

Wat is Kafka?
Om Kafka te begrijpen, is het beter om te begrijpen wat 'Stream Processing' technologie is. 'Streamverwerking is een technologie waarmee een gebruiker in een microtijdsbestek een continue gegevensstroom kan opvragen om de onderliggende verantwoordelijke omstandigheden beter te begrijpen.
Een realtime scenario - stel je voor dat je temperatuursensor gegevens verzendt die je kunt opvragen en een waarschuwing ontvangen nadat een vriespunt is ontvangen. Deze gegevensquery kan in microseconden worden uitgevoerd.
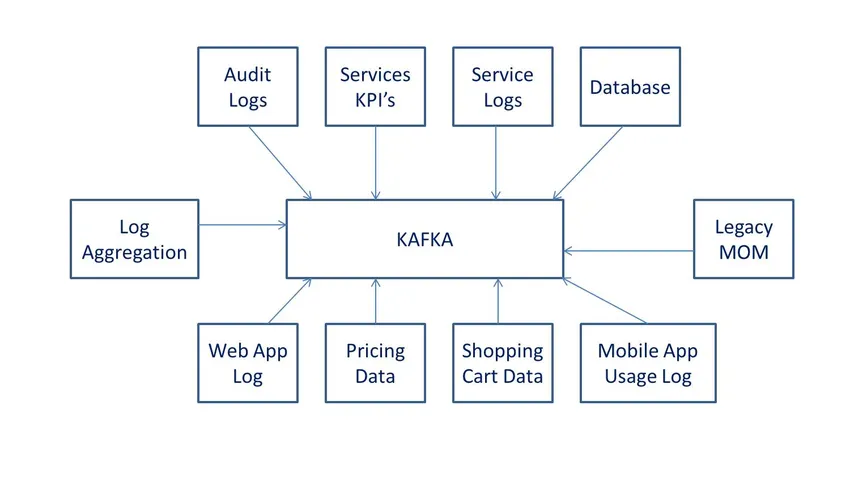
Definities
volgens Wiki is het open-source dataverwerkingssoftware. Het werd ontwikkeld door LinkedIn en later gedoneerd aan Apache-software.
Kafka begrijpen
De groei explodeert exponentieel. Laten we eens wat feiten en statistieken bekijken om onze gedachte beter te onderstrepen. Het geniet de voorkeur van meer dan een derde van de Fortune 500 over de hele wereld. Deze distributie wordt gedeeld door reisbedrijven, telecomreuzen, banken en verschillende anderen. LinkedIn, Microsoft en Netflix verwerken vier komma-berichten per dag met Kafka (bijna gelijk aan 1.000.000.000.000).
Het wordt gebruikt voor realtime gegevensstromen, om big data te verzamelen of om realtime analyses te maken (of beide). Kafka wordt gebruikt met in-memory microservices om duurzaamheid te bieden en het kan worden gebruikt om events te voeden aan CEP (complexe event streaming systemen) en IoT / IFTTT-stijl automatiseringssystemen.
Hoe werkt Kafka zo gemakkelijk?
Gedreven door eenvoud zou de juiste manier zijn om de prestaties te definiëren. Het is gemakkelijk om erachter te komen hoe Kafka zo gemakkelijk werkt vanaf de installatie en het gebruik. Deze verhoogde prestaties in gedrag zijn toegewijd aan de stabiliteit, de voorziening voor betrouwbare duurzaamheid, met zijn flexibele ingebouwde mogelijkheid om onderhoud te publiceren of in te schrijven of in de wachtrij te plaatsen. Dit is zeer cruciaal om te hebben als u moet omgaan met N - nummers van de klantengroep, als u een robuuste replicatie in de markt moet laten zien, gericht op het bieden van een consistente aanpak aan uw klanten (dwz Kafka-onderwerppartitie). Een cruciaal gedrag van Kafka waardoor het zich onderscheidt van zijn concurrenten, is de compatibiliteit met systemen met gegevensstromen - het proces en maakt deze systemen mogelijk om andere winkels te aggregeren, transformeren en laden voor gebruiksgemak. "Alle bovengenoemde feiten zouden niet mogelijk zijn als Kafka langzaam was". De uitzonderlijke prestaties maken dit mogelijk.
Met verdere toevoeging aan het gemak van Kafka werken moeten we naar "OS-niveau" gaan. Laten we eens kijken hoe dingen voor Kafka op OS-niveau werken -
- Het vertrouwt op OS-kernels voor het sneller verplaatsen van de gegevens en werkt volgens het principe van nulkopie.
- Hiermee kunnen gegevensrecords in brokken worden gebundeld die kunnen worden gezien vanuit het bestandssysteem (ook wel Kafka-onderwerplogboek) voor consumenten.
- De mogelijkheid om gegevens te batchen geeft een efficiënte datacompressie met I / O latentiereductie.
- Het heeft de mogelijkheid om horizontaal te schalen via sharding. Het kan een titellogboek verschuiven naar honderden partities tot duizenden. Hierdoor kan het de enorme werklast gemakkelijk aan.
Wat kunt u doen met Kafka?
Als uw bedrijf regelmatig met grote hoeveelheden gegevens speelt, heeft u Kafka nodig. Er is een lange lijst van bedrijven die het gebruiken.
- LinkedIn gebruikt om gegevens en operationele statistieken bij te houden.
- Twitter om stream-verwerkingsinfrastructuren te bieden.
Er is een lange lijst met bedrijven, van Uber tot Spotify en Goldman Sachs tot Cisco.
voordelen
- Hoge doorvoer: het kan gemakkelijk een grote hoeveelheid gegevens verwerken wanneer het genereren met hoge snelheid een uitzonderlijk voordeel is in het voordeel van Kafka. Deze applicatie mist enorme hardware. Met de capaciteit om berichtdoorvoer te ondersteunen met een frequentie van duizenden berichten per seconde.
- Lage latentie: lage latentie voor het verwerken van deze berichten met hoog volume.
- Fouttolerantie: deze functie is erg handig, het heeft een inherente mogelijkheid om te worden beperkt door een knooppunt dat in een cluster is ingebouwd.
- Duurzaam: het is zeer duurzaam in gebruik en daarom geven veel MNC's de voorkeur aan Kafka. Over duurzaamheid gesproken, de berichten kunnen op de lange termijn niet verloren gaan.
Benodigde vaardigheden
Er is geen speciale vereiste om Kafka-professional te zijn. Maar we hebben enkele streams en professionals onderstreept -
- Ontwikkelaars die graag carrière willen maken in Big Data-stream en hun carrière willen versnellen.
- Testende professionals hebben een goede scope in Kafka op het gebied van Queuing en Messaging-systemen
- Architecten - omdat alles een kader nodig heeft en dit kader van tijd tot tijd kan worden bijgewerkt. Big Data-architecten zouden Kafka als een goede investering in carrière beschouwen.
- Projectmanager is nodig als de bovenstaande professional aanwezig is voor een beter beheer van de middelen. Dus, hogere posities zijn ook beschikbaar voor de managementprofessionals op het gebied van Kafka.
Waarom Kafka gebruiken?
Voor het volgen en manipuleren van gegevens volgens de zakelijke behoefte heeft Kafka wereldwijd de voorkeur. Het biedt de mogelijkheid om gegevens in realtime te streamen met realtime analyses. Het is snel, schaalbaar en duurzaam en ontworpen als fouttolerantie. Er zijn meerdere gebruiksscenario's op internet waar u kunt zien waarom JMS, RabbitMQ en AMQP niet eens worden gebruikt om mee te werken, omdat het nodig is om een enorm volume en reactievermogen te bedienen.
Het heeft een hoge doorvoer, betrouwbare installatie met replicatiekarakteristieken, waardoor het een voorkeurskeuze is om op IoT-sensoren te werken.
Compatibiliteit is een andere reden om het te gebruiken en het wereldwijd aanvaardbaar te maken. Het kan eenvoudig worden geconfigureerd om te werken met de hieronder vermelde applicatie. Deze combinatie is voor veel bedrijven van levensbelang om te groeien en te overleven (omdat het tijd en geld bespaart).
- Fluim
- Vonken streamen
- HBase
- Spark voor realtime opname, verwerking en analyse van gegevens.
- Het wordt gebruikt om Hadoop BigData te voeden
strekking
Het doet het over de hele wereld geweldig. Nou, we zeggen dit niet eerder statistieken. Laten we eens kijken -
Salarisstatistieken voor Kafka-professionals - PayScale
- Software Engineer - $ 109.825
- Gegevensingenieur - $ 109.580
- Ontwikkelaars - $ 81, 182
- Senior Data Engineer - $ 127, 836
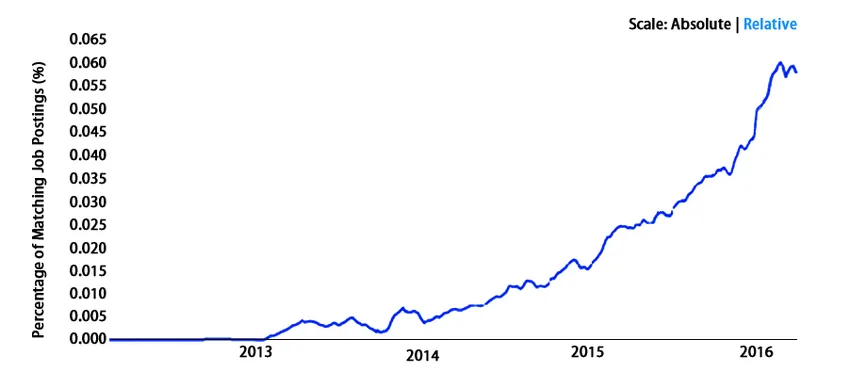
Conclusie
Momenteel is Kafka de de facto standaard geworden als het gaat om realtime data-analyse met de hoogste precisie in microseconden. We hebben onze inzichten gepresenteerd op het gebied van gegevens en details ter ondersteuning van Kafka-technologieën. Er zijn verschillende grote bedrijven die dagelijks gegevens gebruiken, en daarbij hebben ze professionals nodig om deze enorme datasets te benutten. Met Kafka kan men er zeker van zijn hun carrière te leiden in een BigData-analyse
Aanbevolen artikelen
Dit is een gids geweest voor Wat is Kafka. Hier hebben we de werking, reikwijdte, carrièregroei en voordelen van Kafka besproken. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Wat is Apache?
- Wat is Big data en Hadoop?
- Wat is Azure?
- Wat is big data-technologie?
- Kafka vs Spark | Top 5 verschillen
- Overzicht en toptoepassingen van Kafka
- Kafka vs Kinesis | 5 verschillen met infographics