

Overzicht van Kafka-toepassingen
Een van de trendvelden in de IT-industrie is Big Data, waar het bedrijf met een grote hoeveelheid klantgegevens omgaat en nuttige inzichten verkrijgt die hun bedrijf helpen en klanten betere service bieden. Een van de uitdagingen is het verwerken en overbrengen van deze grote hoeveelheden gegevens van het ene uiteinde naar het andere voor analyse of verwerking, dit is waar Kafka (een betrouwbaar berichtensysteem) in het spel komt, wat helpt bij het verzamelen en transporteren van een enorme hoeveelheid gegevens live. Kafka is ontworpen voor gedistribueerde systemen met een hoge doorvoer en is geschikt voor grootschalige toepassingen voor berichtverwerking. Kafka ondersteunt veel van de beste commerciële en industriële toepassingen van vandaag. Er is vraag naar Kafka-professionals met sterke vaardigheden en praktische kennis.
In dit artikel zullen we meer te weten komen over Kafka, de functies ervan, gebruiksscenario's en enkele opmerkelijke toepassingen begrijpen waar het wordt gebruikt.
Wat is Kafka?
Apache Kafka werd ontwikkeld op LinkedIn en werd later een open-source Apache-project. Apache Kafka is een snel, fouttolerant, schaalbaar en gedistribueerd berichtensysteem dat communicatie mogelijk maakt tussen twee entiteiten, dwz tussen producenten (generator van het bericht) en consumenten (ontvanger van het bericht) met behulp van op berichten gebaseerde onderwerpen en biedt een platform voor het beheer van alle de realtime datafeeds.
De functies die Apache Kafka beter maken dan andere berichtensystemen en van toepassing zijn op real-time systemen zijn de hoge beschikbaarheid, onmiddellijk en automatisch herstel van knooppuntfouten en ondersteunt berichtlevering met lage latentie. Deze functies van Apache Kafka helpen bij de integratie met grootschalige datasystemen en maken het een ideale component voor communicatie. 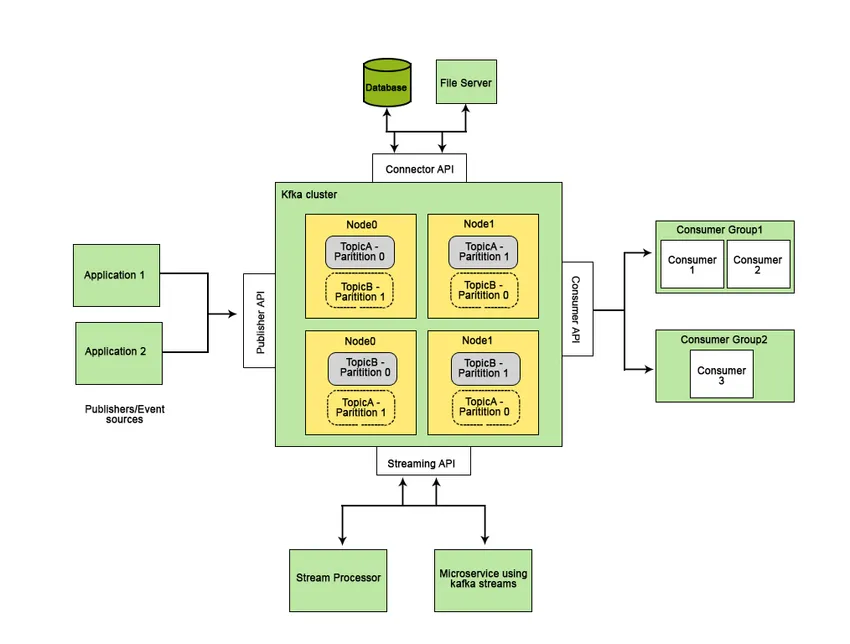
Top Kafka-toepassingen
In dit gedeelte van het artikel zullen we enkele populaire en breed geïmplementeerde gebruiksscenario's zien en een real-life implementatie van Kafka.
Real-life toepassingen
1. Twitter: stream-verwerkingsactiviteit
Twitter is een sociaal netwerkplatform dat Storm-Kafka (open-source stream processing tool) gebruikt als onderdeel van hun stream processing infrastructuur, waar invoergegevens (tweets) worden gebruikt voor aggregatie, transformaties en verrijking voor verder verbruik of follow-up verwerkingsactiviteiten.
2. LinkedIn: Stream Processing & Metrics
LinkedIn gebruikt Kafka voor het streamen van gegevens en voor operationele metrische activiteiten. LinkedIn gebruikt Kafka voor zijn extra functies zoals Newsfeed voor het consumeren van berichten en het uitvoeren van analyses op de ontvangen gegevens.
3. Netflix: realtime monitoring en stroomverwerking
Netflix heeft een eigen opnameframework dat invoergegevens in AWS S3 dumpt en Hadoop gebruikt voor het uitvoeren van analyses van videostreams, UI-activiteiten, evenementen om de gebruikerservaring te verbeteren, en Kafka voor realtime gegevensopname via API's.
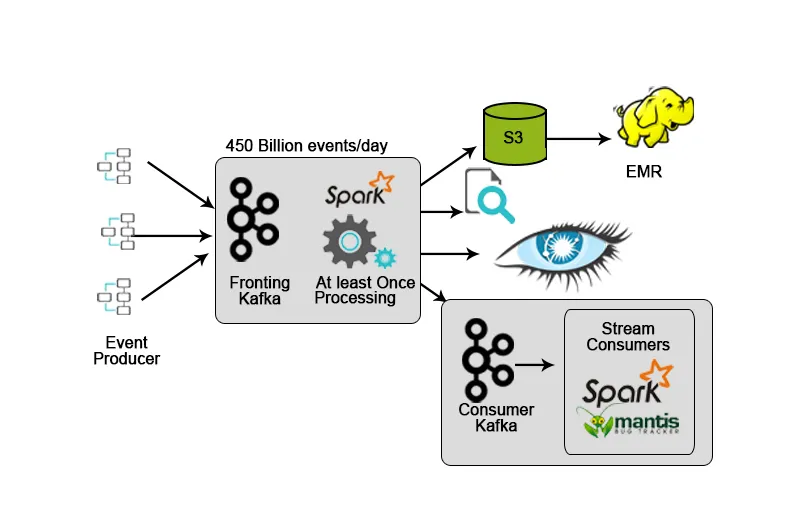
4. Hotstar: stroomverwerking
Hotstar introduceerde zijn eigen datamanagementplatform Bifrost waar Kafka wordt gebruikt voor datastreaming, monitoring en target tracking. Vanwege zijn schaalbaarheid, beschikbaarheid en lage latentiemogelijkheden was Kafka een ideale keuze om de gegevens te verwerken die het hotstar-platform dagelijks of bij een speciale gelegenheid genereert (livestreaming van concerten, live sportwedstrijden, enz.) Waar de hoeveelheid gegevens neemt aanzienlijk toe.
Apache Kafka wordt meestal gebruikt als bouwsteen om streaming data-architectuur te ontwikkelen. Dit soort architectuur wordt gebruikt in toepassingen zoals een verzameling product- / serverlogboeken, analyse van clickstream en het afleiden van informatie uit machinaal gegenereerde gegevens.
Maar samen met Kafka moeten we extra bronnen of hulpmiddelen gebruiken om de verkregen datastroom om te zetten in betekenisvolle gegevens die helpen bij het verkrijgen van inzichten die kunnen worden gebruikt bij gegevensgestuurde beslissingen. We moeten bijvoorbeeld mogelijk inzichten genereren uit de onbewerkte gegevens die zijn verkregen van IoT-apparaten of gegevens die zijn verkregen van sociale mediaplatforms in realtime en een analyse of verwerking hebben uitgevoerd en deze aan het bedrijf hebben getoond om betere beslissingen te nemen of hen te helpen verbeteren de uitvoering van hun diensten.
Voor dit soort gebruiksscenario's willen we onze invoergegevens / onbewerkte gegevens naar een gegevensmeer streamen, waar we onze gegevens kunnen opslaan en gegevenskwaliteit kunnen garanderen zonder de prestaties te belemmeren.
Een andere situatie, misschien dat we gegevens rechtstreeks van Kafka lezen, is wanneer we extreem lage end-to-end latentie nodig hebben, zoals het invoeren van gegevens voor realtime-toepassingen.
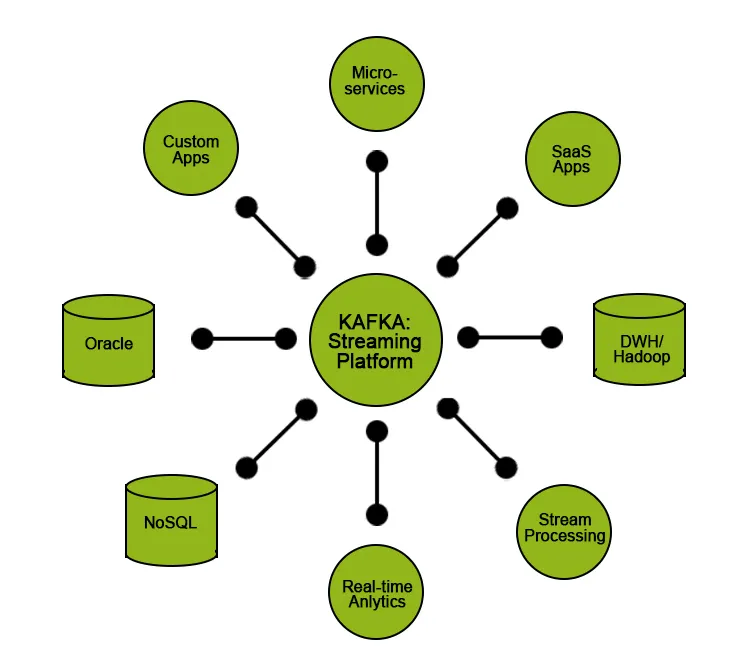
Kafka biedt bepaalde functionaliteiten aan zijn gebruikers:
- Publiceer en abonneer u op gegevens.
- Bewaar gegevens in de volgorde waarin ze efficiënt zijn gegenereerd.
- Real-time / On-the-fly verwerking van gegevens.
Kafka wordt meestal gebruikt voor:
- Implementeren van on-the-fly streaming gegevenspijplijnen die op betrouwbare wijze gegevens tussen twee entiteiten in het systeem ontvangen.
- Implementatie van streamingapplicaties die de datastromen transformeren of manipuleren of verwerken.
Gebruik Cases
Hieronder staan enkele veel geïmplementeerde use cases van Kafka-toepassing:
1. Berichten
Kafka werkt beter dan andere traditionele berichtensystemen zoals ActiveMQ, RabbitMQ, enz. In vergelijking biedt Kafka betere doorvoer, ingebouwde partitiefaciliteit, replicatie en fouttolerantie, waardoor het een beter berichtensysteem is voor grootschalige verwerkingstoepassingen .
2. Website-activiteit volgen
Gebruikersactiviteiten (paginaweergaven, zoekopdrachten of uitgevoerde acties) kunnen worden gevolgd en ingevoerd voor realtime monitoring of analyse via Kafka of Kafka gebruiken om dit soort gegevens op te slaan in Hadoop of datawarehouse voor latere verwerking of manipulatie. Activiteiten volgen genereert een enorme hoeveelheid gegevens die moet worden overgebracht naar de gewenste locatie zonder enig verlies van gegevens.
3. Logboekaggregatie
Logboekaggregatie is een proces waarbij fysieke logboekbestanden van verschillende servers van een toepassing worden verzameld / samengevoegd in een enkele repository (bestandsserver of HDFS) voor verwerking. Kafka biedt goede prestaties, lagere end-to-end latentie in vergelijking met Flume.

Conclusie
Kafka wordt veel gebruikt in de big data-ruimte als een manier om zeer snel grote hoeveelheden data op te nemen en te verplaatsen vanwege de prestatiekenmerken en functies die helpen bij het bereiken van schaalbaarheid, betrouwbaarheid en duurzaamheid. In dit artikel hebben we de functies, gebruikstoepassingen en toepassingen van Apache Kafka besproken en wat het een betere tool maakt voor het streamen van gegevens.
Aanbevolen artikelen
Dit is een gids voor Kafka-toepassingen. Hier bespreken we wat Kafka is, samen met topapplicaties van Kafka, waaronder breed geïmplementeerde use cases en een aantal real-life implementatie. U kunt ook de volgende artikelen bekijken voor meer informatie-
- Wat is Kafka?
- Hoe Kafka installeren?
- Vragen tijdens solliciteren bij Kafka
- Apache Kafka tegen Flume
- Top 8 apparaten van IoT die u moet kennen
- Kafka vs Kinesis | Verschillen met infographics
- Verschillende soorten Kafka-tools met componenten
- Leer de belangrijkste verschillen van ActiveMQ versus Kafka