

Meer informatie over het verschil tussen statistiek en machinaal leren
Machine learning wordt effectief gebruikt op verschillende gebieden, zoals fraudedetectie, zoekresultaten op internet, realtime advertenties op webpagina's en mobiele apparaten, tekstgebaseerde sentimentanalyse, kredietscore en de beste aanbiedingen, voorspelling van uitval van apparatuur, nieuwe prijsmodellen, netwerkinbraakdetectie, patroon- en beeldherkenning en e-mail spamfiltering onder andere velden. Statistiek wordt gedefinieerd als de studie van verzameling, analyse, interpretatie, presentatie en organisatie van gegevens. Wanneer statistieken worden toegepast op een wetenschappelijk, industrieel of maatschappelijk probleem, begint het proces meestal met het bepalen van een statistische populatie of een statistisch modelproces.
Statistieken versus machinaal leren -
Gegevens veranderen en evolueren voortdurend. Maar het is heel belangrijk om je aan deze veranderingen aan te passen, omdat data een cruciaal aspect is van de groei van bedrijven over de hele wereld.
Gegevens worden gedefinieerd als eenvoudige feiten en statistieken die worden verzameld tijdens de dagelijkse activiteiten van een merk / bedrijf. Hoewel bijna alle soorten bedrijven gegevens verzamelen, is het erg belangrijk dat merken dat begrijpen.
Zonder inzichten en kennis uit de gegevens te kunnen afleiden, worden ze volledig nutteloos. Dat is de reden waarom, zelfs als bedrijven veel informatie en gegevens hebben, ze soms verliezen omdat ze het niet kunnen waarnemen.
Sinds de oprichting verzamelen bedrijven veel informatie en gegevens over verschillende dingen, zoals klantinformatie, productmarkeringen, zorgen van partners en feedback van werknemers.
Deze gegevens en informatie kunnen effectief worden gebruikt om een uitgebreid scala aan zakelijke functies vast te leggen en te meten, zowel extern als intern. Op zichzelf is gegevens niet erg informatief, maar het is een basis waarop bedrijven toekomstige beslissingen kunnen nemen en ook succesvolle strategieën kunnen ontwikkelen.
Klanten vormen de basis waarop merken hun naam en waarde in de markt hebben gebouwd. Dat is de reden waarom klantgegevens van groot belang zijn, omdat merken hierdoor hun klanten op verschillende manieren kunnen verbeteren en begrijpen.
Gegevens zijn daarom de enige manier waarop bedrijven veel aspecten van bedrijfsfuncties begrijpen, zoals een aantal vragen, ontvangen inkomsten en ontvangen kosten.
Gegevens zijn daarom belangrijk voor merken om de mindset en verwachtingen van klanten te begrijpen. Al met al zijn gegevens een belangrijk element voor het verzekeren van blijvend succes en groei van elk bedrijf, vooral in deze competitieve tijd en tijden.
Het artikel over Statistieken versus Machine learning is als volgt gestructureerd -
- Statistieken versus machine learning infographics
- Wat is het verschil Statistieken versus machinaal leren?
- Een diepgaandere kijk op statistieken en het belang ervan in de samenleving
- Een meer diepgaande kijk op machine learning en het belang ervan in de samenleving
- Conclusie - Statistieken versus machinaal leren
Statistieken versus machine learning infographics
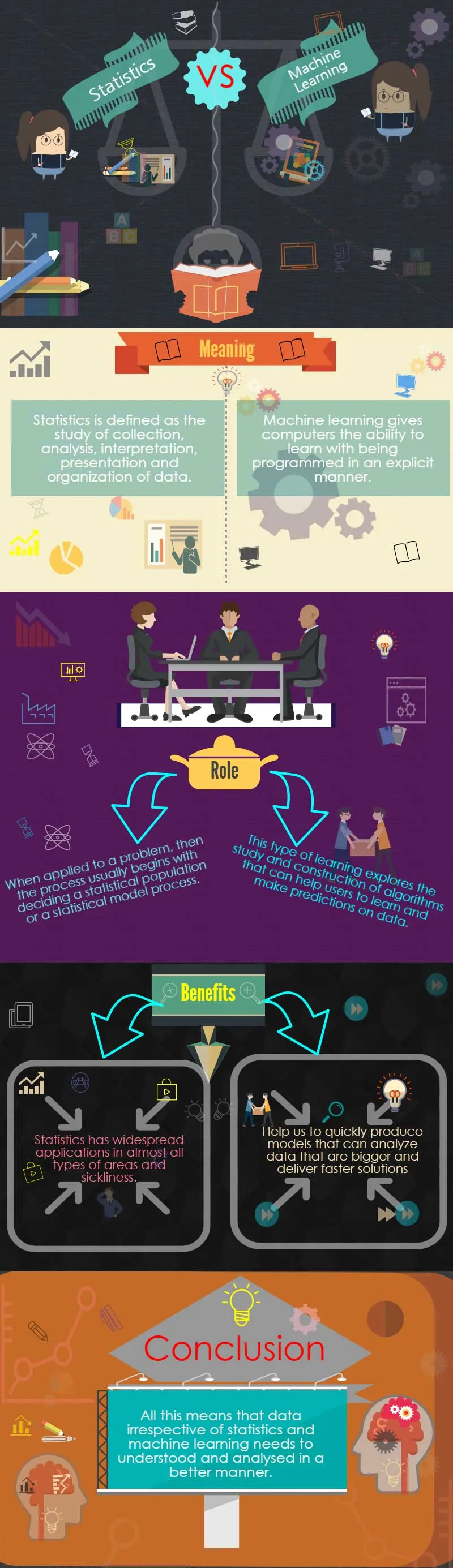
Zijn gegevens en informatie hetzelfde? Wat is het verschil Statistieken versus machinaal leren?
Gegevens en informatie zijn twee verschillende dingen. Hoewel gegevens ruwe feiten en statistieken zijn, is informatie dezelfde gegevens die op nauwkeurige en tijdige wijze worden gepresenteerd.
Verder is informatie specifiek en georganiseerd, meestal met het doel context en begrip te geven aan een bepaald aspect van het functioneren van een merk. Een andere manier waarop informatie verschilt van gegevens, is dat merken via de informatie de juiste beslissingen kunnen nemen en campagnes kunnen maken die creatief, effectief en aantrekkelijk zijn.
Daarom is informatie zo belangrijk omdat merken hierdoor beslissingen kunnen nemen die door het management kunnen worden gebruikt om zichzelf echt te machtigen.
Daarom streven merken ernaar om informatie over klanten en klanten te verzamelen, zodat ze op een effectieve manier met hen kunnen communiceren. Dit alles gezegd zijnde, is het belangrijk om te onthouden dat de werkelijke waarde van informatie ligt in het vermogen om richting te geven aan het bedrijf.
Als er bijvoorbeeld volgens de door de klanten verstrekte informatie een gebrek aan klanttevredenheid is, is het alleen nuttig als het merk deze perceptie verandert door een betere waarde te bieden aan hun producten en diensten.
Kortom, het informatieproces moet deel uitmaken van een breder beoordelingsproces binnen de bedrijven, zodat het hen kan helpen betere en winstgevendere resultaten te produceren.
Informatie kan daarom worden verzameld en geanalyseerd op verschillende manieren, namelijk machinaal leren en statistieken.
Van personen die in een land wonen tot atomen in een kristal, de bevolking kan van verschillende soorten zijn. Statistieken hebben betrekking op alle aspecten van gegevens, zoals de planning van gegevensverzameling tot experimenten, en zijn een gevarieerd en uitgebreid terrein.
Machine learning daarentegen is een deelgebied van de informatica dat is voortgekomen uit de studie van computationele leertheorie in kunstmatige intelligentie en patroonherkenning.
Arthur Samuel definieerde in 1959 machine learning als het vakgebied dat computers de mogelijkheid geeft om te leren door op een expliciete manier te worden geprogrammeerd.
Dit type leren onderzoekt en bestudeert algoritmen die gebruikers kunnen helpen leren en voorspellingen doen over gegevens. Dergelijke algoritmen werken volgens een modelcreatie en worden gebruikt om datagestuurde voorspelling te doen in plaats van statische programma-instructies te volgen.
Aanbevolen cursussen
- Cursus over IP-routing
- Trainingscursussen hacken
- Cursus op RMAN
- Online certificeringcursus in Python

Een meer diepgaande blik op statistieken en machine learning
Statistiek speelt een zeer belangrijke rol in bijna elk gebied van menselijke activiteit. Van het helpen bepalen van de per hoofd van de bevolking van een land tot de arbeidsparticipatie tot het aantal medische / opleidingsfaciliteiten dat nodig is in een regio, statistieken en machine learning spelen een zeer belangrijke rol in het functioneren van de menselijke samenleving.
In de huidige tijd neemt statistieken een zeer belangrijke en kritische positie in op een aantal gebieden, waaronder handel, handel, psychologie, chemie, plantkunde, astronomie en nog vele andere.
Dit komt omdat statistieken als veld wijdverspreide toepassingen hebben in bijna alle soorten gebieden en bij ziekte. Hier zijn enkele belangrijke gebieden waarop Statistieken en Machine learning kunnen worden toegepast voor het verzamelen van betere informatie en inzichten.
- Business: Statistieken spelen een zeer belangrijke en cruciale rol op het gebied van business. Dit komt omdat merken en bedrijven uiterst concurrerend zijn, waardoor het moeilijk is voor merken om hun verwachtingen en wensen van klanten voor te blijven. Het is daarom belangrijk dat merken snel beslissingen nemen zodat ze betere beslissingen kunnen nemen. Statistieken kunnen merken helpen de verwachtingen van de klant te begrijpen en daarmee hun vraag en aanbod op een effectieve manier in evenwicht te brengen. Dit betekent dat veel beslissingen van het merk afhankelijk zijn van goede statistische beslissingen en inzichten.
- Economie: een ander belangrijk gebied waar statistieken een belangrijke rol spelen in de economie. Dit komt omdat statistieken grotendeels afhankelijk zijn van statistieken. Dit komt omdat nationale inkomensrekeningen belangrijke indicatoren zijn voor economen en bestuurders. Statistische methoden worden gebruikt voor het opstellen van deze rekeningen en zelfs voor het verzamelen en analyseren van gegevens. De relatie tussen vraag en aanbod wordt bestudeerd door statistische analyse en bijna elk aspect van de economie vereist een groot en ingewikkeld begrip van statistieken.
- Wiskunde: statistiek is een integraal onderdeel van de volledig natuurlijke en sociale wetenschappen. De methoden van natuurwetenschappen zijn betrouwbaar, maar hun conclusies zijn soms niet zo waarschijnlijk omdat ze gebaseerd zijn op onvolledig bewijs. Statistische hulp bij het nauwkeurig beschrijven van deze metingen. Veel statische methoden zoals waarschijnlijkheidsgemiddelden, dispersies, schattingen zijn een integraal onderdeel van de wiskunde en worden vaak in dit veld gebruikt.
- Bankieren: een ander gebied waar statistieken een belangrijke rol spelen bij bankieren. Banken hebben statistieken nodig om een aantal redenen en doeleinden. Bijna alle banken werken volgens het principe dat wanneer een van hun klanten wat geld in hun bank investeert, ze dit enige tijd in hun bank zullen houden en het niet zullen opnemen. Door winst te maken met deze deposito's, verdient de bank winst en dit is de belangrijkste bron van inkomsten. De bankiers gebruiken statistische benaderingen op basis van waarschijnlijkheid om het aantal deposanten en hun vorderingen voor een bepaalde dag te schatten, waardoor ze op een soepele en effectieve manier kunnen functioneren.
- Staatsmanagement: statistiek is een ander gebied dat essentieel is voor de groei en ontwikkeling van elk land. Dit komt omdat statistieken de basis vormen voor het opstellen van beleid in het land. Daarom worden statistische gegevens veel gebruikt voor het nemen van administratieve beslissingen. Als de overheid bijvoorbeeld de loonschalen van werknemers wil verhogen om hen te helpen hun levensstandaard te verhogen, kan de overheid via statistieken een stijging van de kosten van levensonderhoud vinden. Bovendien is de voorbereiding van federale en provinciale overheidsbegrotingen ook afhankelijk van statistieken omdat het de ambtenaren helpt om de verwachte uitgaven en inkomsten uit verschillende bronnen te schatten. Statistieken zijn dus erg belangrijk om overheden te helpen hun taken op een vlotte manier uit te voeren.

Een meer diepgaande kijk op machine learning en het belang ervan in de samenleving
Computers en laptops hebben de hele wereld veroverd en hebben het leven van veel mensen drastisch veranderd. Laten we een situatie voor een minuut visualiseren. Laten we proberen een wereld zonder computers te bedenken.
Als dit zou gebeuren, zouden mensen op medisch gebied niet veel genezing van ziekten hebben gevonden, omdat computers een cruciale rol hebben gespeeld in het proces om medische professionals te helpen beter inzicht te krijgen in de wereld van ziekten en gezondheid.
Nogmaals, films zoals Toy Story en Jurassic Park zouden niet mogelijk zijn geweest zonder computers omdat deze films gebruik hebben gemaakt van computergraphics en animaties.
Apotheken hebben het moeilijk om bij te houden welke medicijnen ze aan hun patiënten moeten geven. Het tellen van stemmen zou bijna onmogelijk zijn zonder computers en nog belangrijker was het verkennen van de ruimte nog steeds een verre droom voor alle liefhebbers van ruimte.
Vanwege het groeiende belang van computers hebben computertechnologieën een nog grotere rol gekregen en dit heeft ertoe geleid dat machines sneller en sneller complexe wiskundige berekeningen kunnen toepassen op big data.
Enkele van de veel gepubliceerde voorbeelden van machine learning-applicaties die tegenwoordig wereldwijd erg populair zijn, zijn onder meer:
- De essentie van machine learning is de extreem populaire zelfrijdende auto van Google
- Online aanbevelingsaanbiedingen die gepersonaliseerd zijn voor platforms zoals Amazon en Netflix zijn het resultaat van machine learning-applicaties die nu geschikt zijn om het dagelijkse menselijke gedrag te begrijpen
- Inzicht in klantgedrag op Twitter voor merken en nu machine learning met het creëren van taalregels helpt merken hun klanten in het publieke domein te begrijpen en te versterken
- Fraudedetectie is een belangrijk gebied waar machine learning merken helpt om veilig en effectief te zijn op alle platforms
Tegenwoordig is er een groeiende interesse in machine learning omdat vandaag de dag de groeiende volumes en variëteiten van beschikbare gegevens, computationele verwerking hebben geleid tot een behoefte aan goedkopere en krachtige methoden voor gegevensanalyse.
Dit betekent dat machine learning ons kan helpen om snel modellen te produceren die grotere gegevens kunnen analyseren en snellere oplossingen kunnen leveren die accuraat en effectief zijn, zelfs op grote schaal.
Dit alles betekent dat hoogwaardige voorspellingen economieën en merken kunnen helpen om betere en slimmere beslissingen te nemen, niet alleen zonder menselijke tussenkomst, maar ook in realtime.
Merken hebben snel bewegende modelleringsstromen nodig om aan de eisen van de markt te kunnen voldoen en ze kunnen dit op een effectieve manier doen door gebruik te maken van machine learning.
Hoewel mensen over het algemeen een of twee goede modellen per week kunnen maken, kan machine learning duizenden modellen per week maken, waardoor merken ook op de lange termijn effectiever en beter worden.
Machine learning is daarom heel anders dan datastatistieken. Eenvoudig gezegd, terwijl machine learning dezelfde algoritmen en technieken gebruikt, is er een groot verschil tussen deze twee statistieken versus technieken voor machine learning.
Terwijl datamining eerder onbekende patronen en kennis ontdekt, wordt machine learning gebruikt om bekende patronen en kennis te reproduceren.
Deze patronen worden vervolgens automatisch toegepast op andere gegevens en vervolgens gebruikt om de betrokken mensen te helpen betere beslissingen en acties te nemen.
Met het toegenomen gebruik van computers, ontwikkelen datatechnieken en machine learning zich ook snel om te voldoen aan de behoeften van merken en bedrijven in verschillende sectoren.
Neurale netwerken worden al lang gebruikt in datamining-toepassingen en nu met de kracht van computers, is het mogelijk om meerdere neurale netwerken met vele lagen te creëren. In machine learning lingo worden deze diepe neurale netwerken genoemd.
Conclusie - Statistieken versus machinaal leren
Dit alles betekent dat gegevens ongeacht statistieken versus machinaal leren op een betere manier moeten worden begrepen en geanalyseerd. Dit komt omdat data-inzichten van cruciaal belang zijn voor het succes en falen van merken in verschillende categorieën en het beleggen hiervan is een van de belangrijkste vereisten van alle soorten bedrijven.
Aanbevolen artikelen
Dus hier zijn enkele artikelen die u zullen helpen om meer details te krijgen over de Statistieken versus Machine learning En ook over de Statistieken en Machine learning, dus ga gewoon via de link die hieronder wordt gegeven.
- Machine Learning versus Statistieken
- Carrière in de statistiek
- Belangrijke stap naar de levensstijl van investeringsbankiers
- Statistiek Interview Vragen | Handig en meest gevraagd