

Wat is AWS Kinesis?
Kinesis is een platform dat helpt bij het verzamelen, verwerken en analyseren van streaminggegevens in Amazon Web Services. Streaming data is een grote hoeveelheid data die voortkomt uit verschillende bronnen zoals sociale media, IoT-sensoren, weersvoorspelling, gezondheidszorg, enz. Deze worden gebruikt bij het bouwen van applicaties op basis van gebruikersbehoeften. Enkele veel voorkomende toepassingen zijn voorspellende analyses in Big Data, Machine Learning, enz. In dit onderwerp gaan we meer te weten over AWS Kinesis.
AWS Kinesis Services
Voordat we naar de services gaan, moeten we eerst enkele terminologieën begrijpen die in Kinesis worden gebruikt.
Terminologie
| Termijn | Definitie |
| Gegevensrecord | Gegevenseenheid opgeslagen in de gegevensstroom van Kinesis. Het bestaat uit een data-blob, een volgnummer en een partitiesleutel |
| Scherf | Set van de reeks gegevensrecords. Het aantal scherven kan worden verhoogd of verlaagd als de gegevenssnelheid wordt verhoogd. |
| Bewaartermijn | De tijdsperiode waarin toegang tot de gegevens kan worden verkregen nadat ze aan de stream zijn toegevoegd.
Standaardbewaarperiode: 24 uur |
| Producent | Het feds gegevensrecords in Kinesis Stream |
| Klant | Het haalt records op van Kinesis Stream en verwerkt ze. |
Kinesis biedt 3 kerndiensten. Zij zijn:
1. Kinesis-stromen
Kinesis Stream bestaat uit een reeks gegevensrecords, Shards genaamd. Deze scherven hebben een vaste capaciteit die een maximale leessnelheid van 2 MB / seconde en een schrijfsnelheid van 1 MB / seconde kan bieden. De maximale capaciteit van een stream is de som van de capaciteit van elke scherf.
Werken van Kinesis:
- Gegevens geproduceerd door IoT en andere bronnen die bekend staan als Producers worden ingevoerd in de Kinesis Streams voor opslag in Shards.
- Deze gegevens zijn maximaal 24 uur beschikbaar in Shard.
- Als het langer dan deze standaardtijd moet worden opgeslagen, kan de gebruiker een bewaarperiode van 7 dagen gebruiken.
- Zodra de gegevens de scherven bereiken, kunnen EC2-instanties deze gegevens voor verschillende doeleinden gebruiken.
- EC2-instanties die gegevens ophalen, staan bekend als consumenten.
- Na de verwerking van gegevens worden deze ingevoerd in een van de Amazon Web Services zoals Simple Storage Service (S3), DynamoDB, Redshift, etc.
2. Kinesis-brandslang
Kinesis Firehose is nuttig bij het verplaatsen van gegevens naar Amazon-webservices zoals Redshift, Simple storage-service, Elastic Search, enz. Het is een onderdeel van het streamingplatform dat geen bronnen beheert. Gegevensproducenten zijn zo geconfigureerd dat gegevens naar Kinesis Firehose moeten worden verzonden en vervolgens automatisch naar de overeenkomstige bestemming worden verzonden.
Werken van Kinesis Firehose:
- Zoals vermeld in de werking van AWS Kinesis Streams, ontvangt Kinesis Firehose ook gegevens van producenten zoals mobiele telefoons, laptops, EC2, enz. Maar dit hoeft geen gegevens mee te nemen naar scherven of bewaartermijnen zoals Kinesis Streams te verhogen. Dit komt omdat Kinesis Firehose dit automatisch doet.
- De gegevens worden vervolgens automatisch geanalyseerd en ingevoerd in Simple Storage Service
- Aangezien er geen bewaarperiode is, moeten gegevens worden geanalyseerd of naar een willekeurige opslag worden verzonden, afhankelijk van de behoefte van de gebruiker.
- Als gegevens naar Redshift moeten worden verzonden, moeten deze eerst naar Simple Storage Service worden verplaatst en vanaf daar naar Redshift worden gekopieerd.
- Maar in het geval van Elastic Search kunnen gegevens er direct in worden ingevoerd, vergelijkbaar met Simple Storage Service.
3. Kinesis Analytics
Kinesis Firehose laat toe de SQL-query's uit te voeren in de gegevens die aanwezig zijn in Kinesis Firehose. Met behulp van deze SQL-query's kunnen gegevens worden opgeslagen in Redshift, Simple Storage Service, ElasticSearch, etc.
AWS Kinesis-architectuur
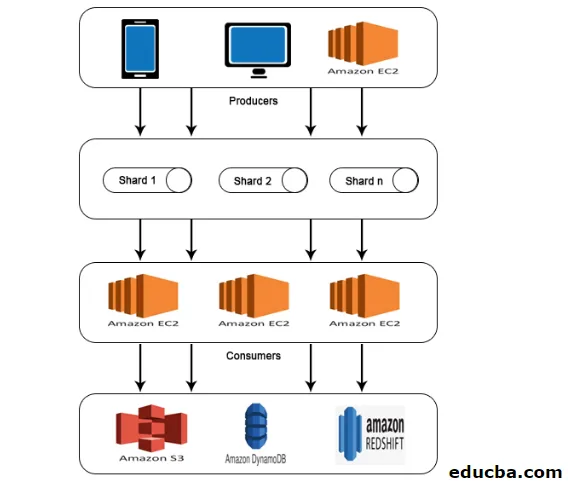
AWS Kinesis Architecture bestaat uit
- producenten
- shards
- Verbruikers
- opslagruimte
Vergelijkbaar met de werking die wordt uitgelegd in AWS Kinesis-gegevensstroom, worden gegevens van producenten ingevoerd in Shards waar gegevens worden verwerkt en geanalyseerd. De geanalyseerde gegevens worden vervolgens verplaatst naar EC2-instanties voor het uitvoeren van bepaalde toepassingen. Eindelijk zullen gegevens worden opgeslagen in een van de Amazon-webservices zoals S3, Redshift, enz.
Hoe AWS kinesis te gebruiken?
Om met AWS Kinesis te werken, moeten de volgende twee stappen worden uitgevoerd.
1. Installeer de AWS-opdrachtregelinterface (CLI).
Het installeren van de opdrachtregelinterface is anders voor verschillende besturingssystemen. Installeer daarom CLI op basis van uw besturingssysteem.
Voor Linux-gebruikers gebruikt u de opdracht sudo pip install AWS CLI
Zorg ervoor dat je een python-versie 2.6.5 of hoger hebt. Na het downloaden configureert u het met de opdracht AWS configure. Vervolgens worden de volgende details gevraagd zoals hieronder weergegeven.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Voor Windows-gebruikers, download het juiste MSI-installatieprogramma en voer het uit.
2. Voer Kinesis-bewerkingen uit met CLI
Houd er rekening mee dat Kinesis-gegevensstromen niet beschikbaar zijn voor AWS free tier. Dus, gemaakte Kinesis-streams worden in rekening gebracht.
Laten we nu enkele kinesis-bewerkingen in CLI bekijken.
- Maak een stream
Maak een stream KStream met Shard count 2 met de volgende opdracht.
aws kinesis create-stream --stream-name KStream --shard-count 2
Controleer of de stream is gemaakt.
aws kinesis describe-stream --stream-name KStream
Als het is gemaakt, is er een uitvoer vergelijkbaar met het volgende voorbeeld verschenen.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Zet record
Nu kan een gegevensrecord worden ingevoegd met de opdracht put-record. Hier wordt een record met een gegevenstest in de stream ingevoegd.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Als het invoegen is gelukt, wordt de uitvoer weergegeven zoals hieronder wordt getoond.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Get Record
Eerst moet de gebruiker de scherf-iterator ophalen die de positie van de stream voor de scherf vertegenwoordigt.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Voer vervolgens het commando uit met behulp van de verkregen scherfiterator.
aws kinesis get-records --shard-iterator ###########
Een voorbeelduitvoer wordt verkregen zoals hieronder weergegeven.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Schoonmaken
Om kosten te voorkomen, kan de gecreëerde stream worden verwijderd met behulp van de onderstaande opdracht.
aws kinesis delete-stream --stream-name KStream
Conclusie
AWS Kinesis is een platform dat streaming-gegevens verzamelt, verwerkt en analyseert voor verschillende toepassingen zoals machine learning, voorspellende analyse enzovoort. Streaminggegevens kunnen elk formaat hebben, zoals audio, video, sensorgegevens, enz.
Aanbevolen artikelen
Dit is een gids voor AWS Kinesis. Hier bespreken we hoe AWS Kinesis te gebruiken en ook de service met werken en architectuur. U kunt ook het volgende artikel bekijken voor meer informatie -
- AWS-architectuur
- Wat is AWS Lambda?
- Big Data-technologieën
- Datamining-architectuur
- AWS-opslagdiensten
- Handleiding voor concurrenten van AWS met functies