar grote datasets moeten kijken en "mining" op de data moeten uitvoeren en het belangrijke sap of de essentie naar voren moeten brengen van wat de data wil zeggen. Een zeer analoge situatie is die van de mijnbouw waar verschillende gereedschappen nodig zijn om de kolen diep onder de grond te ontginnen. Van de tools in Data mining is 'Decision Tree' een van hen. Datamining op zichzelf is dus een enorm gebied waarin we de komende paragrafen dieper ingaan op de beslissingsboom 'tool' in Data Mining.
Algoritme van beslissingsboom in datamining
Een beslissingsboom is een begeleide leerbenadering waarbij we de aanwezige gegevens trainen met al te weten wat de doelvariabele eigenlijk is. Zoals de naam suggereert, heeft dit algoritme een boomstructuur. Laten we eerst kijken naar het theoretische aspect van de beslissingsboom en daarna hetzelfde onderzoeken in een grafische benadering. In Beslisboom splitst het algoritme de gegevensset op in subsets op basis van het belangrijkste of belangrijkste kenmerk. Het belangrijkste kenmerk wordt in de hoofdknoop aangegeven en dat is waar de splitsing plaatsvindt van de volledige gegevensset in de hoofdknoop. Dit splitsen is bekend als beslissingsknooppunten. In het geval dat splitsen niet meer mogelijk is, wordt dat knooppunt een bladknooppunt genoemd.
Om het algoritme te stoppen om een overweldigend stadium te bereiken, wordt een stopcriterium gebruikt. Een van de stopcriteria is het minimum aantal observaties in het knooppunt voordat de splitsing plaatsvindt. Bij het toepassen van de beslissingsboom bij het splitsen van de gegevensset, moet u oppassen dat veel knooppunten mogelijk alleen lawaaierige gegevens bevatten. Om een uitbijter of lawaaierige dataproblemen op te lossen, gebruiken we technieken die bekend staan als Data Pruning. Gegevenssnoei is niets anders dan een algoritme om gegevens uit de subset te classificeren, waardoor het moeilijk is om van een bepaald model te leren.
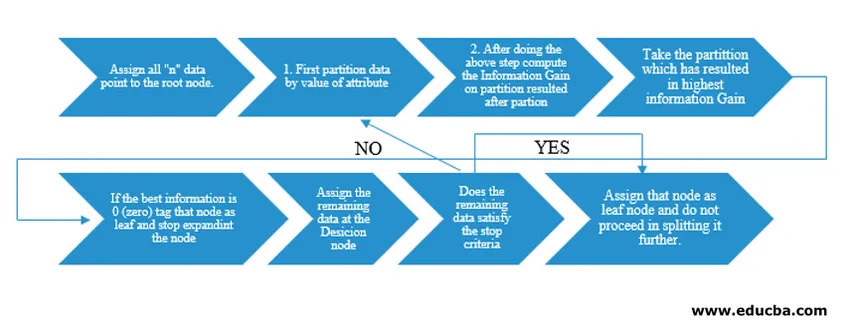
Decision Tree-algoritme is vrijgegeven als ID3 (Iterative Dichotomiser) door machine-onderzoeker J. Ross Quinlan. Later werd C4.5 uitgebracht als de opvolger van ID3. Zowel ID3 als C4.5 zijn een hebzuchtige aanpak. Laten we nu eens kijken naar een stroomdiagram van het Decision Tree-algoritme.
Voor ons pseudocode-begrip zouden we “n” -datapunten nemen die elk “k” -attributen hebben. Onderstaand stroomdiagram is gemaakt rekening houdend met "Informatie Gain" als de voorwaarde voor een splitsing.
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
In plaats van Information Gain (IG) kunnen we ook de Gini-index gebruiken als criteria voor een splitsing. Om het verschil tussen deze twee criteria in termen van leek te begrijpen, kunnen we deze informatieversterking beschouwen als Verschil in entropie vóór de splitsing en na de splitsing (splitsing op basis van alle beschikbare functies).
Entropie is als willekeur en we zouden een punt bereiken na de splitsing om de minste willekeurstatus te hebben. Daarom moet informatiewinst het grootst zijn bij de functie die we willen splitsen. Anders als we willen kiezen om te delen op basis van Gini Index, zouden we de Gini-index vinden voor verschillende attributen en met dezelfde vinden we gewogen Gini-index voor verschillende splitsing en gebruiken we de index met hogere Gini-index om de dataset te splitsen.
Belangrijke beslissingsboom in datamining
Hier zijn enkele van de belangrijke termen van een beslissingsboom in datamining hieronder:
- Rootknoop: dit is de eerste knoop waar het splitsen plaatsvindt.
- Bladknoop: dit is de knoop waarna er geen vertakking meer is.
- Beslissingsknooppunt: het knooppunt dat wordt gevormd na het splitsen van gegevens uit een vorig knooppunt staat bekend als een beslissingsknooppunt.
- Branch: Subsectie van een boom met informatie over de nasleep van de splitsing op het beslissingsknooppunt.
- Snoeien: wanneer er subknopen van een beslissingsknooppunt worden verwijderd om tegemoet te komen aan een uitbijter of lawaaierige gegevens, wordt snoeien genoemd. Er wordt ook gedacht dat dit het tegenovergestelde is van splitsen.
Toepassing van beslissingsboom in datamining
Decision Tree heeft een stroomdiagramtype van architectuur ingebouwd met het type algoritme. Het heeft in wezen een "Als X dan Y anders Z" soort patroon terwijl de splitsing wordt gemaakt. Dit type patroon wordt gebruikt om de menselijke intuïtie in het programmatische veld te begrijpen. Daarom kan men dit uitgebreid gebruiken in verschillende categorisatieproblemen.
- Dit algoritme kan op grote schaal worden gebruikt in het veld waar de objectieve functie verband houdt met de uitgevoerde analyse.
- Wanneer er tal van acties beschikbaar zijn.
- Uitbijteranalyse.
- Inzicht in de belangrijke set functies voor de hele dataset en 'mineer' de paar functies uit een lijst met honderden functies in big data.
- De beste vlucht selecteren om naar een bestemming te reizen.
- Besluitvormingsproces op basis van verschillende omstandigheden.
- Churn-analyse.
- Sentiment analyse.
Voordelen van beslissingsboom
Hier zijn enkele voordelen van de beslissingsboom die hieronder wordt uitgelegd:
- Gemak van begrip: de manier waarop de beslissingsboom wordt weergegeven in zijn grafische vormen maakt het gemakkelijk te begrijpen voor een persoon met een niet-analytische achtergrond. Vooral voor mensen in leiderschap die willen kijken welke functies belangrijk zijn, kan slechts één blik op de beslissingsboom hun hypothese naar voren brengen.
- Data-exploratie: Zoals besproken, is het verkrijgen van significante variabelen een kernfunctionaliteit van de beslissingsboom en met behulp daarvan kan men tijdens data-exploratie achterhalen welke variabele speciale aandacht nodig zou hebben in de loop van de datamining- en modelleringsfase.
- Er is heel weinig menselijk ingrijpen tijdens de voorbereiding van de gegevens en als gevolg van die tijd die wordt verbruikt tijdens de gegevens, wordt de reiniging minder.
- Decision Tree is in staat om zowel categorische als numerieke variabelen te verwerken en biedt ook oplossingen voor classificatieproblemen van meerdere klassen.
- Als onderdeel van de veronderstelling hebben beslissingsbomen geen veronderstelling vanuit een ruimtelijke distributie- en classificatiestructuur.
Conclusie
Ten slotte brengen Besluitbomen een geheel andere klasse van niet-lineariteit met zich mee en spelen ze een rol bij het oplossen van problemen met niet-lineariteit. Dit algoritme is de beste keuze om een beslissingsniveau na te denken over mensen en het in een wiskundig-grafische vorm weer te geven. Het hanteert een top-down benadering bij het bepalen van de resultaten van nieuwe ongeziene gegevens en volgt het principe van verdeel en heers.
Aanbevolen artikelen
Dit is een handleiding voor de beslissingsboom in datamining. Hier bespreken we het algoritme, het belang en de toepassing van de beslissingsboom in datamining, samen met de voordelen ervan. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Data Science Machine Learning
- Soorten gegevensanalysetechnieken
- Beslisboom in R
- Wat is datamining?
- Gids voor verschillende methoden van data-analyse