

Wat is Naive Bayes-algoritme?
Naive Bayes Algorithm is een techniek die helpt bij het construeren van classificaties. Classificeerders zijn de modellen die de probleeminstanties classificeren en ze klassenlabels geven die worden voorgesteld als vectoren van voorspellers of kenmerkwaarden. Het is gebaseerd op de stelling van Bayes. Het wordt naïeve Bayes genoemd omdat het ervan uitgaat dat de waarde van een functie onafhankelijk is van de andere functie, dwz dat het wijzigen van de waarde van een functie de waarde van de andere functie niet beïnvloedt. Het wordt om dezelfde reden ook als idioot Bayes genoemd. Dit algoritme werkt efficiënt voor grote gegevenssets en is daarom het meest geschikt voor realtime voorspellingen.
Het helpt om de posterieure waarschijnlijkheid P (c | x) te berekenen met behulp van de eerdere waarschijnlijkheid van klasse P (c), de eerdere waarschijnlijkheid van voorspeller P (x) en de waarschijnlijkheid van de voorspellende klasse, ook wel waarschijnlijkheid P (x | c genoemd) ).
De formule of vergelijking om de posterieure waarschijnlijkheid te berekenen is:
- P (c | x) = (P (x | c) * P (c)) / P (x)
Hoe werkt Naive Bayes Algorithm?
Laten we de werking van Naive Bayes-algoritme begrijpen aan de hand van een voorbeeld. We gaan uit van een trainingsgegevensset van het weer en de doelvariabele 'Gaan winkelen'. Nu zullen we classificeren of een meisje gaat winkelen op basis van weersomstandigheden.
De gegeven dataset is:
| Weer | Gaan winkelen |
| Zonnig | Nee |
| Regenachtig | Ja |
| bewolking | Ja |
| Zonnig | Ja |
| bewolking | Ja |
| Regenachtig | Nee |
| Zonnig | Ja |
| Zonnig | Ja |
| Regenachtig | Nee |
| Regenachtig | Ja |
| bewolking | Ja |
| Regenachtig | Nee |
| bewolking | Ja |
| Zonnig | Nee |
De volgende stappen zouden worden uitgevoerd:
Stap 1: Maak frequentietabellen met behulp van gegevenssets.
| Weer | Ja | Nee |
| Zonnig | 3 | 2 |
| bewolking | 4 | 0 |
| Regenachtig | 2 | 3 |
| Totaal | 9 | 5 |
Stap 2: Maak een waarschijnlijkheidstabel door de waarschijnlijkheden van elke weersomstandigheid te berekenen en te gaan winkelen.
| Weer | Ja | Nee | Waarschijnlijkheid |
| Zonnig | 3 | 2 | 5/14 = 0, 36 |
| bewolking | 4 | 0 | 4/14 = 0, 29 |
| Regenachtig | 2 | 3 | 5/14 = 0, 36 |
| Totaal | 9 | 5 | |
| Waarschijnlijkheid | 9/14 = 0, 64 | 5/14 = 0, 36 |
Stap 3: Nu moeten we de posterieure waarschijnlijkheid berekenen met behulp van de Naive Bayes-vergelijking voor elke klasse.
Probleem bijvoorbeeld: een meisje gaat winkelen als het bewolkt is. Is deze verklaring juist?
Oplossing:
- P (Ja | Overcast) = (P (Overcast | Ja) * P (Ja)) / P (Overcast)
- P (bewolkt | Ja) = 4/9 = 0, 44
- P (Ja) = 9/14 = 0, 64
- P (bewolkt) = 4/14 = 0, 39
Zet nu alle berekende waarden in de bovenstaande formule
- P (Ja | Geheel bewolkt) = (0, 44 * 0, 64) / 0, 39
- P (Ja | Geheel bewolkt) = 0.722
De klasse met de hoogste waarschijnlijkheid zou de uitkomst van de voorspelling zijn. Met behulp van dezelfde aanpak kunnen kansen van verschillende klassen worden voorspeld.
Waar wordt Naive Bayes algoritme voor gebruikt?
1. Real-time voorspelling: het Naïeve Bayes-algoritme is snel en altijd klaar om te leren en is daarom het meest geschikt voor real-time voorspellingen.
2. Multiklasse voorspelling: de waarschijnlijkheid van multiklassen van elke doelvariabele kan worden voorspeld met behulp van een Naive Bayes-algoritme.
3. Aanbevelingssysteem: Naive Bayes-classificator bouwt met behulp van Collaborative Filtering een Aanbevelingssysteem. Dit systeem maakt gebruik van datamining en machine learning-technieken om de informatie te filteren die nog niet eerder is gezien en voorspelt vervolgens of een gebruiker een bepaalde bron zou waarderen of niet.
4. Tekstclassificatie / Sentimentanalyse / Spamfiltering: vanwege de betere prestaties bij multi-class problemen en de onafhankelijkheidsregel, presteert het Naive Bayes-algoritme beter of heeft het een hoger slagingspercentage in tekstclassificatie, daarom wordt het gebruikt in Sentimentanalyse en Spamfiltering.
Voordelen van Naive Bayes Algorithm
- Eenvoudig te implementeren.
- Snel
- Als de onafhankelijkheidsveronderstelling geldt, werkt deze efficiënter dan andere algoritmen.
- Het vereist minder trainingsgegevens.
- Het is zeer schaalbaar.
- Het kan probabilistische voorspellingen doen.
- Kan zowel continue als discrete gegevens verwerken.
- Ongevoelig voor irrelevante functies.
- Het kan gemakkelijk werken met ontbrekende waarden.
- Gemakkelijk bij te werken bij aankomst van nieuwe gegevens.
- Meest geschikt voor problemen met tekstclassificatie.
Nadelen van Naive Bayes Algorithm
- De sterke veronderstelling dat de functies onafhankelijk zijn, is nauwelijks waar in echte toepassingen.
- Gegevensschaarste.
- Kans op verlies van nauwkeurigheid.
- Nul frequentie, dwz als de categorie van een categorische variabele niet wordt gezien in trainingsgegevensset, kent het model een nulkans toe aan die categorie en kan er geen voorspelling worden gedaan.
Hoe een basismodel te bouwen met behulp van Naive Bayes-algoritme
Er zijn drie soorten Naive Bayes-modellen, namelijk Gaussiaans, Multinomiaal en Bernoulli. Laten we elk van hen kort bespreken.
1. Gaussiaans: Gaussiaans Naïef Bayes-algoritme veronderstelt dat de continue waarden die overeenkomen met elk kenmerk worden verdeeld volgens de Gaussische verdeling, ook wel Normale verdeling genoemd.
De waarschijnlijkheid of eerdere waarschijnlijkheid van voorspeller van de gegeven klasse wordt verondersteld Gaussiaans te zijn, daarom kan voorwaardelijke waarschijnlijkheid worden berekend als:
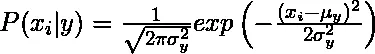
2. Multinomiaal: de frequenties van het optreden van bepaalde gebeurtenissen die worden voorgesteld door kenmerkvectoren worden gegenereerd met behulp van multinomiale verdeling. Dit model wordt veel gebruikt voor documentclassificatie.
3. Bernoulli: In dit model worden de ingangen beschreven door de functies die onafhankelijke binaire variabelen of Booleans zijn. Dit wordt ook veel gebruikt in documentclassificatie zoals Multinomial Naive Bayes.
U kunt elk van de bovenstaande modellen gebruiken om de gegevensset te verwerken en classificeren.
U kunt een Gaussiaans model bouwen met Python door het onderstaande voorbeeld te begrijpen:
Code:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array((-2, 7), (1, 2), (1, 5), (2, 3), (1, -1), (-2, 0), (-4, 0), (-2, 2), (3, 7), (1, 1), (-4, 1), (-3, 7)))
b = np.array((3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4))
md = GaussianNB()
md.fit (a, b)
pd = md.predict (((1, 2), (3, 4)))
print (pd)
Output:
((3, 4))
Conclusie
In dit artikel hebben we de concepten van Naive Bayes Algorithm in detail geleerd. Het wordt meestal gebruikt in tekstclassificatie. Het is eenvoudig te implementeren en snel uit te voeren. Het grote nadeel is dat het vereist dat de functies onafhankelijk zijn, wat niet het geval is in echte toepassingen.
Aanbevolen artikelen
Dit is een gids voor Naive Bayes-algoritme. Hier hebben we het basisconcept, werken, voordelen en nadelen van Naive Bayes-algoritme besproken. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Algoritme stimuleren
- Algoritme in programmeren
- Inleiding tot algoritme