
Definitie van Mean Shift-algoritme
Mean Shift Algorithm valt onder toezicht zonder toezicht, dat is gecategoriseerd als het Clustering-algoritme. De ideologie van het Mean Shift-algoritme is dat iteratief datapunten worden toegewezen aan de clusters door te schuiven naar het punt met het hoogste dichtheidspunt (modus). De onderliggende onderliggende logica van de gemiddelde verschuiving is gebaseerd op het concept van de schatting van de kerneldichtheid, KDE genoemd.
Mean Shift Algorithm Clustering
Een niet-begeleide leertechniek ontdekt door Fukunaga en Hostetler om clusters te vinden:
- Mean Shift is ook bekend als het moduszoekende algoritme dat de gegevenspunten op een manier toewijst aan de clusters door de gegevenspunten naar het gebied met hoge dichtheid te verschuiven. De hoogste dichtheid aan gegevenspunten wordt het model in de regio genoemd. Mean Shift-algoritme heeft toepassingen die veel worden gebruikt op het gebied van computer vision en beeldsegmentatie.
- KDE is een methode om de verdeling van de gegevenspunten te schatten. Het werkt door een kernel op elk gegevenspunt te plaatsen. De kernel in wiskundige term is een weegfunctie die gewichten toepast voor individuele gegevenspunten. Het toevoegen van alle afzonderlijke kernels genereert de waarschijnlijkheid.
De kernelfunctie is vereist om aan de volgende voorwaarden te voldoen:
- De eerste vereiste is om ervoor te zorgen dat de schatting van de kerneldichtheid genormaliseerd is.
- De tweede vereiste is dat KDE goed geassocieerd is met de symmetrie van de ruimte.
Twee populaire kernelfuncties
Hieronder staan de twee populaire kernelfuncties die erin worden gebruikt:
- Platte kernel
- Gaussiaanse kernel
- Op basis van de gebruikte kernelparameter varieert de resulterende dichtheidsfunctie. Als er geen kernelparameter wordt vermeld, wordt Gaussian Kernel standaard aangeroepen. KDE maakt gebruik van het concept van waarschijnlijkheidsdichtheidsfunctie die helpt bij het vinden van de lokale maxima van de gegevensdistributie. Het algoritme werkt door de gegevenspunten zo aan elkaar te trekken dat de gegevenspunten naar het gebied met een hoge dichtheid toe trekken.
- De gegevenspunten die proberen te convergeren naar de lokale maxima zullen van dezelfde clustergroep zijn. In tegenstelling tot het K-Means-clusteralgoritme, is de output van het Mean Shift-algoritme niet afhankelijk van aannames over de vorm van het gegevenspunt en het aantal clusters. Het aantal clusters wordt bepaald door het algoritme met betrekking tot gegevens.
- Om de implementatie van het Mean Shift-algoritme uit te voeren, maken we gebruik van het python-pakket SKlearn.
Implementatie van het Mean Shift-algoritme
Hieronder is de implementatie van het algoritme:
Voorbeeld 1
Gebaseerd op Sklearn-zelfstudie voor Mean Shift Clustering-algoritme. Het eerste fragment zal een gemiddeld verschuivingsalgoritme implementeren om de clusters van de tweedimensionale gegevensset te vinden. Pakketten die worden gebruikt om het Mean shift-algoritme te implementeren.
Code:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Een belangrijk ding om op te merken is dat we de make_blobs-bibliotheek van sklearn zullen gebruiken om datapunten te genereren gecentreerd op 3 locaties. Om het Mean shift-algoritme op de gegenereerde punten toe te passen, moeten we de bandbreedte instellen die de interactie tussen de lengte vertegenwoordigt. Sklearn's bibliotheek heeft ingebouwde functies om de bandbreedte te schatten.
Code:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
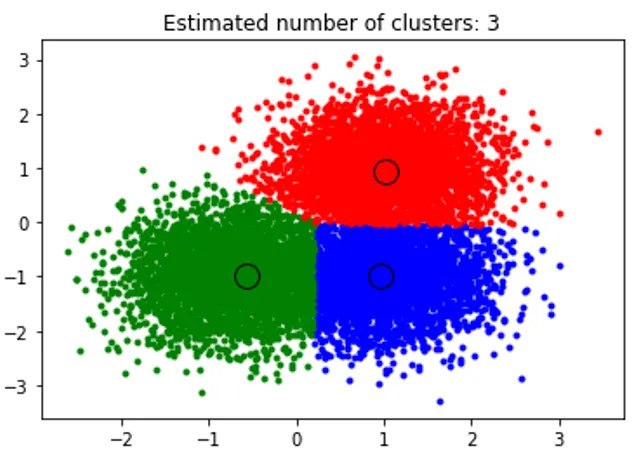
Het bovenstaande fragment voert clustering uit en het algoritme vond clusters gecentreerd op elke blob die we hebben gegenereerd. We kunnen zien dat uit de onderstaande afbeelding, geplot door het fragment, het Mean shift-algoritme toont dat het aantal benodigde clusters in runtime kan identificeren en de juiste bandbreedte kan berekenen om de interactielengte weer te geven.
Output:
Voorbeeld 2
Gebaseerd op beeldsegmentatie in Computer Vision. Het tweede fragment onderzoekt hoe het Mean shift-algoritme in Deep Learning wordt gebruikt om segmentatie van de gekleurde afbeelding uit te voeren. We maken gebruik van het Mean Shift-algoritme om de ruimtelijke clusters te identificeren. Het eerdere fragment gebruikten we 2D-gegevensset, terwijl in dit voorbeeld de 3D-ruimte wordt onderzocht. Pixel van de afbeelding wordt behandeld als gegevenspunten (r, g, b). We moeten de afbeelding converteren naar matrixindeling zodat elke pixel het gegevenspunt vertegenwoordigt in de afbeelding die we naar het segment gaan. Clustering van de kleurwaarden in de ruimte levert een reeks clusters op, waarbij de pixels in de cluster vergelijkbaar zijn met RGB-ruimte. Pakketten gebruikt om Mean Shift-algoritme te implementeren:
Code:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Onderstaand fragment om de originele afbeelding te segmenteren:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
De gegenereerde afbeelding stelt dat deze benadering om de vormen van afbeeldingen te identificeren en de ruimtelijke clusters te bepalen, effectief kan worden uitgevoerd zonder enige beeldverwerking.
Output:


Voordelen en toepassingen Mean Shift Algorithm
Hieronder staan de voordelen en toepassing van het gemiddelde algoritme:
- Het wordt veel gebruikt om computer vision op te lossen, waar het wordt gebruikt voor beeldsegmentatie.
- Clustering van datapunten in realtime zonder het aantal clusters te vermelden.
- Presteert goed op beeldsegmentatie en videotracking.
- Robuuster tegen uitbijters.
Voordelen van Mean Shift Algorithm
Hieronder staan de profs betekenen shift-algoritme:
- De output van het algoritme is onafhankelijk van initialisaties.
- De procedure is effectief omdat deze slechts één parameter heeft - Bandbreedte.
- Geen veronderstellingen over het aantal gegevensclusters en de vorm.
- Het heeft betere prestaties dan K-Means Clustering.
Nadelen van Mean Shift Algorithm
Hieronder staan de nadelen van het gemiddelde shift-algoritme:
- Duur voor grote functies.
- In vergelijking met K-Means is clustering erg traag.
- Algoritme-uitvoer hangt af van de parameterbandbreedte.
- Uitvoer is afhankelijk van de grootte van het venster.
Conclusie
Hoewel het een eenvoudige aanpak is die voornamelijk werd gebruikt om problemen met beeldsegmentatie, clustering op te lossen. Het is relatief langzamer dan K-middelen en het is rekenkundig duur.
Aanbevolen artikelen
Dit is een gids voor het Mean Shift-algoritme. Hier bespreken we problemen met betrekking tot beeldsegmentatie, clustering, voordelen en twee kernelfuncties. U kunt ook onze andere gerelateerde artikelen doornemen voor meer informatie-
- K- betekent clusteringalgoritme
- KNN-algoritme in R
- Wat is genetisch algoritme?
- Kernelmethoden
- Kernelmethoden in machinaal leren
- Detail Verklaring van C ++ algoritme