
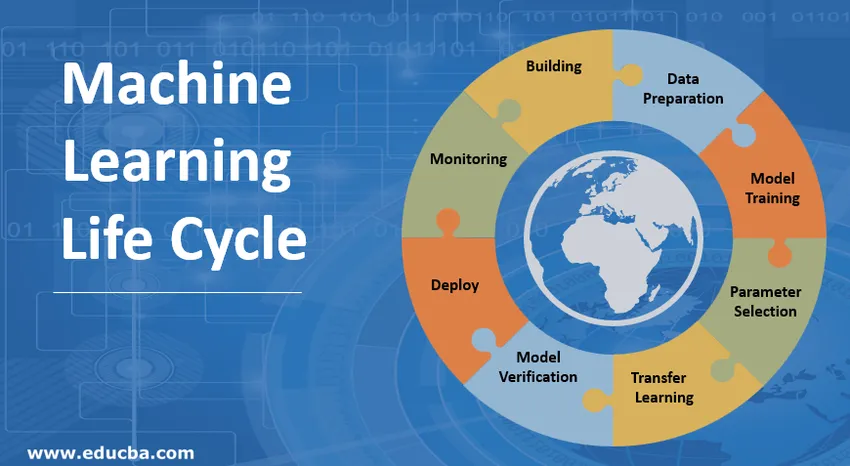
Inleiding tot machine learning (ML) levenscyclus
Machine Learning Life Cycle gaat over het verwerven van kennis door gegevens. De machine learning lifecycle beschrijft een driefasenproces dat door datawetenschappers en data-ingenieurs wordt gebruikt om modellen te ontwikkelen, op te leiden en te bedienen. De ontwikkeling, training en service van machine learning-modellen is het resultaat van een proces dat de machine learning-levenscyclus wordt genoemd. Het is een systeem dat gegevens gebruikt als invoer en dat het vermogen heeft om te leren en te verbeteren met behulp van algoritmen zonder daarvoor te zijn geprogrammeerd. De levenscyclus van machine learning kent drie fasen, zoals weergegeven in de onderstaande afbeelding: ontwikkeling van pijpleidingen, training en inferentie.
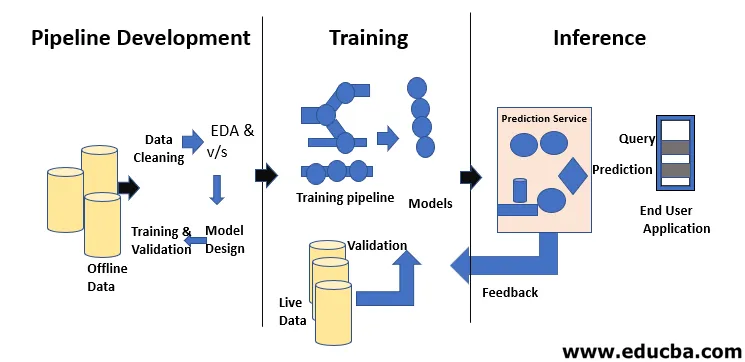
De eerste stap in de levenscyclus van machine learning bestaat uit het transformeren van onbewerkte gegevens in een opgeschoonde gegevensset, die gegevensset wordt vaak gedeeld en hergebruikt. Als een analist of een datawetenschapper problemen ondervindt in de ontvangen gegevens, moeten deze toegang hebben tot de originele gegevens en transformatiescripts. Er zijn verschillende redenen waarom we misschien willen terugkeren naar eerdere versies van onze modellen en gegevens. Als u bijvoorbeeld de eerdere beste versie wilt vinden, moet u mogelijk in veel alternatieve versies zoeken omdat modellen onvermijdelijk achteruitgaan in hun voorspellende kracht. Er zijn veel redenen voor deze verslechtering, zoals een verschuiving in de distributie van gegevens die kan leiden tot een snelle afname van de voorspellende kracht als compensatie voor fouten. Om deze achteruitgang te diagnosticeren, kan het nodig zijn om trainingsgegevens te vergelijken met live gegevens, het model om te scholen, eerdere ontwerpbeslissingen te herzien of zelfs het model opnieuw te ontwerpen.
Leren van fouten
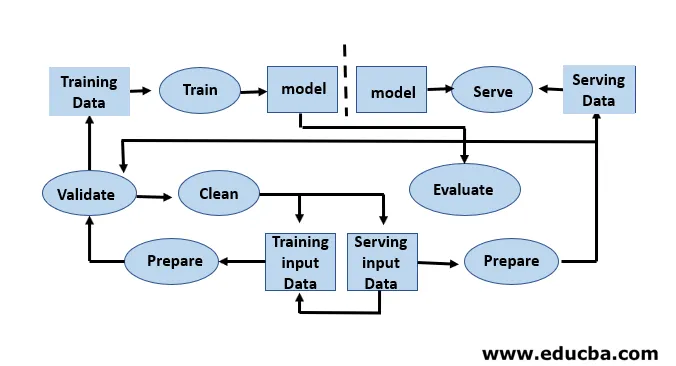
De ontwikkeling van modellen vereist afzonderlijke trainings- en testdatasets. Overmatig gebruik van testgegevens tijdens de training kan leiden tot slechte generalisatie en prestaties, omdat ze kunnen leiden tot overaanpassing. Context speelt hier een cruciale rol, daarom is het noodzakelijk om te begrijpen welke gegevens werden gebruikt om de beoogde modellen te trainen en met welke configuraties. De machine learning-levenscyclus is gegevensgestuurd omdat het model en de output van training is gekoppeld aan de gegevens waarop het is getraind. Een overzicht van een end-to-end machine learning pijplijn met een gegevensperspectief wordt weergegeven in de onderstaande afbeelding:
Stappen betrokken bij de levenscyclus van machine learning
Machine Learning-ontwikkelaar voert voortdurend experimenten uit met nieuwe gegevenssets, modellen, softwarebibliotheken, afstemmingsparameters om de modelnauwkeurigheid te optimaliseren en te verbeteren. Omdat de prestaties van het model volledig afhankelijk zijn van de invoergegevens en het trainingsproces.
1. Het machine learning-model bouwen
Deze stap bepaalt het type model op basis van de toepassing. Het stelt ook vast dat de toepassing van het model in de modelleerfase zodat ze goed kunnen worden ontworpen volgens de behoefte van een beoogde toepassing. Er zijn verschillende modellen voor machinaal leren beschikbaar, zoals het model onder toezicht, het model zonder toezicht, classificatiemodellen, regressiemodellen, clustermodellen en leermodellen voor versterking. Een goed inzicht wordt weergegeven in de onderstaande figuur:
2. Gegevens voorbereiden
Een verscheidenheid aan gegevens kan worden gebruikt als invoer voor machine learning-doeleinden. Deze gegevens kunnen afkomstig zijn van een aantal bronnen, zoals een bedrijf, farmaceutische bedrijven, IoT-apparaten, ondernemingen, banken, ziekenhuizen, enz. Er worden grote hoeveelheden gegevens verstrekt in de leerfase van de machine, aangezien het aantal gegevens toeneemt naar gewenste resultaten opleveren. Deze uitvoergegevens kunnen worden gebruikt voor analyse of worden ingevoerd als invoer in andere machine learning-toepassingen of -systemen waarvoor het als een basis zal fungeren.
3. Modeltraining
In deze fase wordt een model gemaakt op basis van de gegevens die eraan zijn gegeven. In dit stadium wordt een deel van de trainingsgegevens gebruikt om modelparameters te vinden, zoals de coëfficiënten van een polynoom of gewichten in machine learning, wat helpt om de fout voor de gegeven gegevensset te minimaliseren. De resterende gegevens worden vervolgens gebruikt om het model te testen. Deze twee stappen worden over het algemeen een aantal keren herhaald om de prestaties van het model te verbeteren.
4. Parameterselectie
Het omvat de selectie van de parameters die bij de training horen, ook wel de hyperparameters genoemd. Deze parameters bepalen de effectiviteit van het trainingsproces en dus hangt uiteindelijk de prestatie van het model hiervan af. Ze zijn erg belangrijk voor de succesvolle productie van het machine learning-model.
5. Overdracht leren
Omdat er veel voordelen zijn bij het hergebruiken van modellen voor machine learning in verschillende domeinen. Dus, ondanks het feit dat een model niet rechtstreeks tussen verschillende domeinen kan worden overgedragen, wordt het dus gebruikt om een startmateriaal te verschaffen voor het starten van de training van een volgend model. Het vermindert dus de trainingstijd aanzienlijk.
6. Modelverificatie
De input van deze fase is het getrainde model geproduceerd door de modelleerfase en de output is een geverifieerd model dat voldoende informatie biedt om gebruikers te laten bepalen of het model geschikt is voor de beoogde toepassing. Deze fase van de levenscyclus van machine learning houdt zich dus bezig met het feit dat een model goed werkt wanneer het wordt behandeld met ongeziene invoer.
7. Implementeer het machine learning-model
In deze fase van de levenscyclus van Machine learning, passen we ons toe om machine learning-modellen te integreren in processen en applicaties. Het uiteindelijke doel van deze fase is de juiste functionaliteit van het model na implementatie. De modellen moeten zodanig worden ingezet dat ze kunnen worden gebruikt voor inferentie en regelmatig moeten worden bijgewerkt.
8. Monitoring
Het omvat het opnemen van veiligheidsmaatregelen om de goede werking van het model tijdens zijn levensduur te garanderen. Om dit mogelijk te maken zijn goed beheer en updates vereist.
Voordeel van levenscyclus van machine learning
Machine learning biedt de voordelen van kracht, snelheid, efficiëntie en intelligentie door te leren zonder deze expliciet in een applicatie te programmeren. Het biedt kansen voor verbeterde prestaties, productiviteit en robuustheid.
Conclusie - levenscyclus van machine learning
Systemen voor machinaal leren worden met de dag belangrijker, omdat de hoeveelheid gegevens die betrokken is bij verschillende toepassingen snel toeneemt. Machine learning-technologie is het hart van slimme apparaten, huishoudelijke apparaten en online services. Het succes van machine learning kan verder worden uitgebreid tot veiligheidskritieke systemen, gegevensbeheer, high-performance computing, die een groot potentieel biedt voor applicatiedomeinen.
Aanbevolen artikelen
Dit is een gids voor de levenscyclus van machine learning. Hier bespreken we de introductie, leren van fouten, stappen die betrokken zijn bij de levenscyclus van machine learning en voordelen. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie–
- Bedrijven voor kunstmatige intelligentie
- QlikView Set-analyse
- IoT Ecosysteem
- Cassandra-gegevensmodellering