

Verschillen tussen Sqoop en Flume
Sqoop is een product van Apache-software. Sqoop haalt nuttige informatie uit Hadoop en gaat vervolgens naar de externe datastores. Met behulp van Sqoop kunnen we gegevens van een RDBMS of mainframe in HDFS importeren. Flume is ook afkomstig van Apache-software. Het verzamelt en verplaatst de gegenereerde recursieve gegevens. De Apache Flume is niet alleen beperkt tot het verzamelen van loggegevens, maar gegevensbronnen kunnen worden aangepast en dus kan Flume worden gebruikt om enorme hoeveelheden gegevens te transporteren. De beste manier om grote hoeveelheden gegevens tussen het Hadoop Distributed File System en RDBMS te verzamelen, te aggregeren en te verplaatsen, is met behulp van hulpmiddelen zoals Sqoop of Flume.
Laten we deze twee veelgebruikte hulpmiddelen bespreken voor het bovengenoemde doel.
Wat is Sqoop
Om Sqoop te gebruiken, moet een gebruiker opgeven welke gereedschapgebruiker hij wil gebruiken en de argumenten die het specifieke gereedschap besturen. U kunt de gegevens vervolgens ook weer exporteren naar een RDBMS met behulp van Sqoop. De exportfunctionaliteit van Sqoop wordt gebruikt om nuttige informatie uit Hadoop te extraheren en naar de externe gestructureerde datastores te exporteren. Het werkt met verschillende databases zoals Teradata, MySQL, Oracle, HSQLDB.
- Sqoop-architectuur: -
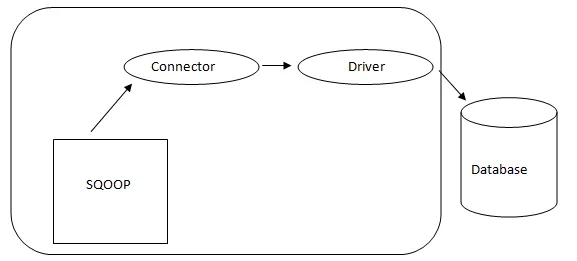
Architectuur van Sqoop
De connector in een Sqoop is een plug-in voor een bepaalde databasebron, dus het is van fundamenteel belang dat het een onderdeel van Sqoop is. Ondanks het feit dat stuurprogramma's database-specifieke onderdelen zijn en worden gedistribueerd door verschillende databaseverkopers, wordt Sqoop zelf gebundeld met verschillende soorten connectoren die worden gebruikt voor het meest voorkomende database- en informatieopslagsysteem. Zo wordt Sqoop ook met een verscheidenheid aan connectoren uit de doos geleverd. Sqoop biedt een insteekbaar onderdeel voor een ideaal netwerk en een extern systeem. De Sqoop API biedt een handige structuur voor het samenstellen van nieuwe connectoren en daarom kunnen alle databaseconnectoren in de Sqoop-installatie worden geplaatst om connectiviteit met verschillende datasystemen te bieden.
Wat is Flume?
De Apache Flume is niet alleen beperkt tot het verzamelen van loggegevens, maar gegevensbronnen kunnen worden aangepast en dus kan Flume worden gebruikt voor het transporteren van enorme hoeveelheden gegevens, inclusief maar niet beperkt tot e-mailberichten, gegevens die door sociale media zijn gegenereerd, netwerkverkeergegevens en vrijwel alle gegevensbron mogelijk.
Flume-architectuur: - Flume-architectuur is gebaseerd op veel-kernconcepten:
- Flume Event - het wordt weergegeven als de eenheid voor het stromen van gegevens, met een byte-payload en een reeks strings met optionele string-headers. Flume beschouwt een gebeurtenis als een generieke klodder bytes.
- Flume Agent - Het is een JVM-proces dat de componenten host, zoals kanalen, sink en bronnen. Het heeft het potentieel om de evenementen van een externe bron te ontvangen, op te slaan en door te sturen naar het volgende niveau.
- Flume Flow - dit is het tijdstip waarop het evenement wordt gegenereerd.
- Flume Client - het verwijst naar de interface waar de client werkt op het beginpunt van het evenement en levert dit af aan de Flume-agent.
- Bron - Een bron is een bron die evenementen met een specifiek formaat gebruikt en via een specifiek mechanisme aflevert.
- Kanaal - Het is een passieve winkel waar evenementen worden gehouden totdat de gootsteen het verwijdert voor verder transport.
- Sink - Het verwijdert de gebeurtenis van een kanaal en plaatst het op een externe repository zoals HDFS. Het ondersteunt momenteel het maken van tekst- en reeksbestanden en ondersteunt compressie in beide bestandstypen.
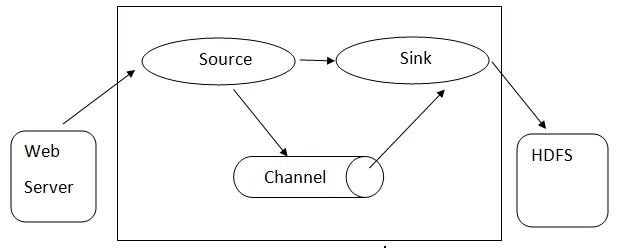
Architectuur van Flume
Head to Head-vergelijking tussen Sqoop vs Flume (Infographics)
Hieronder is de top 7 vergelijking tussen Sqoop en Flume

Belangrijkste verschillen tussen Sqoop versus Flume
We weten nu dat er veel verschillen zijn tussen Sqoop en Flume, hier zijn de belangrijkste verschillen hieronder:
1. Sqoop is ontworpen om massa-informatie uit te wisselen tussen Hadoop en Relational Database.
Terwijl Flume wordt gebruikt om gegevens te verzamelen van verschillende bronnen die gegevens genereren met betrekking tot een bepaalde use case en vervolgens deze grote hoeveelheid gegevens overbrengen van gedistribueerde bronnen naar een enkele gecentraliseerde repository.
2. Sqoop bevat ook een reeks opdrachten waarmee u de database waarmee u werkt, kunt inspecteren. We kunnen Sqoop dus beschouwen als een verzameling verwante tools.
Tijdens het verzamelen van de datum Flume schalen de gegevens horizontaal en kunnen meerdere Flume-agenten worden ingezet om de datum te verzamelen en te aggregeren. Daarna worden gegevenslogboeken verplaatst naar een gecentraliseerd gegevensarchief, dwz Hadoop Distributed File System (HDFS).
3. De belangrijkste factor voor het gebruik van Flume is dat de gegevens op een continue en streaming manier moeten worden gegenereerd. Evenzo is Sqoop het meest geschikt in situaties waarin uw gegevens in databasesystemen zoals MySQL, Oracle, Teradata, PostgreSQL leven
Sqoop vs Flume (vergelijkingstabel)
| Basis voor vergelijking | SQOOP | FLUIM |
|
Fundamentele aard | Sqoop werkt goed met alle RDBMS met JDBC (Java Database Connectivity) zoals Oracle, MySQL, Teradata, etc. | Flume werkt goed voor streaming gegevensbron die continu wordt gegenereerd, zoals logboeken, JMS, directory, crashrapporten, enz. |
| Informatiestroom | Sqoop specifiek gebruikt voor parallelle gegevensoverdracht. Om deze reden kan de uitvoer in meerdere bestanden zijn | Flume wordt gebruikt voor het verzamelen en aggregeren van gegevens vanwege de gedistribueerde aard ervan. |
| Gedreven evenementen | Sqoop wordt niet aangedreven door evenementen. | Flume is volledig event-driven. |
| architectuur | Sqoop volgt connector-gebaseerde architectuur, wat betekent connectoren, weet hoe verbinding te maken met een andere gegevensbron. | Flume volgt op een agent gebaseerde architectuur, waarbij de erin geschreven code bekend staat als een agent die verantwoordelijk is voor het ophalen van gegevens. |
| Waar te gebruiken | Vooral gebruikt om gegevens sneller te kopiëren en vervolgens te gebruiken voor het genereren van analytische resultaten. | Over het algemeen gebruikt om gegevens te verzamelen wanneer bedrijven patronen, basisoorzaken of sentimentanalyse met behulp van logs en sociale media willen analyseren. |
| Prestatie | Het vermindert overmatige opslag- en verwerkingslasten door deze over te dragen naar andere systemen en heeft snelle prestaties. | Flume is fouttolerant, robuust en heeft een houdbaar betrouwbaarheidsmechanisme voor failover en herstel. |
| Release geschiedenis | De eerste versie van Apache Sqoop werd uitgebracht in maart 2012. De huidige stabiele release is 1.4.7 | De eerste stabiele versie 1.2.0 van Apache Flume werd gelanceerd in juni 2012. De huidige stabiele versie is Apache Flume versie 1.8.0. |
Conclusie - Sqoop vs Flume
Zoals u hierboven hebt geleerd, zijn Sqoop en Flume hoofdzakelijk twee Data Inslikken-tools die in de Big Data-wereld worden gebruikt. Als u tekstuele loggegevens in Hadoop / HDFS moet opnemen, is Flume de juiste keuze om dat te doen. Als uw gegevens niet regelmatig worden gegenereerd, werkt Flume nog steeds, maar het is een overkill voor die situatie. Evenzo is Sqoop niet het meest geschikt voor gebeurtenisgestuurde gegevensverwerking.
Aanbevolen artikelen
Dit is een leidraad geweest voor verschillen tussen Sqoop en Flume, hun betekenis, vergelijking van persoon tot persoon, belangrijkste verschillen, vergelijkingstabel en conclusie. dit artikel bestaat uit alle nuttige verschillen tussen Sqoop en Flume. U kunt ook de volgende artikelen bekijken voor meer informatie
- Hadoop vs Teradata - Nuttige verschillen om te leren
- 5 Belangrijkste verschil tussen Apache Kafka versus Flume
- Big Data vs Apache Hadoop - Top 4-vergelijking die u moet leren
- 5 Belangrijkste verschil tussen Apache Kafka versus Flume
- Belangrijke tekstwinning versus natuurlijke taalverwerking - Top 5-vergelijkingen