

Verschil tussen Apache Nifi en Apache Spark
Tot een lange tijd, toen er een zwaar werk moest worden voltooid, vertrouwden mensen op paarden voor het trekken van zware lasten, snelheid handhaven of iets daartussenin. Niet alle paarden waren echter geschikt voor elke taak. Hetzelfde is tegenwoordig het geval met technologie. Met de komst van nieuwe technologieën die elke dag binnenstromen, wordt het uiterst belangrijk om hun echte toepassingen te kennen. Twee van dergelijke technologieën zijn Apache Nifi en Apache Spark en we gaan ze in dit bericht bestuderen.
Apache Spark is een open source framework voor cluster computing dat als doel heeft een interface te bieden voor het programmeren van een hele reeks clusters met impliciete fouttolerantie en gegevensparallelliteit. Het maakt gebruik van RDD's (Resilient Distributed Datasets) en verwerkt de gegevens in de vorm van Discretized Streams die verder worden gebruikt voor analytische doeleinden.
Apache Nifi (de korte vorm van NiagaraFiles) is een ander softwareproject dat tot doel heeft de gegevensstroom tussen softwaresystemen te automatiseren. Het ontwerp is gebaseerd op een op flow gebaseerd programmeermodel dat functies biedt zoals werken met clusters. Het is een gemakkelijk te gebruiken, betrouwbaar en krachtig systeem om gegevens te verwerken en te verspreiden. Het ondersteunt schaalbare gerichte grafieken voor gegevensroutering, systeembemiddeling en transformatielogica. Laten we de vergelijkingen van beide onderwerpen bespreken.
Head-to-head vergelijking tussen Apache Nifi vs Apache Spark (Infographics)
Hieronder staat de top 9 vergelijking tussen Apache Nifi vs Apache Spark
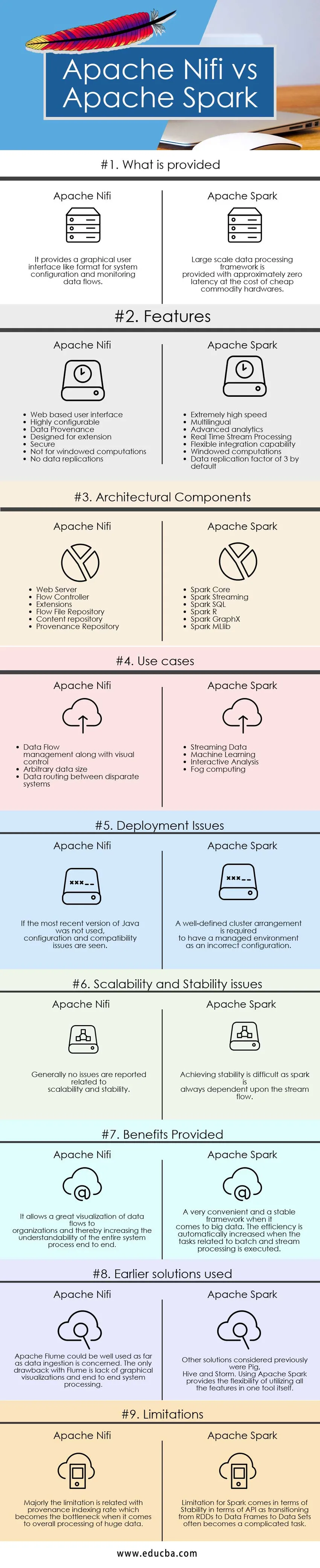
Belangrijkste verschillen tussen Apache Nifi versus Apache Spark
De verschillen tussen Apache Nifi en Apache Spark worden uitgelegd in de onderstaande punten:
- Apache Nifi is een tool voor het opnemen van gegevens die wordt gebruikt om een gebruiksvriendelijk, krachtig en betrouwbaar systeem te leveren zodat de verwerking en distributie van gegevens over bronnen eenvoudig wordt, terwijl Apache Spark een extreem snelle clustercomputertechnologie is die is ontworpen voor snellere berekening door efficiënt gebruik makend van interactieve vragen, in geheugenbeheer en stroomverwerkingsmogelijkheden.
- Apache Nifi werkt in zelfstandige modus en een clustermodus, terwijl Apache Spark goed werkt in lokale of de zelfstandige modus, Mesos, Yarn en andere soorten big data-clustermodi.
- Kenmerken van Apache Nifi omvatten gegarandeerde levering van gegevens, efficiënte gegevensbuffering, Prioritaire wachtrijen, Flow-specifieke QoS, Data Provenance, Roll buffer herstel, visuele opdracht en controle, Flow-sjablonen, Beveiliging, Parallel Streaming-mogelijkheden, terwijl functies van Apache Spark bliksemsnel zijn snelheid verwerkingscapaciteit, Meertalig, In-memory computing, efficiënt gebruik van commodity hardwaresystemen, Advanced Analytics, Efficiënte integratiemogelijkheden.
- Apache Nifi zorgt voor een betere leesbaarheid en algeheel begrip van het systeem door visualisatiemogelijkheden en drag & drop-functies te bieden. De gegevensstroom kan eenvoudig worden beheerd en bestuurd met behulp van conventionele technieken en processen, terwijl in het geval van Apache Spark om dit soort visualisaties te bekijken een clusterbeheersysteem zoals Ambari nodig is. Apache Spark biedt op zichzelf geen visualisatiemogelijkheden en is alleen goed voor zover het programmeren betreft. Het is veruit een erg handig en stabiel systeem voor het verwerken van grote hoeveelheden gegevens.
- De beperking met Apache Nifi hangt samen met wat het voordeel ervan is. De enige drag & drop-functie biedt een beperking van het niet kunnen schalen en robuustheid bieden als het gaat om de integratie met andere componenten en tools, terwijl in het geval van Apache Spark de primaire beperking gepaard gaat met het gebruik van uitgebreide basishardware en het beheer ervan wordt soms een vervelende taak. De andere gerapporteerde beperking komt samen met zijn streamingmogelijkheden met betrekking tot Discretized Stream en Windowed of batchstream waarbij de transformatie van RDD's naar dataframe en datasets soms een oorzaak is van instabiliteit.
Vergelijkingstabel Apache Nifi vs Apache Spark
| Vergelijkingsbasis | Apache Nifi | Apache Spark |
| Wat is er voorzien? | Het biedt een grafische gebruikersinterface zoals een indeling voor systeemconfiguratie en monitoring van gegevensstromen. | Grootschalig gegevensverwerkingsraamwerk wordt geleverd met ongeveer nul latentie ten koste van goedkope grondstoffenhardware. |
| Kenmerken |
|
|
| Bouwkundige componenten |
|
|
| Gebruik cases |
|
|
| Implementatieproblemen | Als de meest recente versie van Java niet is gebruikt, treden configuratie- en compatibiliteitsproblemen op | Een goed gedefinieerde clusterindeling is vereist om een beheerde omgeving als een onjuiste configuratie te hebben |
| Schaalbaarheid en stabiliteitsproblemen | Over het algemeen worden geen problemen gemeld met betrekking tot schaalbaarheid en stabiliteit | Het bereiken van stabiliteit is moeilijk omdat een vonk altijd afhankelijk is van de stroom van de stroom. |
| Voordelen geboden | Het maakt een geweldige visualisatie van datastromen naar organisaties mogelijk en verhoogt daarmee de begrijpelijkheid van het volledige systeemproces | Een erg handig en stabiel framework als het gaat om big data. De efficiëntie wordt automatisch verhoogd wanneer de taken met betrekking tot batch- en streamverwerking worden uitgevoerd. |
| Eerder gebruikte oplossingen | Apache Flume kan goed worden gebruikt voor zover het gegevensinname betreft. Het enige nadeel van Flume is het ontbreken van grafische visualisaties en end-to-end-systeemverwerking | Andere oplossingen die eerder werden overwogen, waren Pig, Hive en Storm. Het gebruik van Apache Spark biedt de flexibiliteit om alle functies in één tool zelf te gebruiken. |
| beperkingen | De beperking houdt vooral verband met de indexering van de herkomst, die de bottleneck wordt als het gaat om de algehele verwerking van enorme gegevens | Beperking voor Spark komt in termen van stabiliteit in termen van API, omdat de overgang van RDD's naar gegevenskaders naar gegevenssets vaak een ingewikkelde taak wordt. |
Conclusie - Apache Nifi vs Apache Spark
Om het bericht af te ronden, kan worden gezegd dat Apache Spark een zwaar warhorse is, terwijl Apache Nifi een behendig renpaard is. Beide hebben hun eigen voordelen en beperkingen voor gebruik in hun respectieve gebieden. U moet de juiste tool voor uw bedrijf kiezen. Blijf op de hoogte van onze blog voor meer artikelen over nieuwere technologieën voor big data.
Aanbevolen artikel
Dit is een gids geweest voor Apache Nifi versus Apache Spark, hun betekenis, vergelijking van persoon tot persoon, belangrijkste verschillen, vergelijkingstabel en conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Apache Hadoop vs Apache Spark | Top 10 vergelijkingen die u moet weten!
- Apache Storm vs Apache Spark - Leer 15 nuttige verschillen
- 7 Belangrijke dingen over Apache Spark (gids)
- De beste 15 dingen die u moet weten over Map Reduce vs Spark