

Wat is datamining?
Voordat we dataminingconcepten en -technieken begrijpen, zullen we eerst datamining bestuderen. Datamining is een kenmerk van de conversie van gegevens naar bepaalde goed geïnformeerde informatie. Dit verwijst naar het proces van het verkrijgen van nieuwe informatie door te kijken naar een grote hoeveelheid beschikbare gegevens. Met behulp van verschillende technieken en hulpmiddelen kan men voorspellen welke informatie uit de gegevens vereist is, alleen als de gevolgde procedure correct is. Dit is nuttig in verschillende industrieën om wat vereiste informatie voor toekomstige analyse te extraheren door enkele patronen in de bestaande gegevens in databases, datawarehouses, enz. Te herkennen.
Typen gegevens in datamining
Hieronder volgen de soorten gegevens waarop datamining kan worden uitgevoerd:
- Relationele databases
- Data warehouses
- Geavanceerde DB- en informatie-opslagplaatsen
- Object-georiënteerde en object-relationele databases
- Transactionele en ruimtelijke databases
- Heterogene en oudere databases
- Multimedia- en streamingdatabase
- Tekstdatabases
- Text mining en Web mining
Datamining-proces
Hieronder staan de punten voor datamining-proces:
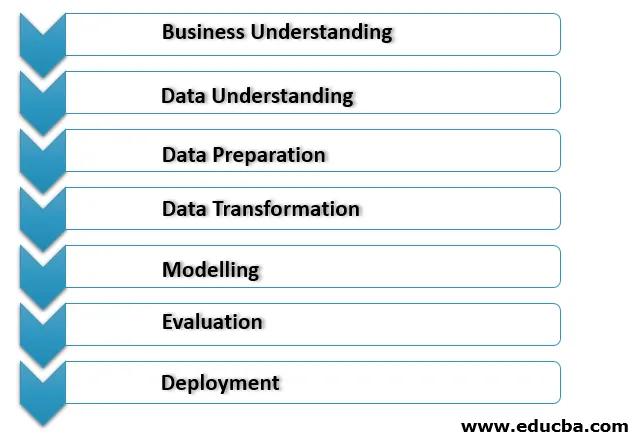
1. Zakelijk begrip
Dit is de eerste fase van het implementatieproces van datamining waar alle behoeften en de zakelijke doelstelling van de klant duidelijk worden begrepen. Juiste dataminingdoelen worden vastgesteld rekening houdend met het huidige scenario in het bedrijf en andere factoren zoals middelen, aannames, beperkingen. Een goed dataminingplan moet gedetailleerd zijn en moet voldoen aan onze bedrijfs- en dataminingdoelen.
2. Inzicht in gegevens
Deze fase fungeert als een sanity check van de gegevens die zijn verzameld uit verschillende bronnen voor dataminingprocessen. Eerst worden alle gegevens uit de verschillende bronnen verzameld met betrekking tot het bedrijfsscenario van de organisatie dat zich in de verschillende database, platte bestanden, enz. Kan bevinden De verzamelde gegevens worden gecontroleerd of ze correct overeenkomen, omdat ze onbetrouwbaar kunnen zijn.
Soms moeten metagegevens ook worden gecontroleerd om de fouten in de dataminingprocessen te verminderen. Verschillende datamining-vragen worden gebruikt voor de analyse van correcte gegevens en op basis van de resultaten kan de gegevenskwaliteit worden gecontroleerd. Het helpt ook om te analyseren of er gegevens ontbreken of niet.
3. Gegevens voorbereiden
Dit proces verbruikt de maximale tijd van het project. Dit gezicht omvat een proces dat gegevensopschoning wordt genoemd om de gegevens op te schonen die tijdens het gegevensinzichtproces zijn verzameld. Het proces voor het opschonen van gegevens wordt gebruikt om de gegevens op te schonen om onjuiste gegevens met ruis uit te sluiten voor de gegevens met ontbrekende waarden.
4. Datatransformatie
In de volgende toestand worden datatransformatiebewerkingen uitgevoerd die worden gebruikt om de gegevens te wijzigen om ze bruikbaar te maken voor het implementatieproces van datamining. Hier transformatie zoals aggregatie, generalisaties, normalisatie of attribuutconstructie om de gegevens gereed te maken voor het gegevensmodelleringsproces.
5. Modellering
Dit is de fase in datamining waarbij de juiste techniek wordt gebruikt om de datapatronen te bepalen. Het verschillende scenario moet worden gecreëerd om de kwaliteit en validiteit van dit model te controleren en om te bepalen of de doelstellingen die zijn gedefinieerd in het proces van bedrijfsinzicht worden bereikt na implementatie van die technieken. Het patroon dat in dit proces is gevonden, wordt verder geëvalueerd en wordt voor implementatie naar het bedrijfsteam gestuurd, zodat dit kan helpen het bedrijfsbeleid van organisaties te verbeteren.
6. Evaluatie
In deze fase wordt de juiste evaluatie van de ontdekkingen van datamining gedaan om de implementatie in de bedrijfsprocessen te verbeteren. Een goede vergelijking wordt gemaakt met de ontdekkingen en het bestaande bedrijfsplan om de verandering goed te evalueren voor de gevonden informatie moet worden toegevoegd aan de huidige bedrijfsvoering.
7. Implementatie
In deze fase wordt de informatie die is afgesloten met behulp van datamining-processen getransformeerd in een begrijpelijke vorm voor niet-technische belanghebbenden. Voor dit proces wordt een correct implementatieplan gemaakt dat verzending, onderhoud en monitoring van de gevonden informatie omvat. Op deze manier wordt een goed projectrapport gemaakt, samen met de ervaringen en de lessen die zijn geleerd tijdens het proces om onze ontdekkingen over datamining over te dragen aan het operationele team.
Daarom helpt dit proces om het bedrijfsbeleid van een organisatie te verbeteren.
Dataminingstechnieken
Onderstaande technieken en technologieën kunnen helpen om datamining-functie op de meest efficiënte manier toe te passen:
1. Volg de patronen
Het herkennen van de patronen in uw dataset is een van de basistechnieken in datamining. De gegevens worden met regelmatige tussenpozen geobserveerd om enige afwijking te herkennen. Het kan bijvoorbeeld worden gezien als een bepaalde persoon door verschillende landen reist, dan moet die persoon regelmatig tickets boeken, dus een speciale creditcard kan worden aangeboden.
2. Classificatie
Het is een van de complexe technieken voor datamining waarbij we verschillende waarneembare categorieën moeten maken met behulp van verschillende attributen in de bestaande data. Deze categorieën helpen om verschillende conclusies te trekken voor ons toekomstige gebruik. Bij het analyseren van de gegevens voor verkeer in de stad kan het verkeer in het gebied bijvoorbeeld worden geclassificeerd als laag, gemiddeld en zwaar. Dit zal de reizigers helpen om het verkeer voor tijd te voorspellen.
3. Vereniging
Deze techniek is vergelijkbaar met de patroonvolgtechniek, maar hier is deze gerelateerd aan de afhankelijk gekoppelde variabelen. Dat betekent dat het patroon voor de gerelateerde gegevens wordt gevonden dat is gekoppeld aan de bestaande gegevens. Gebeurtenis gerelateerd aan de andere gebeurtenis wordt gevolgd en de specifieke patronen worden in die gegevens gevonden. Bestands-trackinggegevens voor het verkeer in een bepaalde stad kunnen bijvoorbeeld ook de meest bezochte plaatsen in een stad volgen. Dit kan ook helpen om bekende plaatsen in de stad te bezoeken.
4. Uitbijterdetectie
Deze techniek houdt verband met het extraheren van afwijkingen in het gegevenspatroon. Bijvoorbeeld, de verkoop van een winkelcentrum maakt een goede winst over de 11 maanden van het jaar, maar in de laatste maand daalde de verkoop zoveel dat dit leidt tot verlies. In deze gevallen moeten we uitzoeken wat de oorzaak was van de vermindering van de omzet, zodat we deze de volgende keer kunnen vermijden. De techniek om een dergelijke afleiding in het reguliere patroon te vinden, maakt deel uit van de detectietechniek van Outlier.
5. Clustering
Deze techniek is vergelijkbaar met classificatie, alleen het verschil ligt in het feit dat het de groep gegevens kiest die enkele overeenkomsten hebben, waardoor ze in een enkele groep worden geplaatst. Bijvoorbeeld, het clusteren van verschillende doelgroepen van een bioscoop op basis van frequentie dat hoe vaak ze voor shows komen, voor welke timing ze het vaakst komen en voor welk filmgenre ze komen.
6. Regressie
Deze techniek helpt om de relatie te tekenen tussen de 2 variabelen waarop een analyse kan afhangen. Hier proberen we het patroon van verandering in de variabele te achterhalen door de andere afhankelijke variabelen te fixeren. Als we bijvoorbeeld het patroon in de verkoop van een product in een winkelcentrum moeten vinden, afhankelijk van de beschikbaarheid, het seizoen, de vraag, enz. Dit kan ertoe leiden dat de eigenaar de prijs bepaalt voor de verkoop ervan.
7. Voorspelling
Het belangrijkste kenmerk van datamining is het verminderen van toekomstige risico's en het vergroten van de winst van de organisatie door het bestuderen van bestaande en historische patronen voor verkoop- en kredietrisico's. Hier helpt dit type technologie ons om toekomstige beslissingen te nemen, afhankelijk van het patroon in historische en huidige gegevens en rekening houdend met veranderingen in de markt en risico's. Deze techniek is het meest nuttig voor datamining.
Datamining Tools
Je hebt niet de nieuwste technologieën nodig voor het uitvoeren van datamining. Het kan ook met behulp van de nieuwste databasesystemen en eenvoudige tools die gemakkelijk in elke organisatie beschikbaar zijn. Je kunt ook een eigen tool maken als de juiste tool ontbreekt. De meest populaire tool die op grote schaal wordt gebruikt in de industrie wordt hieronder gegeven:
1. R-taal
Dit is een open-source tool die wordt gebruikt voor statistische computing en grafische afbeeldingen. Deze tool helpt bij het effectief verwerken en opslaan van gegevens en deze functies zijn te wijten aan de onderstaande technieken:
- statistisch
- Klassieke statistische tests
- Tijdreeksanalyse
- Classificatie
- Grafische technieken
2. Oracle Data Mining
Deze tool wordt in de volksmond ODM genoemd en maakt deel uit van de Oracle Advanced Analytics-database. Deze tool helpt bij het analyseren van gegevens in datawarehouses en genereert gedetailleerde inzichten die verder helpen bij het maken van voorspellingen. Deze dingen helpen om het gedrag van klanten te bestuderen, producten vragen om reclame en helpen dus in hoeveelheden van verkoopkansen.
Uitdagingen bij de implementatie van Datamijn:
- Deskundige experts zijn nodig om complexe datamining-vragen te stellen.
- Huidige modellen passen mogelijk niet in de databases van de toekomstige staat. Misschien passen ze niet in toekomstige staten.
- Moeilijkheden bij het beheer van grote databases.
- Het kan nodig zijn om bedrijfspraktijken te wijzigen om informatie te gebruiken die niet is ontdekt.
- Heterogene databases en informatie die wereldwijd binnenkomen, kunnen resulteren in complexe geïntegreerde informatie.
- Datamining heeft als voorwaarde dat gegevens van verschillende aard moeten zijn, anders kunnen de resultaten onnauwkeurig zijn.
Conclusie-dataminingconcepten en -technieken
- Datamining is een manier om de gegevens uit het verleden te volgen en toekomstige analyses te gebruiken.
- Het is hetzelfde als het extraheren van de informatie die nodig is voor analyse uit de laatste datum activa die al aanwezig zijn in de databases.
- Datamining kan worden gedaan op verschillende soorten databases, zoals ruimtelijke gegevens, RDBMS, datawarehouses, meerdere en oudere databases, etc.
- Het hele mijnproces omvat bedrijfsinzicht, gegevensinzicht, gegevensvoorbereiding, modellering, evolutie, implementatie.
- Er zijn verschillende dataminingtechnieken beschikbaar om datamining op een efficiënte manier te laten werken, zoals classificatie, regressieverbinding, enz. Gebruik hangt af van het scenario.
- De meest effectieve dataminingtools zijn R-taal en Oracle Data.
- Het grootste nadeel van datamining waarmee wordt geconfronteerd, zijn de moeilijkheden bij het trainen van experts om die analysesoftware te gebruiken.
- Er zijn verschillende industrieën die datamining gebruiken voor hun analysedoeleinden, zoals bankieren, productie, supermarkten, retailserviceproviders, enz.
Aanbevolen artikelen
Dit is een gids voor dataminingconcepten en -technieken. Hier bespreken we het dataminingproces, technieken en tools in datamining. U kunt ook onze andere gerelateerde artikelen doornemen voor meer informatie-
- Voordelen van datamining
- Wat is datamining?
- Datamining-proces
- Data Science-technieken
- Clustering in machine learning
- Hoe testgegevens te genereren?
- Handleiding voor modellen in datamining