

Wat is XGBoost-algoritme?
XGBoost of de Extreme Gradient boost is een algoritme voor machine learning dat wordt gebruikt voor de implementatie van beslissingsbomen met gradiëntversterking. Waarom beslissingsbomen? Wanneer we het hebben over ongestructureerde gegevens zoals de afbeeldingen, ongestructureerde tekstgegevens, enz., Lijken de ANN-modellen (Kunstmatig neuraal netwerk) bovenaan te staan wanneer we proberen te voorspellen. Terwijl wanneer we het hebben over gestructureerde / semi-gestructureerde gegevens, beslissingsbomen momenteel de beste zijn. XGBoost is in principe ontworpen om de snelheid en prestaties van machine learning-modellen aanzienlijk te verbeteren en diende het doel zeer goed.
Werking van XGBoost-algoritme
De XGBoost heeft een algoritme voor het leren van bomen, evenals het lineaire model leren, en daardoor is het in staat om parallelle berekeningen op de enkele machine uit te voeren.
Dit maakt het XGBoost-algoritme 10 keer sneller dan alle bestaande algoritmen voor het verhogen van de gradiënt.
De XGBoost en de GBM's (di Gradient Boosting Machines) gebruiken boommethodes met behulp van de gradiënt-afdalingsarchitectuur.
Het gebied waar XGBoost de andere GBM's achterlaat, is het gebied van systeemoptimalisatie en verbeteringen ten opzichte van de algoritmen.
Laten we die in detail bekijken:
Systeem optimalisatie:
1. Boom snoeien - Het XGBoost-algoritme gebruikt de diepte-eerste benadering in tegenstelling tot het stopcriterium voor boomsplitsing dat wordt gebruikt door GBMS, dat hebzuchtig van aard is en het hangt ook af van het criterium van negatief verlies. De XGBoost gebruikt in plaats daarvan de functie voor maximale diepte / parameter en snoeit de boom dus in achterwaartse richting.
2. Parallellisatie - Het proces van sequentiële boombouw gebeurt met behulp van de parallelle implementatie in het XGBoost-algoritme. Dit wordt mogelijk gemaakt door de buitenste en binnenste lussen die uitwisselbaar zijn. De buitenste lus geeft de bladknooppunten van een boom weer, terwijl de binnenste lus de kenmerken zal berekenen. Om de buitenste lus te laten starten, moet de binnenste lus ook worden voltooid. Dit schakelproces verbetert de prestaties van het algoritme.
3. Hardware-optimalisatie - Hardware-optimalisatie werd ook overwogen tijdens het ontwerp van het XGBoost-algoritme. Interne buffers worden toegewezen voor elk van de threads om de verloopstatistieken op te slaan.
Algoritmische verbeteringen:
- Bewustzijn van spaarzaamheid - Van XGBoost is bekend dat het zeer efficiënt omgaat met alle verschillende soorten spaarzaamheidspatronen. Dit algoritme leert de ontbrekende waarde van het nest door het trainingsverlies te zien.
- Regularisatie - Om overfitting te voorkomen, corrigeert het complexere modellen door zowel de LASSO (ook wel L1 genoemd) als Ridge-regularisatie (ook wel L2 genoemd) te implementeren.
- Cross-Validation - Het XGBoost-algoritme heeft ingebouwde cross-validatiefuncties die bij elke iteratie bij het maken van het model worden geïmplementeerd. Dit voorkomt dat het aantal benodigde boost-iteraties moet worden berekend.
- Gedistribueerde gewogen kwantiele schets - Het XGBoost-algoritme gebruikt de gedistribueerde gewogen kwantiele schets om het optimale aantal gesplitste punten onder de gewogen gegevenssets te krijgen
Kenmerken van XGBoost
Hoewel XGBoost is ontworpen om de snelheid en prestaties van machine learning-modellen aanzienlijk te verbeteren, biedt het ook een groot aantal geavanceerde functies.
A) Modelkenmerken
De functies zoals die van een sci-kit leren regularisatie en R-taalimplementatie wordt ondersteund door XGBoost. De belangrijkste gradiëntversterkende methoden die worden ondersteund zijn:
- Stochastische gradiëntversterking - Kolommen, rijen en kolommen per gesplitste niveaus kunnen worden gesampled.
- Gradient Boosting
- Regularized Gradient Boosting - De XGBoost corrigeert complexere modellen door zowel de LASSO (ook wel L1 genoemd) als Ridge-regularisatie (ook wel L2 genoemd) te implementeren.
B) Systeemfuncties
De systeemfuncties omvatten:
1. Distributed Computing - Deze functie wordt gebruikt voor het trainen van zeer grote modellen door een cluster van machines te implementeren.
2. Parallellisatie - Tijdens de training worden alle CPU-kernen gebruikt voor parallellisatie van de boomconstructie
3. Cache-optimalisatie - De algoritmen en gegevensstructuren worden in de cache opgeslagen om de hardware optimaal te gebruiken.
4. Out of the Core Computing - Voor de datasets die niet in het geheugen passen, impliceert de XGBoost de core computing.
C) Algoritmefuncties
Een van de belangrijkste doelen van het XGBoost-algoritme was om optimaal gebruik te maken van alle beschikbare bronnen. Enkele van de belangrijkste algoritmische kenmerken van de XGBoost zijn:
- Blokstructuur - Deze functie wordt gebruikt om boomconstructie in parallellisatie te ondersteunen.
- Sparse Aware - Wanneer de waarden in de gegevensset ontbreken, zorgt deze functie er automatisch voor.
- Voortgezette training - Wanneer het model klaar is met de nieuwe gegevens, kan het model verder worden verbeterd met behulp van deze functie.
Waarom XGBoost gebruiken?
Het belangrijkste doel dat XGBoost dient zijn:
- Snelheid van uitvoering
- Modelprestaties
Laten we ze allebei bespreken.
1. Executiesnelheid
Wanneer we XGBoost vergelijken met andere gradiëntversterkende algoritmen, blijkt XGBoost echt snel te zijn, ongeveer 10 keer sneller dan andere implementaties.
Szilard Pafka voerde enkele experimenten uit die bedoeld waren om de uitvoeringssnelheid van verschillende algoritmen voor willekeurige bosimplementatie te evalueren. Hieronder is een momentopname van de resultaten van het experiment:
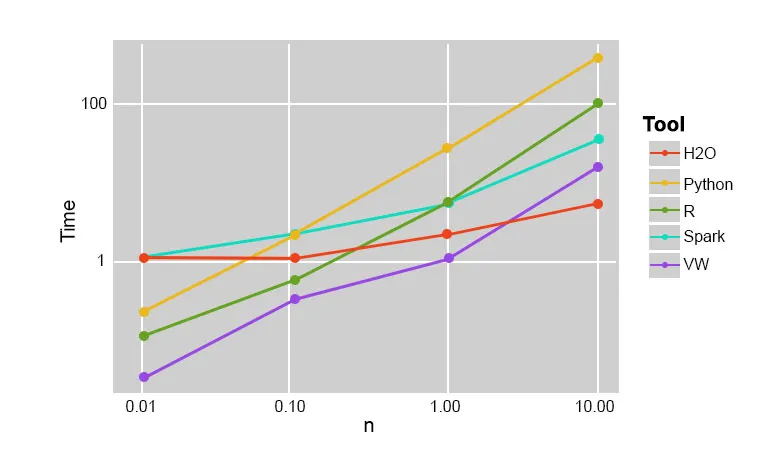
Het bleek dat XGBoost de snelste was. Meer lezen vind je hier
2. Modelprestaties
Wanneer we het hebben over ongestructureerde gegevens zoals de afbeeldingen, ongestructureerde tekstgegevens, enz., Lijken de ANN-modellen (Kunstmatig neuraal netwerk) bovenaan te staan wanneer we proberen te voorspellen. Terwijl wanneer we het hebben over gestructureerde / semi-gestructureerde gegevens, beslissingsbomen momenteel de beste zijn en wanneer geïmplementeerd met behulp van de XGBoost, kan geen ander stimuleringsalgoritme dit nu verslaan.
Het algoritme dat wordt gebruikt door XGboost
Het XGBoost-algoritme maakt gebruik van het algoritme voor het nemen van een beslissingsboom met gradiëntversterking.
De methode voor het verhogen van de gradiënt creëert nieuwe modellen die de taak van het voorspellen van de fouten en de residuen van alle eerdere modellen doen, die vervolgens op hun beurt worden opgeteld en vervolgens de definitieve voorspelling wordt gedaan.
Conclusie: XGBoost-algoritme
In dit XGBoost-algoritme hebben we kennis gemaakt met het XGBoost-algoritme dat wordt gebruikt voor machine learning. Toen zagen we de werking van dit algoritme, de belangrijkste functies ervan en waarom het een perfecte keuze is voor het implementeren van beslissingsbomen met gradiëntverhogende factoren.
Aanbevolen artikelen
Dit is een gids voor XGBoost-algoritme geweest. Hier hebben we het concept, functies, gebruik voor machinaal leren, werken van een algoritme in XGBoost besproken. U kunt ook de volgende artikelen bekijken voor meer informatie -
- NLP in Python
- Ray Tracing Algorithm
- Algoritme voor digitale handtekeningen
- Vragen tijdens solliciteren bij Algorithm
- Digitale handtekeningcryptografie