
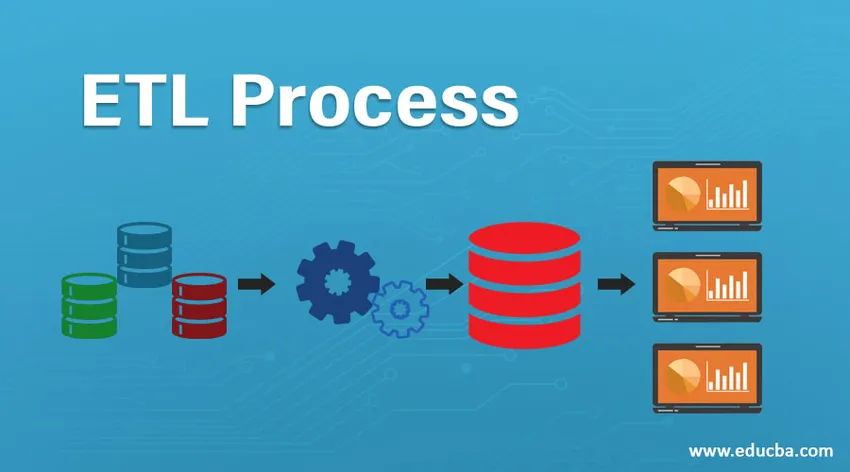
Introductie van het ETL-proces
ETL is een van de belangrijke processen die Business Intelligence vereist. Business Intelligence vertrouwt op de gegevens die zijn opgeslagen in datawarehouses waaruit veel analyses en rapporten worden gegenereerd die helpen bij het bouwen van effectievere strategieën en leiden tot tactische en operationele inzichten en besluitvorming.
ETL verwijst naar het proces Extraheren, Transformeren en Laden. Het is een soort gegevensintegratiestap waarbij gegevens uit verschillende bronnen worden geëxtraheerd en naar gegevensmagazijnen worden verzonden. Gegevens worden uit verschillende bronnen geëxtraheerd en worden eerst omgezet in een specifiek formaat volgens bedrijfsvereisten. Verschillende hulpmiddelen die helpen bij het uitvoeren van deze taken zijn -
- IBM DataStage
- Abinitio
- Informatica
- Tableau
- Talend
ETL-proces
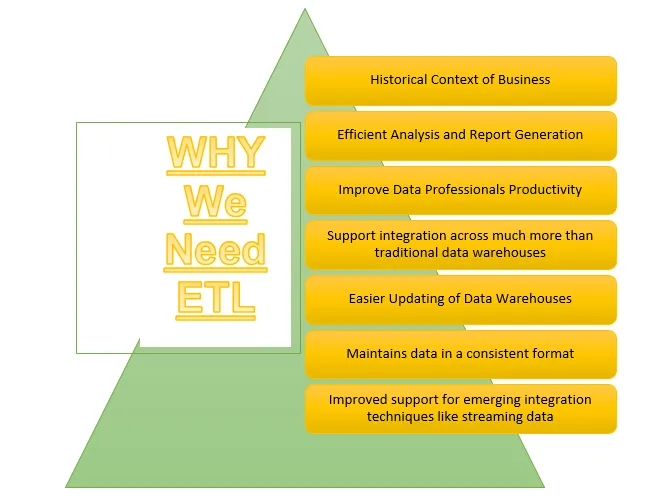
Hoe werkt het?
Het ETL-proces is een 3-stappenproces dat begint met het extraheren van de gegevens uit verschillende gegevensbronnen en vervolgens ruwe gegevens ondergaat verschillende transformaties om het geschikt te maken voor opslag in gegevensmagazijn en het in gegevensmagazijnen in het vereiste formaat te laden en klaar te maken voor analyse.
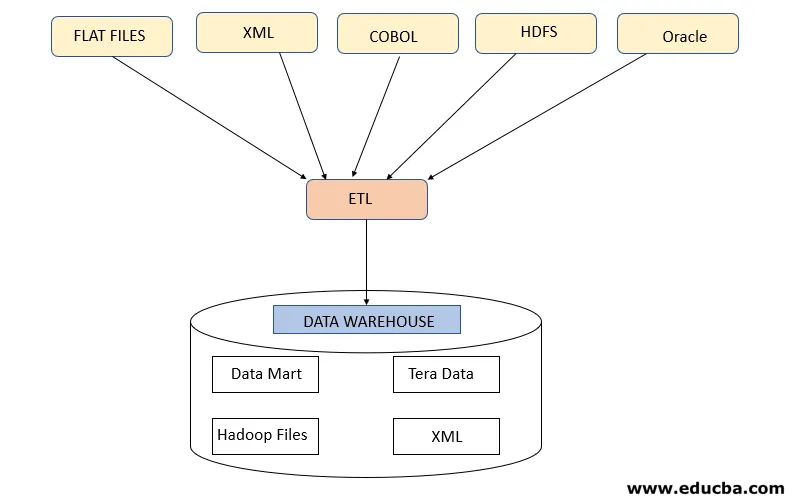
Stap 1: Extraheren
Deze stap verwijst naar het ophalen van de vereiste gegevens uit verschillende bronnen die aanwezig zijn in verschillende formaten zoals XML, Hadoop-bestanden, Flat Files, JSON, enz. De geëxtraheerde gegevens worden opgeslagen in het verzamelgebied waar verdere transformaties worden uitgevoerd. Gegevens worden dus grondig gecontroleerd voordat ze naar datawarehouses worden verplaatst, anders wordt het een uitdaging om de wijzigingen in datawarehouses ongedaan te maken.
Er is een juiste gegevenskaart vereist tussen bron en doel voordat gegevens worden geëxtraheerd, omdat het ETL-proces moet samenwerken met verschillende systemen zoals Oracle, Hardware, Mainframe, realtime systemen zoals ATM, Hadoop, enz. Terwijl gegevens worden opgehaald uit deze systemen .
Opmerking - Maar men moet ervoor zorgen dat deze systemen tijdens de extractie niet worden aangetast.
Gegevensextractie-strategieën
- Volledige extractie: dit wordt gevolgd wanneer volledige gegevens uit bronnen in de datawarehouses worden geladen die aangeven dat een datawarehouse de eerste keer wordt gevuld of er geen strategie is opgesteld voor data-extractie.
- Gedeeltelijke extractie (met updatemelding): deze strategie is ook bekend als delta, waarbij alleen de gegevens die worden gewijzigd, worden geëxtraheerd en datawarehouses worden bijgewerkt
- Gedeeltelijke extractie (zonder updatemelding): deze strategie verwijst naar het extraheren van specifieke vereiste gegevens uit bronnen op basis van de belasting in de datawarehouses in plaats van het extraheren van volledige gegevens.
Stap 2: Transformeren
Deze stap is de belangrijkste stap van ETL. In deze stap worden veel transformaties uitgevoerd om gegevens gereed te maken voor laden in datawarehouses door onderstaande transformaties toe te passen: -
A. Basistransformaties: deze transformaties worden in elk scenario toegepast omdat ze basisbehoeften zijn tijdens het laden van de gegevens die uit verschillende bronnen zijn geëxtraheerd, in de datawarehouses
- Gegevens opschonen of verrijken: het verwijst naar het opschonen van de ongewenste gegevens uit het opslaggebied, zodat verkeerde gegevens niet worden geladen vanuit de datawarehouses.
- Filteren: hier filteren we de vereiste gegevens uit een grote hoeveelheid gegevens die aanwezig zijn volgens bedrijfsvereisten. Voor het genereren van verkooprapporten heeft men bijvoorbeeld alleen verkooprecords nodig voor dat specifieke jaar.
- Consolidatie: geëxtraheerde gegevens worden in het vereiste formaat geconsolideerd voordat ze in de datawarehouses worden geladen.4.
- Standaardisaties: gegevensvelden worden getransformeerd om ze in hetzelfde vereiste formaat te brengen, bijvoorbeeld, het gegevensveld moet worden opgegeven als MM / DD / JJJJ.
B. Geavanceerde transformaties: dit soort transformaties is specifiek voor de zakelijke vereisten.
- Samenvoegen: bij deze bewerking worden gegevens uit 2 of meer bronnen gecombineerd om gegevens te genereren met alleen gewenste kolommen met rijen die aan elkaar gerelateerd zijn
- Controle van gegevensdrempelvalidatie: waarden die in verschillende velden aanwezig zijn, worden gecontroleerd als ze correct zijn of niet, zoals een niet-bankrekeningnummer in geval van bankgegevens.
- Gebruik opzoekingen om gegevens samen te voegen: verschillende platte bestanden of andere bestanden worden gebruikt om de specifieke informatie te extraheren door daarop een opzoekbewerking uit te voeren.
- Complexe gegevensvalidatie gebruiken: veel complexe validaties worden alleen toegepast om geldige gegevens uit de bronsystemen te extraheren.
- Berekende en afgeleide waarden: verschillende berekeningen worden toegepast om de gegevens om te zetten in bepaalde vereiste informatie
- Duplicatie: dubbele gegevens afkomstig van de bronsystemen worden geanalyseerd en verwijderd voordat deze in de datawarehouses worden geladen.
- Sleutelherstructurering: in het geval van het langzaam vastleggen van gegevens, moeten verschillende vervangende sleutels worden gegenereerd om de gegevens in het vereiste formaat te structureren.
Opmerking - MPP-Massive Parallel Processing wordt soms gebruikt om een aantal basisbewerkingen uit te voeren, zoals filteren of opschonen van gegevens in het opslaggebied om een grote hoeveelheid gegevens sneller te verwerken.
Stap 3: laden
Deze stap verwijst naar het laden van de getransformeerde gegevens in het datawarehouse van waaruit het kan worden gebruikt om veel analysebeslissingen en rapportage te genereren.
1. Eerste belasting: dit type belasting vindt plaats tijdens het laden van gegevens in datawarehouses voor de eerste keer.
2. Incrementele belasting: dit is het type belasting dat wordt uitgevoerd om het datawarehouse periodiek bij te werken met wijzigingen in bronsysteemgegevens.
3. Volledige vernieuwing: dit type belasting verwijst naar de situatie waarin volledige gegevens van de tabel worden verwijderd en geladen met nieuwe gegevens.
Het datawarehouse staat vervolgens OLAP- of OLTP-functies toe.
Nadelen van ETL-proces
- Gegevens vergroten - Er is een limiet voor gegevens die uit verschillende bronnen worden geëxtraheerd door de ETL-tool en naar gegevensmagazijnen worden gepusht. Dus met de toename van gegevens wordt het werken met de ETL-tool en datawarehouses omslachtig.
- Aanpassing - dit verwijst naar de snelle en effectieve oplossingen of reacties op de gegevens die door bronsystemen zijn gegenereerd. Maar het gebruik van de ETL-tool hier vertraagt dit proces.
- Duur - Het gebruik van een datawarehouse om steeds meer gegevens op te slaan die periodiek worden gegenereerd, is een hoge kost die een organisatie moet betalen.
Conclusie - ETL-proces
ETL-tool bestaat uit extractie-, transformatie- en laadprocessen waarbij het helpt bij het genereren van informatie uit de gegevens die zijn verzameld uit verschillende bronsystemen. De gegevens van het bronsysteem kunnen in elke indeling komen en kunnen in elke gewenste indeling in datawarehouses worden geladen. Daarom moet de ETL-tool connectiviteit met alle soorten van deze formaten ondersteunen.
Aanbevolen artikelen
Dit is een handleiding voor een ETL-proces. Hier bespreken we de introductie, hoe werkt het?, ETL Tools en de nadelen. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie–
- Informatica ETL Tools
- ETL-testhulpmiddelen
- Wat is ETL?
- Wat is ETL-testen?