
Wat is lineaire regressie in R?
Lineaire regressie is het populairste en meest gebruikte algoritme op het gebied van statistiek en machine learning. Lineaire regressie is een modelleringstechniek om de relatie tussen invoer- en uitvoervariabelen te begrijpen. Hier moeten variabelen numeriek zijn. Lineaire regressie komt van het feit dat de uitvoervariabele een lineaire combinatie van invoervariabelen is. De uitvoer wordt meestal weergegeven door "y", terwijl de invoer wordt weergegeven door "x".
Lineaire regressie in R kan op twee manieren worden gecategoriseerd
-
Lineaire regressie
Dit is de regressie waarbij de uitgangsvariabele een functie is van een enkele ingangsvariabele. Weergave van eenvoudige lineaire regressie:
y = c0 + c1 * x1
-
Meerdere lineaire regressie
Dit is de regressie waarbij de uitgangsvariabele een functie is van een variabele met meerdere ingangen.
y = c0 + c1 * x1 + c2 * x2
In beide bovengenoemde gevallen zijn c0, c1, c2 de coëfficiënten die regressiegewichten vertegenwoordigen.
Lineaire regressie in R
R is een zeer krachtig statistisch hulpmiddel. Laten we dus kijken hoe lineaire regressie in R kan worden uitgevoerd en hoe de uitvoerwaarden kunnen worden geïnterpreteerd.
Laten we een dataset voorbereiden om lineaire regressie nu diepgaand uit te voeren en te begrijpen.
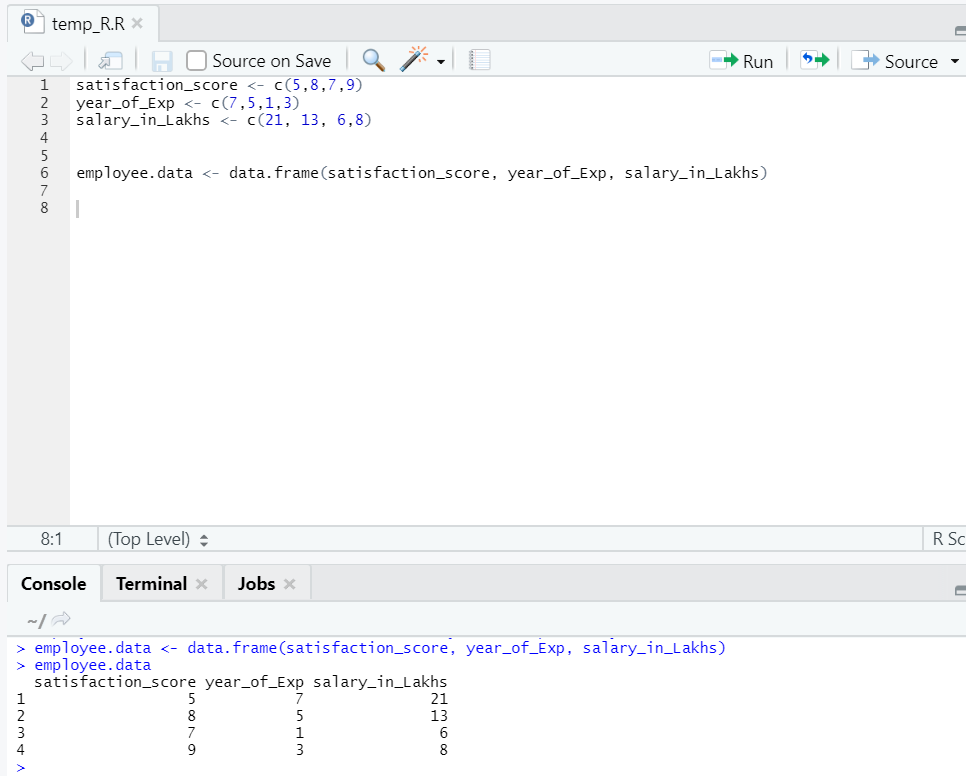
Nu hebben we een dataset, waarbij "tevredenheid_score" en "jaar_van_Exp" de onafhankelijke variabele zijn. "Salaris_in_lakhs" is de uitvoervariabele.
Verwijzend naar de bovenstaande gegevensset, is het probleem dat we hier willen aanpakken door lineaire regressie:
Schatting van het salaris van een werknemer, op basis van zijn jaar van ervaring en tevredenheidsscore in zijn bedrijf.
R-code van lineaire regressie:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
De uitvoer van de bovenstaande code is:
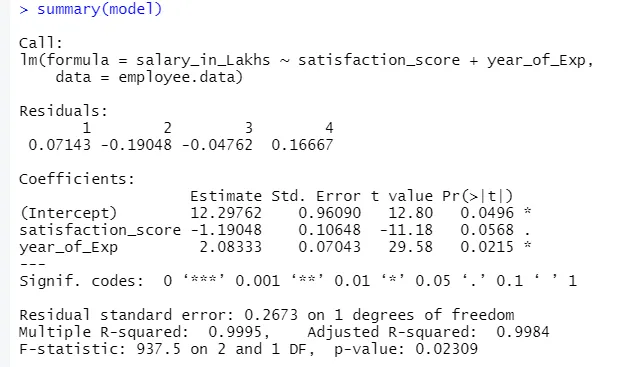
De formule van regressie wordt
Y = 12.29-1.19 * tevredenheid_score + 2.08 × 2 * jaar_van_Exp
In het geval heeft men meerdere ingangen naar het model.
Dan kan R-code zijn:
model <- lm (salaris_in_Lakhs ~., data = medewerker.data)
Als iemand echter variabele uit meerdere invoervariabelen wil selecteren, zijn er meerdere technieken beschikbaar zoals "Achterwaartse eliminatie", "Voorwaartse selectie" enz. Om dat ook te doen.
Interpretatie van lineaire regressie in R
Hieronder zijn enkele interpretaties van lineaire regressie in r die als volgt zijn:
1.Residuals
Dit verwijst naar het verschil tussen de werkelijke respons en de voorspelde respons van het model. Dus voor elk punt is er één werkelijke reactie en één voorspelde reactie. Restanten zullen dus evenveel zijn als waarnemingen. In ons geval hebben we vier observaties, dus vier residuen.

2.Coefficients
Als we verder gaan, vinden we de coëfficiëntensectie, die het onderscheppen en de helling afbeeldt. Als men het salaris van een werknemer wil voorspellen op basis van zijn ervaring en tevredenheidsscore, moet men een modelformule ontwikkelen op basis van helling en onderschepping. Deze formule helpt u bij het voorspellen van het salaris. De onderschepping en helling helpen een analist om het beste model te vinden dat geschikt is voor datapunten.
Helling: geeft de steilheid van de lijn weer.
Onderscheppen: de locatie waar de lijn de as snijdt.
Laten we begrijpen hoe formulevorming wordt gedaan op basis van helling en onderschepping.
Zeg intercept is 3 en de helling is 5.
De formule is dus y = 3 + 5x . Dit betekent dat als x met een eenheid wordt verhoogd, y met 5 wordt verhoogd.
a.Coefficient - schatting
Hierin geeft het onderscheppen de gemiddelde waarde van de uitvoervariabele aan, wanneer alle invoer nul wordt. Dus in ons geval zal het salaris in lakhs 12.29Lakhs zijn, aangezien het gemiddelde gezien de tevredenheidsscore en de ervaring nul is. Hier vertegenwoordigt de helling de verandering in de uitvoervariabele met een eenheidsverandering in de invoervariabele.
b.Coefficient - Standaardfout
De standaardfout is de schatting van de fout die we kunnen krijgen bij het berekenen van het verschil tussen de werkelijke en voorspelde waarde van onze responsvariabele. Op zijn beurt vertelt dit over het vertrouwen voor het koppelen van input- en outputvariabelen.
c.Coefficient - t waarde
Deze waarde geeft het vertrouwen om de nulhypothese te verwerpen. Hoe groter de waarde weg van nul, des te groter het vertrouwen om de nulhypothese te verwerpen en de relatie tussen output en inputvariabele vast te stellen. In ons geval is de waarde ook weg van nul.
d.Coefficient - Pr (> t)
Dit acroniem geeft in feite de p-waarde weer. Hoe dichter het bij nul ligt, hoe gemakkelijker we de nulhypothese kunnen afwijzen. De lijn die we in ons geval zien, deze waarde is bijna nul, we kunnen zeggen dat er een verband bestaat tussen salarispakket, tevredenheidsscore en jaar van ervaringen.

Resterende standaardfout
Dit geeft de fout weer in de voorspelling van de responsvariabele. Hoe lager het is, hoe hoger de nauwkeurigheid van het model.
Meerdere R-kwadraat, aangepast R-kwadraat
R-kwadraat is een zeer belangrijke statistische maat om te begrijpen hoe dicht de gegevens in het model passen. Vandaar dat in ons geval hoe goed ons model dat lineaire regressie is, de dataset vertegenwoordigt.
R-kwadraatwaarde ligt altijd tussen 0 en 1. Formule is:

Hoe dichter de waarde bij 1, hoe beter het model de datasets en de variantie ervan beschrijft.
Wanneer echter meer dan één ingangsvariabele in beeld komt, heeft de aangepaste R-kwadraatwaarde de voorkeur.
F-Statistiek
Het is een sterke maatregel om de relatie tussen invoer en responsvariabele te bepalen. Hoe groter de waarde dan 1, des te groter is het vertrouwen in de relatie tussen de invoer- en uitvoervariabele.
In ons geval is dit '937.5', dat relatief groter is gezien de grootte van de gegevens. Daarom wordt de afwijzing van de nulhypothese eenvoudiger.
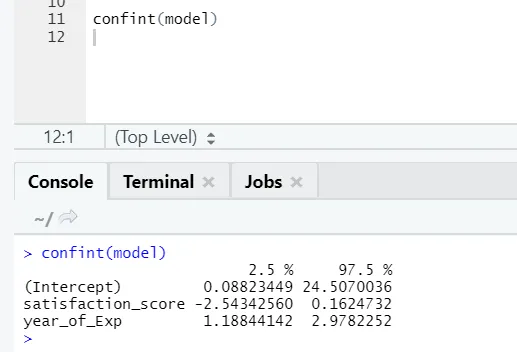
Als iemand het betrouwbaarheidsinterval voor de coëfficiënten van het model wil zien, is dit de manier om dit te doen: -
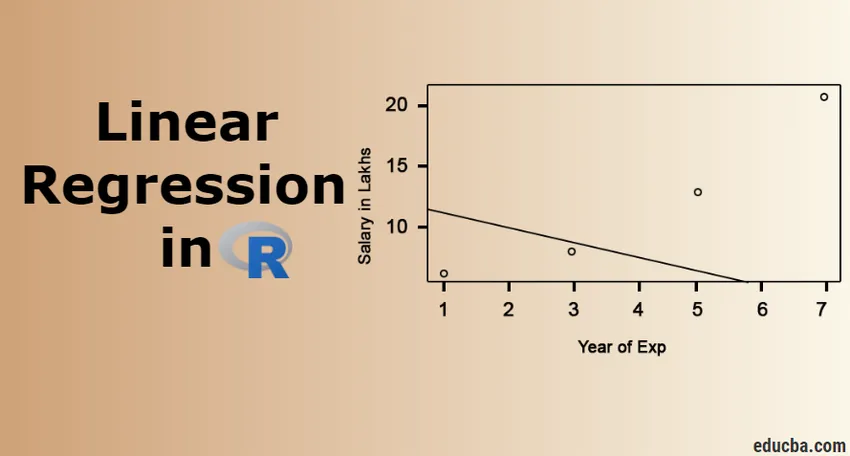
Visualisatie van regressie
R-code:
plot (salaris_in_Lakhs ~ tevredenheid_score + jaar_van_Exp, gegevens = medewerker.gegevens)
abline (model)
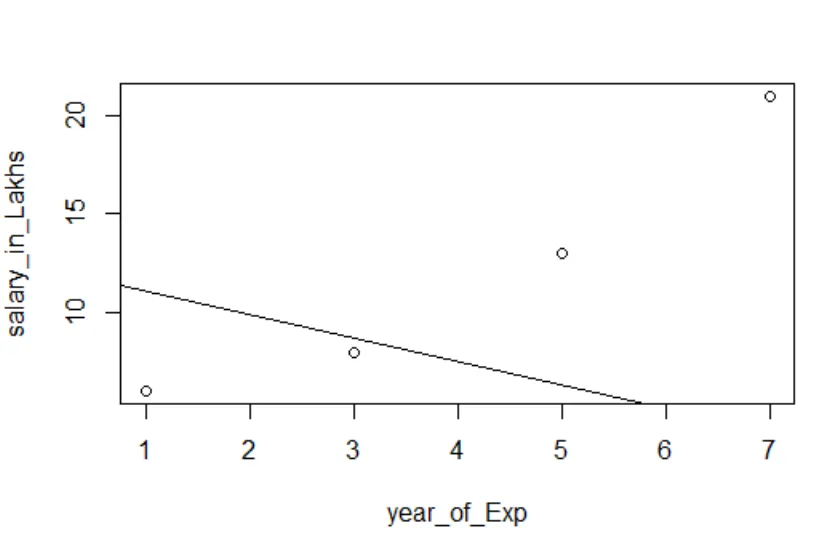
Het is altijd beter om meer en meer punten te verzamelen voordat u een model aanpast.
Conclusie - Lineaire regressie in R
Lineaire regressie is eenvoudig, gemakkelijk te passen, gemakkelijk te begrijpen en toch zeer krachtig model. We hebben gezien hoe lineaire regressie op R. kan worden uitgevoerd. We hebben ook geprobeerd de resultaten te interpreteren, wat u kan helpen bij de optimalisatie van het model. Zodra men vertrouwd raakt met eenvoudige lineaire regressie, zou men meerdere lineaire regressie moeten proberen. Samen met dit, omdat lineaire regressie gevoelig is voor uitschieters, moet men erin kijken, alvorens direct in de aanpassing aan lineaire regressie te springen.
Aanbevolen artikelen
Dit is een gids voor lineaire regressie in R. Hier hebben we besproken wat is lineaire regressie in R? categorisatie, visualisatie en interpretatie van R. U kunt ook door onze andere voorgestelde artikelen gaan voor meer informatie -
- Voorspellende modellen
- Logistieke regressie in R
- Beslisboom in R
- R Interviewvragen
- Topverschillen van regressie versus classificatie
- Handleiding voor beslissingsboom in machinaal leren
- Lineaire regressie versus logistieke regressie | Topverschillen