

Inleiding tot RDBMS Interviewvragen en antwoord
Dus als u zich voorbereidt op een sollicitatiegesprek in RDBMS. Ik weet zeker dat je de meest voorkomende RDBMS-interviewvragen en -antwoorden voor 2019 wilt weten waarmee je het RDBMS-interview gemakkelijk kunt kraken. Hieronder vindt u de lijst met de beste RDBMS-interviewvragen en antwoorden tot uw redding.
Daarom hebben we de neiging om de beste RDBMS-interviewvragen van 2019 toe te voegen die meestal in een interview worden gesteld
1.Wat zijn verschillende functies van een RDBMS?
Antwoord:
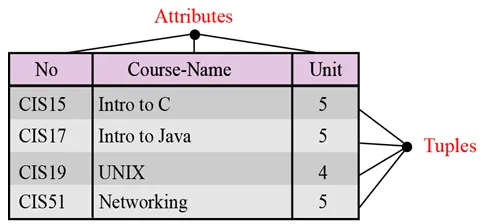
Naam. Elke relatie in een relationele database moet een naam hebben die uniek is onder alle andere relaties.
Attributen. Elke kolom in een relatie wordt een kenmerk genoemd.
Tuples. Elke rij in een relatie wordt een tuple genoemd. Een tuple definieert een verzameling attribuutwaarden.
2.U ER-model verklaren?
Antwoord:
ER-model is een entiteit-relatiemodel. ER-model is gebaseerd op een echte wereld die bestaat uit entiteiten en relatieobjecten. Entiteiten worden in een database geïllustreerd door een set attributen.
3. Objectgeoriënteerd model definiëren?
Antwoord:
Objectgeoriënteerd model is gebaseerd op verzamelingen objecten. Een object bevat waarden die in het object bijvoorbeeld variabelen zijn opgeslagen. Objecten met een identiek type waarden en exact dezelfde methoden zijn gegroepeerd in klassen.
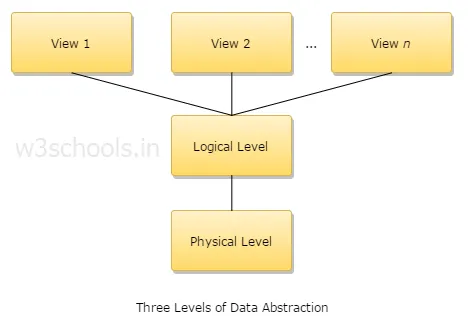
4. Drie niveaus van gegevensabstractie verklaren?
Antwoord:
1. Fysiek niveau: dit is het laagste abstractieniveau en beschrijft hoe gegevens worden opgeslagen.
2. Logisch niveau: het volgende abstractieniveau is logisch, het beschrijft welk type gegevens in een database is opgeslagen en wat de relatie tussen deze gegevens is.
3. View level: Het hoogste abstractieniveau en het beschrijft de enige volledige database.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5.Wat zijn verschillende Codd's 12 regels voor relationele database?
Antwoord:
De 12 regels van Codd zijn een set van dertien regels (genummerd van nul tot twaalf) voorgesteld door Edgar F. Codd.
Codd's regels: -
Regel 0: Het systeem moet kwalificeren als relationeel, als een database en ook als een managementsysteem.
Regel 1: De informatieregel: elke informatie in de database moet uniek worden weergegeven, voornamelijk naamwaarden in kolomposities in een andere rij van een tabel.
Regel 2: De gegarandeerde toegangsregel: alle gegevens moeten indringend zijn. Het zegt dat elke scalaire waarde in de database correct / logisch adresseerbaar moet zijn.
Regel 3: Systematische behandeling van null-waarden: het DBMS moet toestaan dat elke tuple nul blijft.
Regel 4: Actieve online catalogus (structuur van database) op basis van het relationele model: het systeem moet een online, relationele enz. -Structuur ondersteunen die indringerig is voor toegestane gebruikers door middel van hun reguliere zoekopdracht.
Regel 5: De uitgebreide datasubtaal: het systeem moet minimaal één relationele taal ondersteunen die:
1.Heeft een lineaire syntaxis
2.Wat kan worden gebruikt als zowel interactief als binnen applicatieprogramma's,
Het ondersteunt gegevensdefinitiebewerkingen (DDL), gegevensmanipulatiebewerkingen (DML), beveiligings- en integriteitsbeperkingen en transactiebeheerbewerkingen (begin, vastleggen en terugdraaien).
Regel 6: De regel voor het bijwerken van weergaven: alle weergaven die theoretisch verbeteren, moeten door het systeem kunnen worden opgewaardeerd.
Regel 7: Invoegen, bijwerken en verwijderen op hoog niveau: het systeem moet operators voor invoegen, bijwerken en verwijderen ondersteunen.
Regel 8: Fysieke gegevensonafhankelijkheid: wijzig het fysieke niveau (hoe de gegevens worden opgeslagen, met behulp van arrays of gekoppelde lijsten, enz.). Er is geen aanpassing van een toepassing vereist.
Regel 9: Logische gegevensonafhankelijkheid: wijzig het logische niveau (tabellen, kolommen, rijen, enz.). Dit mag geen wijziging van een toepassing vereisen.
Regel 10: Integriteitsonafhankelijkheid: integriteitsbeperkingen moeten afzonderlijk worden geïdentificeerd uit applicatieprogramma's en worden opgeslagen in de catalogus.
Regel 11: Distributieonafhankelijkheid: de distributie van delen van een database naar verschillende locaties mag niet zichtbaar zijn voor gebruikers van de database.
Regel 12: De niet-subversieregel: als het systeem een interface op laag niveau (dat wil zeggen records) biedt, kan die interface niet worden gebruikt om het systeem te ondermijnen.
6. Wat is normalisatie? en wat verklaart verschillende normalisatievormen.
Antwoord:
Database-normalisatie is een proces waarbij gegevens worden georganiseerd om gegevensredundantie te minimaliseren. Wat op zijn beurt zorgt voor consistentie van gegevens. Er zijn veel problemen in verband met gegevensredundantie zoals verspilling van schijfruimte, inconsistentie van gegevens, DML-vragen (Data Manipulation Language) worden traag. Er zijn verschillende normalisatievormen: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - De gegevens in elke kolom moeten atoomnummer zijn, meerdere waarden gescheiden door een komma. De tabel bevat geen herhalende kolomgroepen. Identificeer elk record op unieke wijze met behulp van de primaire sleutel.
2. 2NF: - De tabel moet voldoen aan alle voorwaarden van 1NF en overbodige gegevens verplaatsen naar een afzonderlijke tabel. Bovendien creëert het een relatie tussen deze tabellen met behulp van buitenlandse sleutels.
3. 3NF: - voor een 3NF-tabel moet voldoen aan alle voorwaarden van 1NF en 2NF. 3NF bevat geen attributen die gedeeltelijk afhankelijk zijn van de primaire sleutel.
7. Definieer primaire sleutel, externe sleutel, kandidaatsleutel, super sleutel?
Antwoord:
Primaire sleutel: primaire sleutel is de sleutel die geen dubbele waarden en null-waarden toestaat. Een primaire sleutel kan worden gedefinieerd op kolomniveau of tabelniveau. Per tabel is slechts één primaire sleutel toegestaan.
Externe sleutel: buitenlandse sleutel staat alleen de waarden toe die aanwezig zijn in de kolom waarnaar wordt verwezen. Het staat dubbele of nulwaarden toe. Het kan worden gedefinieerd als kolomniveau of tabelniveau. Het kan verwijzen naar een kolom met een unieke / primaire sleutel.
Kandidaatsleutel: een Kandidaatsleutel is een minimale supersleutel, er is geen juiste subgroep van kenmerken van de Kandidaatsleutel kan een supersleutel zijn.
Supersleutel : een superkey is een set attributen van een relatieschema waarvan alle attributen van het schema gedeeltelijk afhankelijk zijn. Geen twee rijen kunnen dezelfde waarde hebben voor supersleutelattributen.
8. Wat is een ander type indexen?
Antwoord:
Indexen zijn: -
Geclusterde index: - Het is de index waarbij gegevens fysiek op de schijf worden opgeslagen. Daarom kan slechts één geclusterde index worden gemaakt voor een databasetabel.
Niet-geclusterde index: - Het definieert geen fysieke gegevens maar definieert een logische volgorde. Meestal worden B-Tree of B + tree voor dit doel gemaakt.
9.Wat zijn de voordelen van RDBMS?
Antwoord:
• Redundantie beheren.
• Integriteit kan worden afgedwongen.
• Inconsistentie kan worden voorkomen.
• Gegevens kunnen worden gedeeld.
• Standaard kan worden afgedwongen.
10.Naam enkele subsystemen van RDBMS?
Antwoord:
Input-output, Beveiliging, Taalverwerking, Opslagbeheer, Logging en herstel, Distributiecontrole, Transactiecontrole, Geheugenbeheer.
11. Wat is Buffer Manager?
Antwoord:
Buffer Manager slaagt erin om gegevens van schijfopslag naar het hoofdgeheugen te verzamelen en te beslissen welke gegevens in het cachegeheugen moeten worden opgeslagen voor snellere verwerking.
Aanbevolen artikel
Dit is een gids voor Lijst met RDBMS-interviewvragen en antwoorden, zodat de kandidaat deze RDBMS-interviewvragen gemakkelijk kan beantwoorden. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Meest belangrijke sollicitatievragen voor Data Analytics
- 13 Verbazingwekkende vragen en antwoorden over databasetests
- Top 10 Interviewvragen en antwoord voor ontwerppatronen
- 5 Nuttige SSIS-interviewvragen en antwoorden