

Inleiding tot bijenkorfinstallatie
In Hive installatie moeten er enkele voorwaarden worden gedaan voordat u gaat installeren.
Hadoop-componenten zoals Hive, Hbase, Pig, enz. Ondersteunen allemaal de Linux-omgeving. Daarom wordt aanbevolen om een Linux-besturingssysteem op uw apparaat te hebben. Als dit niet het geval is en u wilt oefenen op bijenkorf terwijl Windows op uw systeem staat. Wat u kunt doen, is de CDH-machine op uw systeem installeren en gebruiken als een platform om Hadoop te verkennen. Dit vereist minimaal 4 GB RAM op uw systeem of u kunt een CDH-machine in uw pen drive hebben en deze gebruiken.
Hoe dan ook, u kunt altijd een oplossing voor uw vraag hebben die misschien eerder dan later is.
Vereisten om Hive te installeren
Er zijn enkele vereisten om bijenkorf op elke machine te installeren:
- Java-installatie
- Hadoop-installatie
Stap 1
- Controleer of Java is geïnstalleerd.
- Open de terminal en typ de opdracht.
Java-versie
- Als Java op het systeem is geïnstalleerd, krijgt u de versie of anders een foutmelding. In mijn geval is Java al geïnstalleerd en hieronder staat de uitvoer van de opdracht.

- In het geval dat Java niet op uw systeem is geïnstalleerd. U kunt de onderstaande link bezoeken en Java downloaden en installeren.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Java-installatie
- Pak het gedownloade uit.
- Verplaats het naar "/ usr / local /".
- Stel de variabelen PATH en JAVA_HOME in.
Stap 2
- Controleer of Hadoop is geïnstalleerd.
- Open de terminal en typ de opdracht.
Hadoop-Version
- Als Hadoop al is geïnstalleerd, geeft dit commando je de versie of anders een foutmelding.
- In mijn geval heeft Hadoop de onderstaande uitvoer al geïnstalleerd.
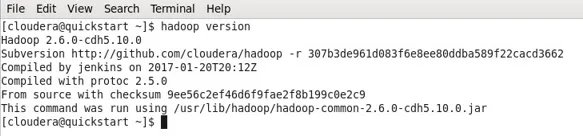
- Je kunt nu zien dat ik met een CDH5-machine werk.
- Als Hadoop niet is geïnstalleerd, downloadt u de Hadoop van Apache-softwarestichting.
Hadoop-installatie
1. Stel Hadoop in
2. Configureer Hadoop
Bestanden die moeten worden bewerkt om Hadoop te configureren zijn:
- kern-site.xml
- HDFS-site.xml
- garen-site.xml
- mapred-site.xml
3. Stel Namenode in met behulp van de opdracht:
Hdfs namenode -format
4. Start dfs met de volgende opdracht:
start -dfs.sh
5. Start garen met het commando:
Start -yarn.sh
Hoe bijenkorf te installeren?
Hieronder helpen de punten om bijenkorf te installeren:
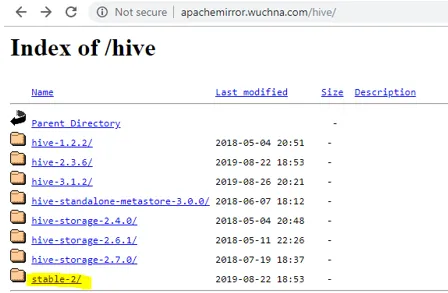
- Het eerste wat we moeten doen is de bijenkorfrelease downloaden die kan worden uitgevoerd door op de onderstaande link te klikken: http://apachemirror.wuchna.com/hive/
- Bovenstaande link geeft de link waaruit u stabiel-2 moet kiezen, hieronder geel gemarkeerd:
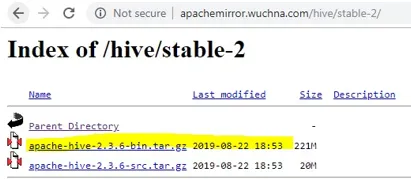
- Na het openen van stabiel-2, kies het bin-bestand (geel gemarkeerd in de screenshot) en klik met de rechtermuisknop en "linkadres kopiëren".
Stappen om Hive te installeren
Hieronder zijn de stappen om bijenkorf te installeren:
Stap 1: Download het tar-bestand.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Stap 2: pak het bestand uit.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Stap 3: Verplaats apache-bestanden naar de map / usr / local / hive.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Stap 4: Stel de Hive-omgeving in door de volgende regels toe te voegen aan het bestand ~ / .bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Stap 5: Voer het bashrc-bestand uit.
$ source ~/.bashrc
Stap 6: Hive Configuration- Bewerk het bestand hive-env.sh om dit toe te voegen:
export HADOOP_HOME=/usr/local/Hadoop
Stap 7: Bewerk met behulp van de onderstaande opdrachten:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Gebruik nu de opdracht hive-versie om te controleren of de component is geïnstalleerd of niet.
- Hier komt de bijenkorfversie in de bijenkorf, wat betekent dat de bijenkorf is geïnstalleerd. In mijn geval is het echter de oudere versie die de waarschuwing geeft.

Conclusie - Bijenkorfinstallatie
Hive opent de big data voor veel mensen vanwege het gemak en de vergelijkbare aard van SQL zoals querytaal en interfaces. Hive is gebouwd op Hadoop-kern omdat het Mapreduce gebruikt voor uitvoering. Veel gemakkelijk om de gegevens op te halen en Big Data te verwerken.
Aanbevolen artikelen
Dit is een handleiding voor Hive-installatie. Hier bespreken we enkele vereisten om bijenkorf op elke machine te installeren en hoe bijenkorf in stappen te installeren voor een beter begrip. U kunt ook onze andere gerelateerde artikelen doornemen voor meer informatie-
- Wat is een bijenkorf?
- Hive Commands
- Hoe Hive te installeren
- Wat is varken?