
Inleiding tot classificatie van neuraal netwerk
Neurale netwerken zijn de meest efficiënte manier (ja, je leest het goed) om echte problemen in kunstmatige intelligentie op te lossen. Momenteel is het ook een van de veel uitgebreid onderzochte gebieden in de informatica dat een nieuwe vorm van neuraal netwerk zou zijn ontwikkeld terwijl u dit artikel leest. Er zijn honderden neurale netwerken om problemen op te lossen die specifiek zijn voor verschillende domeinen. Hier gaan we je door verschillende soorten basale neurale netwerken leiden in de volgorde van toenemende complexiteit.
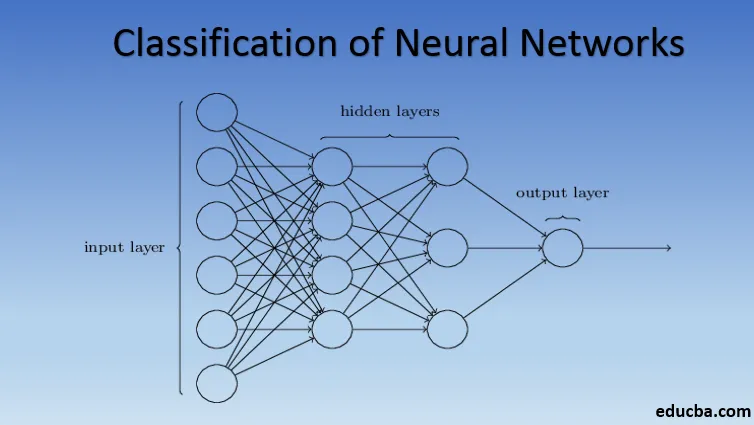
Verschillende soorten basisprincipes bij de classificatie van neurale netwerken
1. Ondiepe neurale netwerken (Collaborative Filtering)
Neurale netwerken zijn gemaakt van groepen Perceptron om de neurale structuur van het menselijk brein te simuleren. Ondiepe neurale netwerken hebben een enkele verborgen laag van de perceptron. Een van de meest voorkomende voorbeelden van oppervlakkige neurale netwerken is Collaborative Filtering. De verborgen laag van de perceptron zou worden getraind om de overeenkomsten tussen entiteiten weer te geven om aanbevelingen te genereren. Aanbevelingssysteem in Netflix, Amazon, YouTube, etc. gebruikt een versie van Collaborative filtering om hun producten aan te bevelen op basis van de interesse van de gebruiker.
2. Meerlagige Perceptron (Deep Neural Networks)
Neurale netwerken met meer dan één verborgen laag worden Deep Neural Networks genoemd. Spoiler alert! Alle volgende neurale netwerken zijn een vorm van diep neuraal netwerk dat is aangepast / verbeterd om domeinspecifieke problemen aan te pakken. Over het algemeen helpen ze ons universaliteit te bereiken. Bij voldoende aantal verborgen lagen van het neuron kan een diep neuraal netwerk dat wil zeggen een complex probleem uit de echte wereld oplossen.
De universele benaderingstelling is de kern van diepe neurale netwerken om elk model te trainen en te passen. Elke versie van het diepe neurale netwerk is ontwikkeld door een volledig verbonden laag van maximaal gepoold product van matrixvermenigvuldiging die is geoptimaliseerd door backpropagatie-algoritmen. We zullen doorgaan met het leren van de verbeteringen die resulteren in verschillende vormen van diepe neurale netwerken.
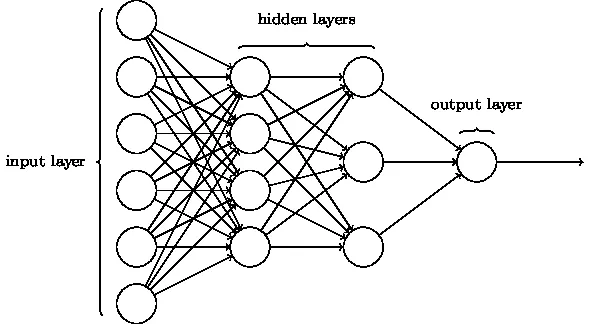
3. Convolutioneel neuraal netwerk (CNN)
CNN's zijn de meest volwassen vorm van diepe neurale netwerken om de meest accurate, dwz beter dan menselijke resultaten te produceren in computer vision. CNN's zijn gemaakt van lagen van convoluties die zijn gemaakt door elke pixel met afbeeldingen in een gegevensset te scannen. Naarmate de gegevens laag voor laag worden benaderd, beginnen CNN de patronen te herkennen en daardoor de objecten in de afbeeldingen te herkennen. Deze objecten worden veelvuldig gebruikt in verschillende applicaties voor identificatie, classificatie, enz. Recente praktijken zoals transfer learning in CNN's hebben geleid tot aanzienlijke verbeteringen in de onnauwkeurigheid van de modellen. Google Translator en Google Lens zijn de meest geavanceerde voorbeelden van CNN's.
De toepassing van CNN's is exponentieel omdat ze zelfs worden gebruikt bij het oplossen van problemen die in de eerste plaats geen verband houden met computer vision. Een zeer eenvoudige maar intuïtieve uitleg van CNN's is hier te vinden.
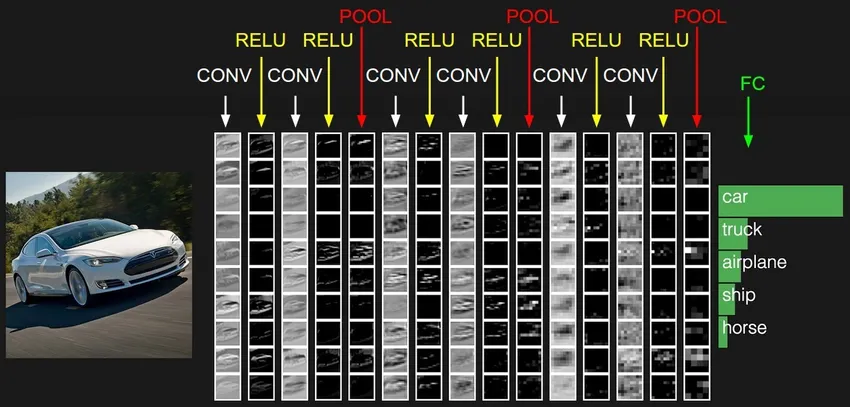
4. Terugkerend neuraal netwerk (RNN)
RNN's zijn de meest recente vorm van diepe neurale netwerken voor het oplossen van problemen in NLP. Simpel gezegd, RNN's voeren de uitvoer van een paar verborgen lagen terug naar de invoerlaag om de benadering te aggregeren en verder te brengen naar de volgende iteratie (tijdperk) van de invoergegevensset. Het helpt het model ook om zichzelf te leren en corrigeert de voorspellingen sneller tot op zekere hoogte. Dergelijke modellen zijn zeer nuttig bij het begrijpen van de semantiek van de tekst in NLP-bewerkingen. Er zijn verschillende varianten van RNN's zoals Long Short Term Memory (LSTM), Gated Recurrent Unit (GRU), enz. In het onderstaande diagram wordt de activering van h1 en h2 gevoed met respectievelijk ingang x2 en x3.
5. Lang kortetermijngeheugen (LSTM)
LSTM's zijn specifiek ontworpen om het probleem met de verdwijningsgradiënten met de RNN aan te pakken. Vanishing Gradients gebeurt met grote neurale netwerken waar de gradiënten van de verliesfuncties de neiging hebben om dichter bij nul te komen, waardoor pauzerende neurale netwerken leren. LSTM lost dit probleem op door activeringsfuncties in zijn terugkerende componenten te voorkomen en door de opgeslagen waarden niet te wijzigen. Deze kleine verandering gaf grote verbeteringen in het uiteindelijke model, resulterend in technische reuzen die LSTM in hun oplossingen aanpasten. Over naar de "meest eenvoudige zelfverklarende" illustratie van LSTM,
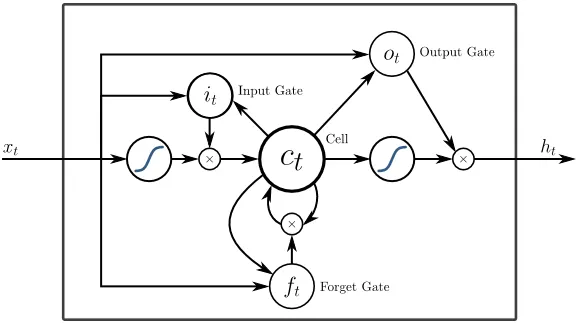
6. Op aandacht gebaseerde netwerken
Aandachtsmodellen nemen langzaam zelfs de nieuwe RNN's over in de praktijk. De aandachtsmodellen zijn gebouwd door zich te concentreren op een deel van een subset van de informatie die ze krijgen, waardoor de overweldigende hoeveelheid achtergrondinformatie wordt geëlimineerd die niet nodig is voor de taak die moet worden uitgevoerd. Aandachtsmodellen zijn gebouwd met een combinatie van zachte en harde aandacht en aanpassing door zachte aandacht terug te verspreiden. Meerdere aandachtsmodellen die hiërarchisch zijn gestapeld, worden Transformer genoemd. Deze transformatoren zijn efficiënter om de stapels parallel te laten lopen, zodat ze state of the art resultaten produceren met relatief minder gegevens en tijd voor het trainen van het model. Een aandachtsverdeling wordt zeer krachtig bij gebruik met CNN / RNN en kan als volgt een tekstbeschrijving naar een afbeelding produceren.

Technische reuzen zoals Google, Facebook, etc. passen snel aandachtsmodellen aan voor het bouwen van hun oplossingen.
7. Generatief adversarieel netwerk (GAN)
Hoewel diepgaande leermodellen state of the art resultaten bieden, kunnen ze voor de gek worden gehouden door veel intelligentere menselijke tegenhangers door ruis toe te voegen aan de gegevens uit de echte wereld. GAN's zijn de nieuwste ontwikkeling in diep leren om dergelijke scenario's aan te pakken. GAN's gebruiken Ongecontroleerd leren waarbij diepe neurale netwerken getraind worden met de gegevens gegenereerd door een AI-model samen met de feitelijke gegevensset om de nauwkeurigheid en efficiëntie van het model te verbeteren. Deze tegenstrijdige gegevens worden meestal gebruikt om het discriminerende model voor de gek te houden om een optimaal model te bouwen. Het resulterende model is meestal een betere benadering dan dergelijke ruis kan overwinnen. De onderzoeksinteresse in GAN's heeft geleid tot meer geavanceerde implementaties zoals Conditional GAN (CGAN), Laplacian Pyramid GAN (LAPGAN), Super Resolution GAN (SRGAN), etc.
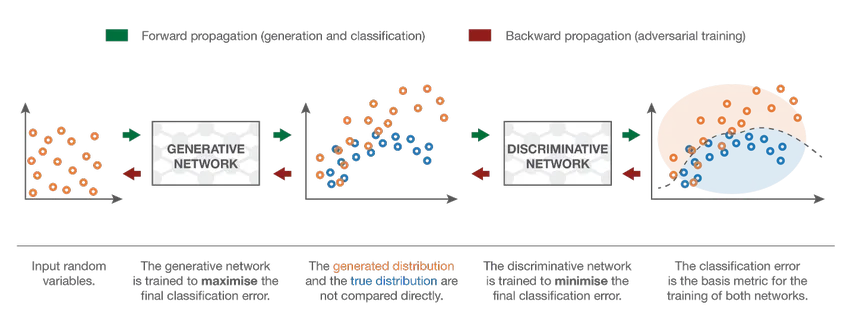
Conclusie - Classificatie van neuraal netwerk
De diepe neurale netwerken hebben de grenzen van de computers verlegd. Ze zijn niet alleen beperkt tot classificatie (CNN, RNN) of voorspellingen (Collaborative Filtering) maar zelfs het genereren van gegevens (GAN). Deze gegevens kunnen variëren van de prachtige vorm van kunst tot controversiële Deep fakes, maar ze overtreffen mensen elke dag met een taak. Daarom moeten we ook AI-ethiek en -effecten overwegen terwijl we hard werken om een efficiënt neuraal netwerkmodel te bouwen. Tijd voor een nette infographic over de neurale netwerken.
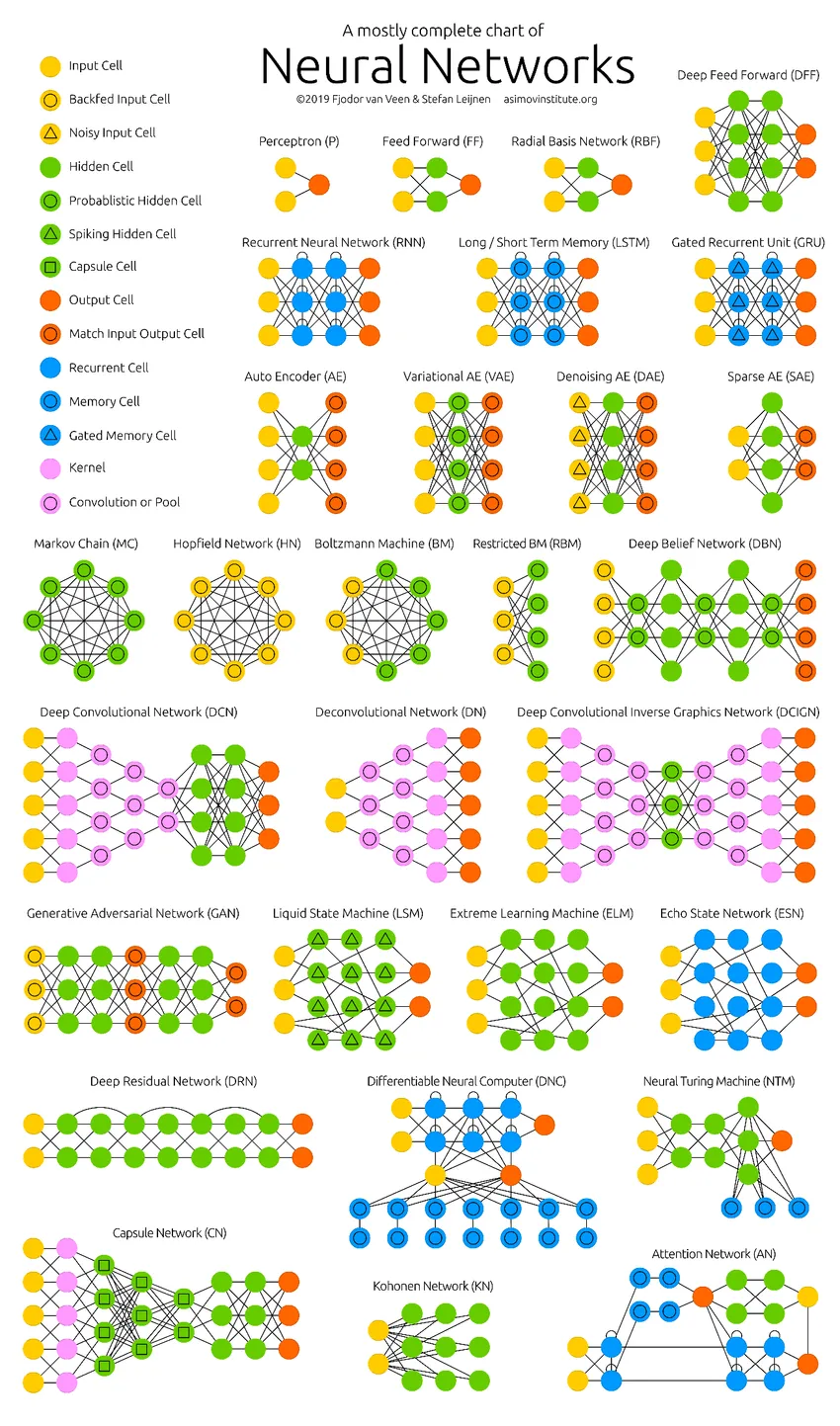
Aanbevolen artikelen
Dit is een gids voor de classificatie van neuraal netwerk. Hier hebben we de verschillende soorten Basic Neural Networks besproken. U kunt ook door onze gegeven artikelen gaan voor meer informatie-
- Wat is neurale netwerken?
- Neurale netwerkalgoritmen
- Tools voor netwerkscannen
- Terugkerende neurale netwerken (RNN)
- Top 6 Vergelijkingen tussen CNN en RNN