
Introductie tot Data Science Lifecycle
Data Science Lifecycle draait om het gebruik van machine learning en andere analytische methoden om inzichten en voorspellingen uit gegevens te produceren om een bedrijfsdoelstelling te bereiken. Het hele proces omvat verschillende stappen, zoals gegevens opschonen, voorbereiden, modelleren, modelevaluatie, enz. Het is een lang proces en kan enkele maanden duren om te voltooien. Het is dus heel belangrijk om voor elk probleem een algemene structuur te volgen. De wereldwijd erkende structuur voor het oplossen van elk analytisch probleem wordt Cross Industry Standard Process for Data Mining of CRISP-DM-framework genoemd.
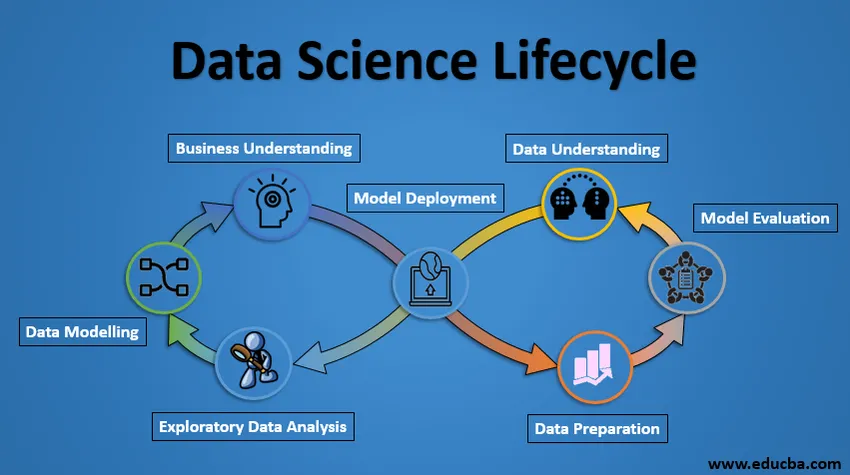
Lifecycle of Data Science
Hieronder vindt u het Lifecycle of Data Science-project.
1. Zakelijk begrip
De hele cyclus draait om het bedrijfsdoel. Wat ga je oplossen als je geen precies probleem hebt? Het is uiterst belangrijk om de zakelijke doelstelling duidelijk te begrijpen, want dat is uw uiteindelijke doel van de analyse. Na een goed begrip kunnen we alleen het specifieke analysedoel stellen dat aansluit bij de bedrijfsdoelstelling. U moet weten of de klant het kredietverlies wil verminderen, of dat hij de prijs van een grondstof wil voorspellen, enz.
2. Inzicht in gegevens
Na zakelijk inzicht is de volgende stap het begrijpen van gegevens. Dit omvat het verzamelen van alle beschikbare gegevens. Hier moet u nauw samenwerken met het zakelijke team, aangezien zij zich daadwerkelijk bewust zijn van welke gegevens aanwezig zijn, welke gegevens kunnen worden gebruikt voor dit bedrijfsprobleem en andere informatie. Deze stap omvat het beschrijven van de gegevens, hun structuur, hun relevantie, hun gegevenstype. Verken de gegevens met behulp van grafische plots. Kortom, het extraheren van alle informatie die u over de gegevens kunt krijgen door de gegevens te verkennen.
3. Gegevens voorbereiden
Vervolgens komt de fase van gegevensvoorbereiding. Dit omvat stappen zoals het selecteren van de relevante gegevens, het integreren van de gegevens door de gegevenssets samen te voegen, het op te ruimen, de ontbrekende waarden te behandelen door ze te verwijderen of toe te rekenen, foutieve gegevens te behandelen door ze te verwijderen, ook controleren op uitbijters met behulp van boxplots en ze verwerken . Nieuwe gegevens construeren, nieuwe functies ontlenen aan bestaande. Formatteer de gegevens in de gewenste structuur, verwijder ongewenste kolommen en functies. Gegevensvoorbereiding is de meest tijdrovende maar misschien wel de belangrijkste stap in de hele levenscyclus. Uw model zal net zo goed zijn als uw gegevens.
4. Verkennende gegevensanalyse
Deze stap omvat het verkrijgen van een idee over de oplossing en factoren die daarop van invloed zijn, voordat het eigenlijke model wordt gebouwd. Distributie van gegevens binnen verschillende variabelen van een functie wordt grafisch onderzocht met behulp van staafdiagrammen. Relaties tussen verschillende functies worden vastgelegd via grafische weergaven zoals spreidingsplots en warmtekaarten. Veel andere datavisualisatietechnieken worden uitgebreid gebruikt om elke functie afzonderlijk te verkennen, en door ze te combineren met andere functies.
5. Gegevensmodellering
Gegevensmodellering is het hart van gegevensanalyse. Een model neemt de voorbereide gegevens als invoer en levert de gewenste uitvoer. Deze stap omvat het kiezen van het juiste type model, of het probleem een classificatieprobleem is, of een regressieprobleem of een clusterprobleem. Na het kiezen van de modelfamilie, uit de verschillende algoritmen onder die familie, moeten we zorgvuldig de algoritmen kiezen om ze te implementeren en te implementeren. We moeten de hyperparameters van elk model afstemmen om de gewenste prestaties te bereiken. We moeten ook zorgen voor een juiste balans tussen prestaties en generaliseerbaarheid. We willen niet dat het model de gegevens leert en slecht presteert op nieuwe gegevens.
6. Modelevaluatie
Hier wordt het model geëvalueerd om te controleren of het klaar is voor implementatie. Het model is getest op ongeziene gegevens, geëvalueerd op een zorgvuldig doordachte set evaluatiemetrieken. We moeten er ook voor zorgen dat het model voldoet aan de realiteit. Als we bij de evaluatie geen bevredigend resultaat krijgen, moeten we het hele modelleringsproces herhalen totdat het gewenste metriekniveau is bereikt. Elke data science-oplossing, een machine learning-model, net als een mens, moet evolueren, moet in staat zijn zichzelf te verbeteren met nieuwe gegevens, zich aan te passen aan een nieuwe evaluatiemetriek. We kunnen meerdere modellen bouwen voor een bepaald fenomeen, maar veel van hen kunnen onvolkomen zijn. Modelevaluatie helpt ons bij het kiezen en bouwen van een perfect model.
7. Modelimplementatie
Het model wordt na een grondige evaluatie eindelijk in het gewenste formaat en kanaal ingezet. Dit is de laatste stap in de levenscyclus van data science. Elke stap in de levenscyclus van data science die hierboven is uitgelegd, moet zorgvuldig worden uitgevoerd. Als een stap onjuist wordt uitgevoerd, heeft dit consequentie voor de volgende stap en gaat de hele inspanning verloren. Als gegevens bijvoorbeeld niet correct worden verzameld, verliest u informatie en bouwt u geen perfect model. Als de gegevens niet goed worden opgeschoond, werkt het model niet. Als het model niet goed wordt geëvalueerd, zal het in de echte wereld mislukken. Vanaf het begrip van het bedrijf tot de implementatie van het model, moet elke stap de juiste aandacht, tijd en moeite krijgen.
Aanbevolen artikelen
Dit is een gids voor Data Science Lifecycle. Hier bespreken we een overzicht van Data Science Lifecycle en de stappen waaruit een data science-levenscyclus bestaat. U kunt ook onze gerelateerde artikelen doornemen voor meer informatie -
- Introductie van Data Science Algorithms
- Data Science vs Software Engineering | Top 8 nuttige vergelijkingen
- Verschillen Soorten Data Science-technieken
- Data Science-vaardigheden met typen