

Inleiding tot AdaBoost-algoritme
AdaBoost-algoritme kan worden gebruikt om de prestaties van elk algoritme voor machine learning te verbeteren. Machine Learning is een krachtig hulpmiddel geworden dat voorspellingen kan doen op basis van een grote hoeveelheid gegevens. Het is de laatste tijd zo populair geworden dat de toepassing van machine learning te vinden is in onze dagelijkse activiteiten. Een bekend voorbeeld hiervan is het krijgen van suggesties voor producten tijdens het online winkelen op basis van de artikelen die in het verleden door de klant zijn gekocht. Machine Learning, vaak aangeduid als voorspellende analyse of voorspellende modellering, kan worden gedefinieerd als het vermogen van computers om te leren zonder expliciet te worden geprogrammeerd. Het maakt gebruik van geprogrammeerde algoritmen om invoergegevens te analyseren om de uitvoer binnen een acceptabel bereik te voorspellen.
Wat is AdaBoost-algoritme?
In machine learning kwam boosting voort uit de vraag of een set zwakke classifiers kon worden omgezet in een sterke classifier. Zwakke leerling of classificeerder is een leerling die beter is dan willekeurig raden en dit zal robuust zijn in overpassing zoals in een grote reeks zwakke classificatoren, waarbij elke zwakke classificeerder beter is dan willekeurig. Als zwakke classificator wordt over het algemeen een eenvoudige drempelwaarde voor een enkele functie gebruikt. Als het element boven de drempel ligt dan voorspeld, hoort het bij positief, anders hoort het bij negatief.
AdaBoost staat voor 'Adaptive Boosting' dat zwakke leerlingen of voorspellers transformeert naar sterke voorspellers om classificatieproblemen op te lossen.
Voor classificatie kan de definitieve vergelijking als volgt worden gezet: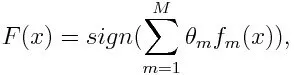
Hier geeft f m de mde zwakke classificator aan en vertegenwoordigt m het overeenkomstige gewicht.
Hoe AdaBoost-algoritme werkt?
AdaBoost kan worden gebruikt om de prestaties van machine learning-algoritmen te verbeteren. Het wordt het beste gebruikt bij zwakke leerlingen en deze modellen bereiken een hoge nauwkeurigheid boven willekeurige kans op een classificatieprobleem. De meest gebruikte algoritmen met AdaBoost zijn beslissingsbomen met niveau één. Een zwakke leerling is een classificator of voorspeller die relatief slecht presteert wat betreft nauwkeurigheid. Het kan ook worden geïmpliceerd dat de zwakke leerlingen eenvoudig te berekenen zijn en veel gevallen van algoritmen worden gecombineerd om een sterke classificator te creëren door middel van boosting.
Als we een gegevensset met n aantal punten nemen, en rekening houden met het onderstaande
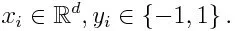
-1 staat voor negatieve klasse en 1 geeft positief aan. Het wordt geïnitialiseerd zoals hieronder, het gewicht voor elk gegevenspunt als:
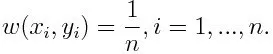
Als we iteratie van 1 tot M voor m overwegen, krijgen we de onderstaande uitdrukking:
Eerst moeten we de zwakke classificator met de laagste gewogen classificatiefout selecteren door de zwakke classificatoren in de gegevensset te passen.
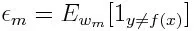
Bereken vervolgens het gewicht voor de mde zwakke classificator zoals hieronder:
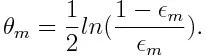
Het gewicht is positief voor elke classificatie met een nauwkeurigheid van meer dan 50%. Het gewicht wordt groter als de classificeerder nauwkeuriger is en wordt negatief als de classificeerder een nauwkeurigheid van minder dan 50% heeft. De voorspelling kan worden gecombineerd door het teken om te keren. Door het teken van de voorspelling om te keren, kan een classificeerder met een nauwkeurigheid van 40% worden omgezet in een nauwkeurigheid van 60%. De classifier draagt dus bij aan de uiteindelijke voorspelling, hoewel deze slechter presteert dan willekeurig raden. De uiteindelijke voorspelling zal echter geen enkele bijdrage leveren of informatie krijgen van de classificator met precies 50% nauwkeurigheid. De exponentiële term in de teller is altijd groter dan 1 voor een verkeerd geclassificeerde case van de positief gewogen classificator. Na iteratie worden de verkeerd geclassificeerde gevallen bijgewerkt met grotere gewichten. De negatief gewogen classificaties gedragen zich op dezelfde manier. Maar er is een verschil dat nadat het teken is omgekeerd; de juiste classificaties zouden oorspronkelijk worden omgezet in verkeerde classificatie. De uiteindelijke voorspelling kan worden berekend door rekening te houden met elke classificator en vervolgens de som van hun gewogen voorspelling uit te voeren.
Bijwerken van het gewicht voor elk gegevenspunt zoals hieronder:
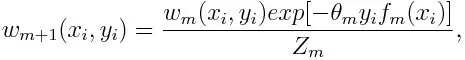
Z m is hier de normalisatiefactor. Het zorgt ervoor dat de som van alle instantiegewichten gelijk wordt aan 1.
Waarvoor wordt AdaBoost-algoritme gebruikt?
AdaBoost kan worden gebruikt voor gezichtsdetectie omdat dit het standaardalgoritme lijkt voor gezichtsdetectie in afbeeldingen. Het maakt gebruik van een afwijzingscascade bestaande uit vele lagen classificaties. Wanneer het detectievenster op geen enkele laag als een gezicht wordt herkend, wordt het afgewezen. De eerste classificator in het venster negeert het negatieve venster en beperkt de computerkosten tot een minimum. Hoewel AdaBoost de zwakke classificaties combineert, worden de principes van AdaBoost ook gebruikt om de beste functies te vinden voor gebruik in elke laag van de cascade.
Voors en tegens van AdaBoost Algorithm
Een van de vele voordelen van het AdaBoost-algoritme is dat het snel, eenvoudig en gemakkelijk te programmeren is. Het heeft ook de flexibiliteit om te worden gecombineerd met elk machine learning-algoritme en het is niet nodig om de parameters af te stemmen behalve T. Het is uitgebreid tot leerproblemen die verder gaan dan binaire classificatie en het is veelzijdig omdat het kan worden gebruikt met tekst of numeriek gegevens.
AdaBoost heeft ook weinig nadelen, zoals empirisch bewijs en bijzonder kwetsbaar voor uniform geluid. Zwakke classificaties die te zwak zijn, kunnen leiden tot lage marges en overfitting.
Voorbeeld van AdaBoost-algoritme
We kunnen een voorbeeld overwegen van de toelating van studenten tot een universiteit waar ze worden toegelaten of geweigerd. Hier kunnen de kwantitatieve en kwalitatieve gegevens worden gevonden uit verschillende aspecten. Het resultaat van de toelating dat ja / nee kan zijn, kan bijvoorbeeld kwantitatief zijn, terwijl elk ander gebied, zoals vaardigheden of hobby's van studenten, kwalitatief kan zijn. We kunnen gemakkelijk de juiste classificatie van trainingsgegevens bedenken, beter dan de kans op omstandigheden zoals of de student goed is in een bepaald onderwerp, dan wordt hij / zij toegelaten. Maar het is moeilijk om een zeer nauwkeurige voorspelling te vinden en dan komen zwakke leerlingen in beeld.
Conclusie
AdaBoost helpt bij het kiezen van de trainingsset voor elke nieuwe classifier die wordt getraind op basis van de resultaten van de vorige classifier. Ook bij het combineren van de resultaten; het bepaalt hoeveel gewicht moet worden gegeven aan het voorgestelde antwoord van elke classificeerder. Het combineert de zwakke leerlingen om een sterke te maken om classificatiefouten te corrigeren, wat ook het eerste succesvolle boosting-algoritme is voor binaire classificatieproblemen.
Aanbevolen artikelen
Dit is een gids voor AdaBoost-algoritme geweest. Hier hebben we het concept, gebruik, werken, voor- en nadelen met voorbeeld besproken. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Naïef Bayes-algoritme
- Sollicitatievragen voor Social Media Marketing
- Link Building Strategies
- Social Media Marketing Platform