

Inleiding tot varkenscommando's
Apache Pig een tool / platform dat wordt gebruikt om grote datasets te analyseren en een lange reeks gegevensbewerkingen uit te voeren. Varken wordt gebruikt met Hadoop. Alle pig-scripts worden intern omgezet in map-reduce taken en worden vervolgens uitgevoerd. Het kan gestructureerde, semi-gestructureerde en ongestructureerde gegevens verwerken. Varkenswinkels, het resultaat in HDFS. In dit artikel leren we de meer soorten varkenscommando's.
Hier zijn enkele kenmerken van Pig:
- Zelfoptimalisatie: Pig kan de uitvoeringstaken optimaliseren, de gebruiker heeft de vrijheid om zich te concentreren op semantiek.
- Gemakkelijk te programmeren: Pig biedt een taal / dialect op hoog niveau dat bekend staat als Pig Latin, dat gemakkelijk te schrijven is. Pig Latin biedt veel operators, die programmeur kan gebruiken om de gegevens te verwerken. De programmeur heeft de flexibiliteit om ook zijn eigen functies te schrijven.
- Uitbreidbaar: Pig vergemakkelijkt het creëren van een aangepaste functie die UDF's (door de gebruiker gedefinieerde functies) wordt genoemd, waardoor programmeurs in staat zijn om elke verwerkingsvereiste snel en gemakkelijk te bereiken. Pig-script draait op een shell die bekend staat als de grunt.
Waarom varkenscommando's?
Programmeurs die niet goed zijn met Java, hebben meestal moeite met het schrijven van programma's in Hadoop, dwz het schrijven van taken om de kaart te verminderen. Voor hen is Pig Latin, dat erg op SQL-taal lijkt, een zegen. De multi-query-benadering vermindert de lengte van de code.
Dus over het algemeen zijn beknopte en effectieve manier van programmeren. Pig Commands kan code in vele talen oproepen, zoals JRuby, Jython en Java.
De architectuur van Pig Commands
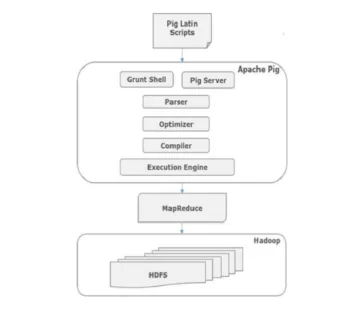
Alle scripts geschreven in Pig-Latin over grunt shell gaan naar de parser voor het controleren van de syntaxis en andere diverse controles gebeuren ook. De uitvoer van de parser is een DAG. Deze DAG wordt vervolgens doorgegeven aan Optimizer, die vervolgens logische optimalisatie zoals projectie uitvoert en naar beneden duwt. Vervolgens voldoet de compiler aan het logische plan voor MapReduce-taken. Ten slotte worden deze MapReduce-taken in gesorteerde volgorde bij Hadoop ingediend. Deze taken worden uitgevoerd en produceren gewenste resultaten.
Pig-Latin datamodel is volledig genest en maakt complexe datatypes mogelijk, zoals map en tuple.
Elke enkele waarde van de Latijnse taal van het varken (ongeacht het gegevenstype) staat bekend als Atom.
Basic Pig Commando's
Laten we eens kijken naar enkele van de Basic Pig-opdrachten die hieronder worden gegeven: -
1. Fs: dit geeft een lijst van alle bestanden in de HDFS
grunt> fs –ls
2. Wissen: hiermee wordt de interactieve Grunt-shell gewist.
grommen> wissen
3. Geschiedenis:
Deze opdracht toont de opdrachten die tot nu toe zijn uitgevoerd.
grunt> geschiedenis
4. Gegevens lezen: ervan uitgaande dat de gegevens zich in HDFS bevinden, en we moeten gegevens naar Pig lezen.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
PigStorage GEBRUIKEN (', ')
as (id: int, voornaam: chararray, achternaam: chararray, telefoon: chararray,
stad: chararray);
PigStorage () is de functie die gegevens laadt en opslaat als gestructureerde tekstbestanden.
5. Gegevens opslaan: Store-operator wordt gebruikt om de verwerkte / geladen gegevens op te slaan.
grunt> WINKEL college_students IN 'hdfs: // localhost: 9000 / pig_Output /' GEBRUIKEN PigStorage (', ');
Hier is "/ pig_Output /" de map waarin de relatie moet worden opgeslagen.
6. Dump Operator: deze opdracht wordt gebruikt om de resultaten op het scherm weer te geven. Het helpt meestal bij het debuggen.
grunt> Dump college_students;
7. Beschrijf Operator: het helpt de programmeur om het schema van de relatie te bekijken.
grunt> beschrijven college_students;
8. Leg uit: deze opdracht helpt om de logische, fysieke en map-reductie uitvoeringsplannen te herzien.
grunt> verklaar college_students;
9. Illustrator-operator: dit geeft stapsgewijze uitvoering van instructies in Pig-opdrachten.
grunt> illustreren college_students;
Tussentijdse varkenscommando's
1. Groep: deze Pig-opdracht werkt om gegevens met dezelfde sleutel te groeperen.
grunt> group_data = GROUP college_students op voornaam;
2. COGROUP: het werkt op dezelfde manier als de groepsexploitant. Het belangrijkste verschil tussen Group & Cogroup-operator is die groepsoperator die meestal met één relatie wordt gebruikt, terwijl cogroup met meer dan één relatie wordt gebruikt.
3. Deelnemen: dit wordt gebruikt om twee of meer relaties te combineren.
Voorbeeld: om self-join uit te voeren, laten we zeggen dat de relatie "klant" wordt geladen vanuit HDFS tp pig-opdrachten in twee relaties klanten1 & klanten2.
grom> klanten3 = WORD LID van klanten1 DOOR id, klanten2 DOOR id;
Join kan zelf-join, Inner-join, Outer-join zijn.
4. Kruis: dit pig-commando berekent het kruisproduct van twee of meer relaties.
grunt> cross_data = CROSS klanten, bestellingen;
5. Unie: het voegt twee relaties samen. De voorwaarde voor het samenvoegen is dat zowel de kolommen als de domeinen van de relatie identiek moeten zijn.
grunt> student = UNION student1, student2;
Geavanceerde varkenscommando's
Laten we eens kijken naar enkele van de geavanceerde Pig-opdrachten die hieronder worden gegeven:
1. Filter: dit helpt bij het filteren van de tupels uit relatie, op basis van bepaalde voorwaarden.
filter_data = FILTER college_students BY city == 'Chennai';
2. Onderscheidend: dit helpt bij het verwijderen van overbodige tupels uit de relatie.
grunt> distinct_data = DISTINCT college_students;
Deze filtering maakt een nieuwe relatienaam "distinct_data"
3. Foreach: dit helpt bij het genereren van gegevenstransformatie op basis van kolomgegevens.
grunt> foreach_data = FOREACH student_details GENERATE id, leeftijd, stad;
Dit haalt de id, leeftijd en stadswaarden van elke student uit de relatie student_details en slaat het daarom op in een andere relatie met de naam foreach_data.
4. Sorteren op: met deze opdracht wordt het resultaat weergegeven in een gesorteerde volgorde op basis van een of meer velden.
grunt> order_by_data = BESTEL college_students OP leeftijd DESC;
Dit sorteert de relatie "college_students" in afnemende volgorde op leeftijd.
5. Limiet: dit commando krijgt een beperkte nee. van tupels uit de relatie.
grunt> limit_data = LIMIT student_details 4;
Tips en trucs
Hieronder staan de verschillende tips en trucs van Pig-opdrachten: -
1. Schakel compressie in op uw invoer en uitvoer:
set input.compression.enabled true;
set output.compression.enabled true;
Bovengenoemde coderegels moeten aan het begin van het script staan, zodat Pig Commands gecomprimeerde bestanden kan lezen of gecomprimeerde bestanden als uitvoer kan genereren.
2. Word lid van meerdere relaties:
Voor het uitvoeren van de linker join op zeg drie relaties (input1, input2, input3), moet men kiezen voor SQL. Dit komt omdat outer join niet door Pig op meer dan twee tafels wordt ondersteund.
In plaats daarvan voer je links uit om mee te doen in twee stappen, zoals:
data1 = JOIN input1 BY- toets LINKS, input2 BY- toets;
data2 = JOIN data1 BY input1 :: sleutel LINKS, input3 BY sleutel;
Dit betekent twee taken om de kaart te verminderen.
Om de bovenstaande taak effectiever uit te voeren, kan men kiezen voor “Cogroup”. Cogroup kan lid worden van meerdere relaties. Cogroup doet standaard outer join.
Conclusie
Varken is een proceduretaal, die meestal door datawetenschappers wordt gebruikt voor het uitvoeren van ad-hocverwerking en snelle prototyping. Het is een geweldige ETL en big data-verwerkingstool. Varkenscripts kunnen door andere talen worden aangeroepen en vice versa. Daarom kunnen Pig Commands worden gebruikt om grotere en complexe applicaties te bouwen.
Aanbevolen artikelen
Dit is een gids geweest voor Pig-commando's. Hier hebben we de basis- en geavanceerde Pig-commando's en enkele onmiddellijke Pig-commando's besproken. U kunt ook het volgende artikel bekijken voor meer informatie -
- Adobe Photoshop-opdrachten
- Tableau-opdrachten
- Cheatsheet SQL (opdrachten, gratis tips en trucs)
- VBA-opdrachten - afwerking
- Verschillende bewerkingen met betrekking tot Tuples