

Inleiding tot lineaire regressieanalyse
Het is vaak verwarrend om een concept te leren dat zelfs deel uitmaakt van ons dagelijks leven. Maar dat is geen probleem, we kunnen onszelf helpen en ontwikkelen om van onze dagelijkse activiteiten te leren door alleen dingen te analyseren en zijn niet bang om vragen te stellen. Waarom de prijs de vraag naar de goederen beïnvloedt, waarom de renteverandering de geldhoeveelheid beïnvloedt. Al deze kunnen worden beantwoord door een eenvoudige aanpak die bekend staat als lineaire regressie. De enige complexiteit die men voelt bij lineaire regressieanalyse is de identificatie van afhankelijke en onafhankelijke variabelen.
We moeten ontdekken wat wat beïnvloedt, en de helft van het probleem is opgelost. We moeten zien of het de prijs of de vraag is die elkaar beïnvloedt. Toen we eenmaal te weten kwamen welke de onafhankelijke variabele en afhankelijke variabele is, zijn we goed voor onze analyse. Er zijn meerdere soorten regressieanalyses beschikbaar. Deze analyse is afhankelijk van de beschikbare variabelen.
De 3 soorten regressieanalyse
Deze drie regressieanalyses hebben maximale gebruiksscenario's in de echte wereld, anders zijn er meer dan 15 soorten regressieanalyses. Soorten regressieanalyses die we gaan bespreken zijn:
- Lineaire regressieanalyse
- Meervoudige lineaire regressieanalyse
- Logistieke regressie
In dit artikel zullen we ons concentreren op eenvoudige lineaire regressie-analyse. Deze analyse helpt ons om de relatie tussen de onafhankelijke factor en de afhankelijke factor te identificeren. In eenvoudiger woorden, het Regressiemodel helpt ons om uit te vinden hoe de veranderingen in de onafhankelijke factor de afhankelijke factor beïnvloeden. Dit model helpt ons op verschillende manieren, zoals:
- Het is een eenvoudig en krachtig statistisch model
- Het zal ons helpen bij het maken van voorspellingen en voorspellingen
- Het zal ons helpen om een betere zakelijke beslissing te nemen
- Het zal ons helpen om de resultaten te analyseren en fouten te corrigeren
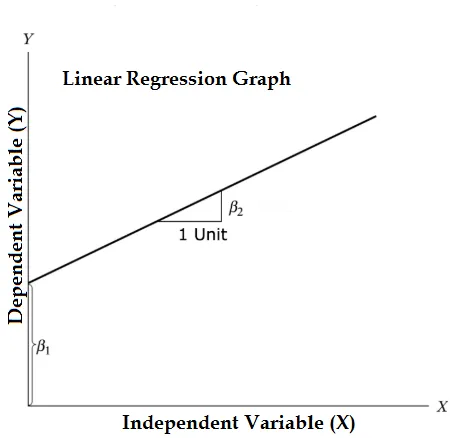
De vergelijking van lineaire regressie en splitsen in relevante delen
Y = β1 + β2X + ϵ
- Waar β1 in de wiskundige terminologie bekend als intercept en β2 in de wiskundige terminologie bekend als een helling. Ze worden ook wel regressiecoëfficiënten genoemd. ϵ is de foutterm, het is het deel van Y dat het regressiemodel niet kan verklaren.
- Y is een afhankelijke variabele (andere termen die door elkaar worden gebruikt voor afhankelijke variabelen zijn responsvariabele, regressand, gemeten variabele, waargenomen variabele, reagerende variabele, verklaarde variabele, uitkomstvariabele, experimentele variabele en / of outputvariabele).
- X is een onafhankelijke variabele (regressoren, gecontroleerde variabele, een variabele, verklarende variabele, blootstellingsvariabele en / of invoervariabele).
Probleem: om te begrijpen wat een lineaire regressieanalyse is, nemen we de gegevensset "Auto's" die standaard in R-mappen wordt geleverd. In deze dataset bevinden zich 50 observaties (in principe rijen) en 2 variabelen (kolommen). Kolomnamen zijn "Dist" en "Speed". Hier moeten we de impact op afstandsvariabelen zien als gevolg van veranderingssnelheidsvariabelen. Om de structuur van de gegevens te bekijken, kunnen we een code Str (dataset) uitvoeren. Deze code helpt ons de structuur van de gegevensset te begrijpen. Deze functionaliteiten helpen ons om betere beslissingen te nemen omdat we een beter beeld hebben van de structuur van de gegevensset. Deze code helpt ons het type datasets te identificeren.
Code:

Om de statistische controlepunten van de gegevensset te controleren, kunnen we ook de code Samenvatting (auto's) gebruiken. Deze code geeft het gemiddelde, gemiddelde, bereik van de dataset in een keer, dat de onderzoeker kan gebruiken bij het omgaan met het probleem.
Output:
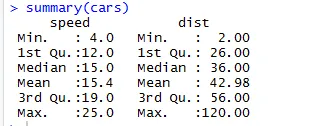
Hier kunnen we de statistische output zien van elke variabele die we in onze dataset hebben.
De grafische weergave van gegevenssets
Soorten grafische weergave die hier aan bod komen zijn en waarom:
- Scatterplot: Met behulp van de grafiek kunnen we zien in welke richting ons lineaire regressiemodel gaat, of er sterke aanwijzingen zijn om ons model te bewijzen of niet.
- Boxplot: helpt ons om uitbijters te vinden.
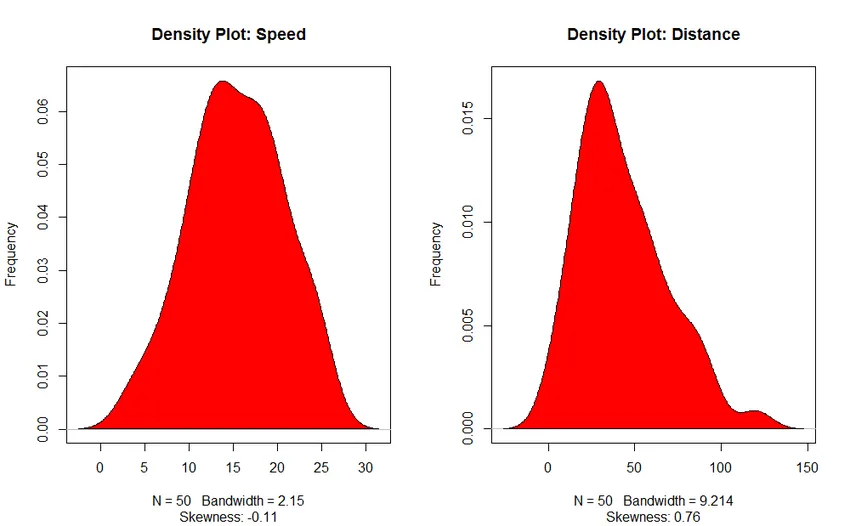
- Density Plot: Help ons de verdeling van de onafhankelijke variabele te begrijpen, in ons geval is de onafhankelijke variabele "Snelheid".
Voordelen van grafische weergave
Hier zijn de volgende voordelen:
- Makkelijk te begrijpen
- Helpt ons om snel een beslissing te nemen
- Vergelijkende analyse
- Minder moeite en tijd
1. Scatterplot: het helpt om eventuele relaties tussen de onafhankelijke variabele en de afhankelijke variabele te visualiseren.
Code:

Output:
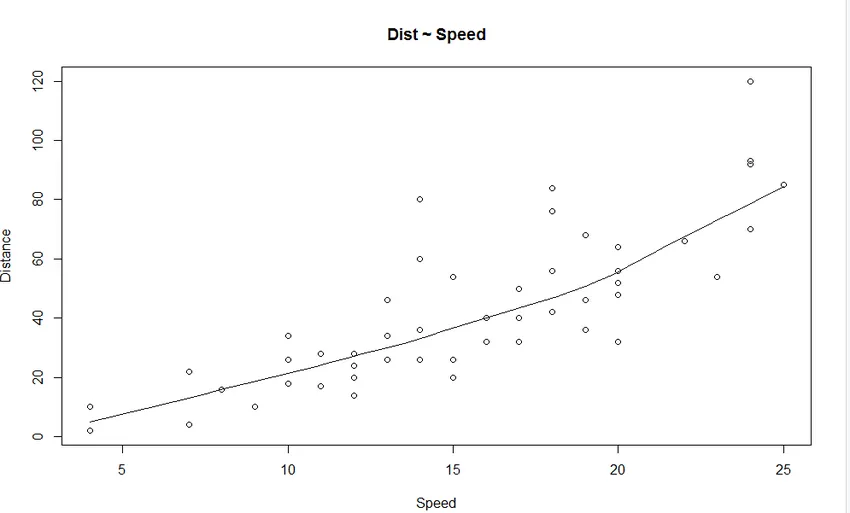
We zien in de grafiek een lineair toenemende relatie tussen de afhankelijke variabele (afstand) en de onafhankelijke variabele (snelheid).
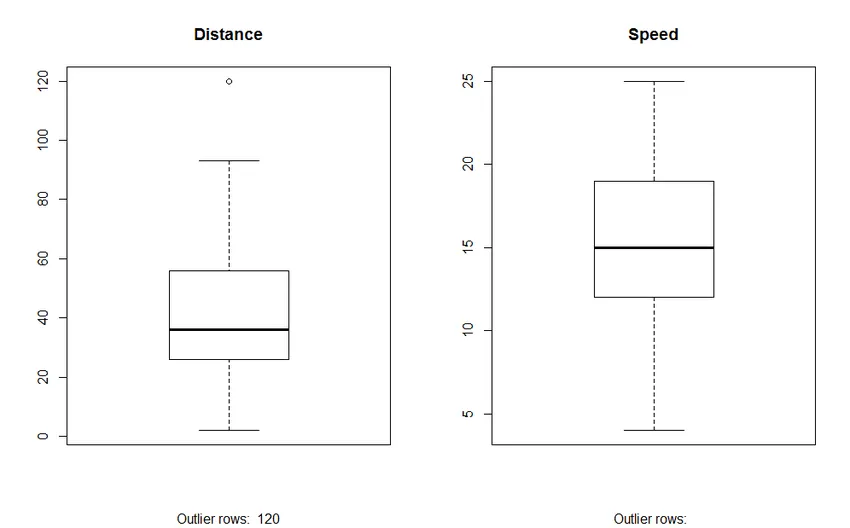
2. Boxplot: Boxplot helpt ons om de uitbijters in de datasets te identificeren. Voordelen van het gebruik van een boxplot zijn:
- Grafische weergave van de locatie en spreiding van variabelen.
- Het helpt ons om de scheefheid en symmetrie van de gegevens te begrijpen.
Code:

Output:
3. Density Plot (om de normaliteit van de verdeling te controleren)
Code:
 Output:
Output:
Correlatie analyse
Deze analyse helpt ons om de relatie tussen de variabelen te vinden. Er zijn hoofdzakelijk zes soorten correlatieanalyses.
- Positieve correlatie (0, 01 tot 0, 99)
- Negatieve correlatie (-0, 99 tot -0, 01)
- Geen correlatie
- Perfecte correlatie
- Sterke correlatie (een waarde dichter bij ± 0, 99)
- Zwakke correlatie (een waarde dichter bij 0)
Spreidingsplot helpt ons te identificeren welke soorten correlatie datasets eronder zitten en de code voor het vinden van de correlatie is

Output:
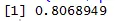
Hier hebben we een sterke positieve correlatie tussen snelheid en afstand, wat betekent dat ze een directe relatie tussen hen hebben.
Lineair regressiemodel
Dit is de kerncomponent van de analyse, eerder probeerden we dingen en testten we of de dataset die we hebben logisch genoeg is om een dergelijke analyse uit te voeren of niet. De functie die we van plan zijn te gebruiken is lm (). Deze functie bevat twee elementen die Formule en Gegevens zijn. Voordat we toewijzen welke variabele afhankelijk of onafhankelijk is, moeten we daar heel zeker van zijn, omdat onze hele formule daarvan afhankelijk is.
De formule ziet er zo uit,
Lineaire regressie <- lm (afhankelijke variabele ~ Onafhankelijke variabele, data = Date.Frame)
Code:

Output:
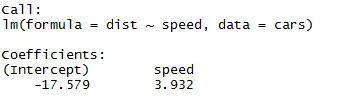
Zoals we ons kunnen herinneren uit het bovenstaande segment van het artikel, is de vergelijking van lineaire regressie:
Y = β1 + β2X + ϵ
Nu zullen we de informatie die we van de bovenstaande code in deze vergelijking hebben gekregen, inpassen.
dist = −17.579 + 3.932 ∗ snelheid
Alleen het vinden van de vergelijking van lineaire regressie is niet voldoende, we moeten de statistiek ook significant controleren. Hiervoor moeten we een code "Samenvatting" doorgeven op ons lineaire regressiemodel.
Code:

Output:

Er zijn meerdere manieren om de significante statistieken van een model te controleren, hier gebruiken we de P-waarde-methode. We kunnen een model statistisch geschikt beschouwen wanneer de P-waarde lager is dan het vooraf bepaalde statistische significante niveau, dat idealiter 0, 05 is. We kunnen in onze samenvattingstabel (lineaire_regressie) zien dat de P-waarde lager is dan 0, 05 niveau, dus we kunnen concluderen dat ons model statistisch significant is. Als we eenmaal zeker zijn van ons model, kunnen we onze dataset gebruiken om dingen te voorspellen.
Aanbevolen artikelen
Dit is een gids voor lineaire regressieanalyse. Hier bespreken we de drie soorten lineaire regressieanalyse, de grafische weergave van datasets met voordelen en lineaire regressiemodellen. U kunt ook onze andere gerelateerde artikelen doornemen voor meer informatie-
- Regressie Formule
- Regressietesten
- Lineaire regressie in R
- Soorten gegevensanalysetechnieken
- Wat is regressieanalyse?
- Topverschillen van regressie versus classificatie
- Top 6 Verschillen van lineaire regressie versus logistieke regressie