

Wat is MapReduce-algoritme?
MapReduce Algorithm is voornamelijk geïnspireerd door het functionele programmeermodel. Het wordt gebruikt voor het verwerken en genereren van big data. Deze gegevenssets kunnen tegelijkertijd worden uitgevoerd en in een cluster worden gedistribueerd. Een MapReduce-programma bestaat hoofdzakelijk uit een kaartprocedure en een verkleiningsmethode om de samenvatting uit te voeren, zoals het tellen of het opleveren van enkele resultaten. Het MapReduce-systeem werkt op gedistribueerde servers die parallel werken en alle communicatie tussen verschillende systemen beheren. Het model is een speciale strategie van split-apply-combineren strategie die helpt bij data-analyse. Mapping wordt gedaan door de Mapper-klasse en vermindert de taak door de Reducer-klasse.
Inzicht in MapReduce Algorithm
MapReduce-algoritme werkt hoofdzakelijk in drie stappen:
- Kaart functie
- Shuffle-functie
- Functie verminderen
Laten we elke functie en zijn verantwoordelijkheden bespreken.
1. Kaartfunctie
Dit is de eerste stap van het MapReduce-algoritme. Het neemt de gegevenssets en verdeelt het in kleinere subtaken. Dit wordt verder gedaan in twee stappen, splitsen en in kaart brengen. Splitsen neemt de invoergegevensset en verdeelt de gegevensset, terwijl het in kaart brengen die subsets van gegevens neemt en de vereiste actie uitvoert. De uitvoer van deze functie is een sleutel / waarde-paar.
2. Shuffle-functie
Dit staat ook bekend als de combineerfunctie en omvat samenvoegen en sorteren. Samenvoegen combineert alle sleutel / waarde-paren. Al deze hebben dezelfde sleutels. Sorteren neemt de invoer van de samenvoegstap en sorteert alle sleutel / waarde-paren met behulp van de toetsen. Deze stap keert ook terug naar sleutel / waarde-paren. De uitvoer wordt gesorteerd.
3. Functie verminderen
Dit is de laatste stap van dit algoritme. Het haalt de sleutel / waarde-paren uit de shuffle en vermindert de bewerking.
Hoe maakt MapReduce-algoritmen het werken gemakkelijk?
De relationele databasesystemen hebben een gecentraliseerde server die helpt bij het opslaan en verwerken van de gegevens. Dit waren meestal gecentraliseerde systemen. Wanneer meerdere bestanden in beeld komen, is de verwerking vervelend en ontstaat er een knelpunt tijdens het verwerken van meerdere bestanden. MapReduce brengt de gegevensset in kaart en converteert de gegevensset waarbij alle gegevens worden verdeeld in tupels en de taak verkleinen neemt de uitvoer van deze stap en combineert deze gegevenstupels in de kleinere sets. Het werkt in verschillende fasen en creëert sleutel / waarde-paren die over verschillende systemen kunnen worden verdeeld.
Wat kunt u doen met MapReduce Algorithms?
MapReduce kan met verschillende toepassingen worden gebruikt. Het kan worden gebruikt voor gedistribueerd patroongebaseerd zoeken, gedistribueerd sorteren, omkering van weblinkgrafieken, logboekstatistieken voor webtoegang. Het kan ook helpen bij het maken van en werken aan meerdere clusters, desktopgrids en vrijwillige computeromgevingen. Men kan ook dynamische cloudomgevingen, mobiele omgevingen en ook krachtige computeromgevingen creëren. Google maakte gebruik van MapReduce die de Google-index van het World Wide Web regenereert. Door het te gebruiken, worden de oude ad hoc-programma's bijgewerkt en hebben ze verschillende soorten analyses uitgevoerd. Het integreerde ook de live zoekresultaten zonder de volledige index opnieuw op te bouwen. Alle ingangen en uitgangen worden opgeslagen in het gedistribueerde bestandssysteem. De tijdelijke gegevens worden opgeslagen op een lokale schijf.
Werken met MapReduce Algorithm
Om te werken met MapReduce Algorithm, moet u het volledige proces kennen van hoe het werkt. De gegevens die worden ingenomen, doorlopen de volgende stappen:
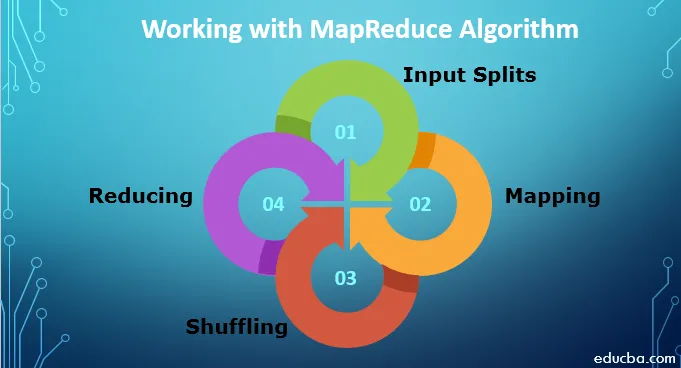
1. Invoersplitsingen: alle invoergegevens die naar de MapReduce-taak komen, zijn verdeeld in gelijke stukken die invoersplitsingen worden genoemd. Het is een stuk invoer dat door elk van de mappers kan worden gebruikt.
2. Mapping: Zodra de gegevens in brokken zijn gesplitst, doorloopt deze de fase van mapping in het map-reduce programma. Deze gesplitste gegevens worden doorgegeven aan de toewijzingsfunctie die verschillende uitvoerwaarden produceert.
3. Shuffling: Nadat de mapping is voltooid, worden de gegevens naar deze fase verzonden. Het is zijn taak om de vereiste records uit de vorige fase samen te voegen.
4. Verminderen: in deze fase wordt de output van de shuffling-fase geaggregeerd. In deze fase worden alle waarden geschud en bij elkaar gebracht door aggregatie, zodat het een enkele uitvoerwaarde retourneert. Het maakt een samenvatting van de volledige gegevensset.
Voordelen van MapReduce Algorithm
De applicaties die MapReduce gebruiken, hebben de volgende voordelen:
- Ze zijn voorzien van convergentie en goede generalisatieprestaties.
- Gegevens kunnen worden verwerkt door gebruik te maken van gegevensintensieve toepassingen.
- Het biedt een hoge schaalbaarheid.
- Elk voorkomen van elk woord tellen is eenvoudig en heeft een enorme verzameling documenten.
- Een generiek hulpmiddel kan worden gebruikt om in veel gegevensanalyses te zoeken.
- Het biedt load balancing-tijd in grote clusters.
- Het helpt ook bij het extraheren van contexten van gebruikerslocatie, situaties, enz.
- Het heeft snel toegang tot grote voorbeelden van respondenten.
Waarom zouden we MapReduce-algoritme gebruiken?
MapReduce is een applicatie die wordt gebruikt voor het verwerken van enorme datasets. Deze datasets kunnen parallel worden verwerkt. MapReduce kan mogelijk grote gegevenssets en een groot aantal knooppunten maken. Deze grote gegevenssets worden opgeslagen op HDFS waardoor de analyse van gegevens eenvoudiger wordt. Het kan alle soorten gegevens verwerken, zoals gestructureerd, ongestructureerd of semi-gestructureerd.
Waarom hebben we het MapReduce-algoritme nodig?
MapReduce groeit snel en helpt bij parallel computing. Het helpt bij het bepalen van de prijs voor producten en helpt bij het behalen van de hoogste winst. Het helpt ook bij het voorspellen en aanbevelen van analyses. Het stelt programmeurs in staat om modellen over verschillende datasets te laten draaien en maakt gebruik van geavanceerde statistische technieken en technieken voor machinaal leren die helpen bij het voorspellen van gegevens. Het filtert en verzendt de gegevens naar verschillende knooppunten binnen het cluster en functioneert volgens de mapper- en reducerfunctie.
Hoe deze technologie u helpt bij de groei van uw carrière?
Hadoop is tegenwoordig een van de meest gewilde banen. Het versnelt de snelheid en de kans die op dit gebied zeer snel groeit. Er zal nog meer een bloei in dit gebied komen. De IT-professionals die op Java werken, hebben een pluspunt omdat ze de meest gewilde mensen zijn. Ook kunnen ontwikkelaars, data-architecten, datawarehouse en BI-professionals enorme hoeveelheden salaris wegnemen door deze technologie te leren.
Conclusie
MapReduce is de basis van het Hadoop-framework. Door dit te leren, zult u zeker de markt voor data-analyse betreden. U kunt het grondig leren en leren hoe grote hoeveelheden gegevens worden verwerkt en hoe deze technologie een verandering teweegbrengt bij het verwerken en opslaan van gegevens.
Aanbevolen artikelen
Dit is een gids voor MapReduce-algoritmen. Hier bespreken we het concept, begrip, werken, behoefte, voordelen en carrièregroei. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Vragen tijdens solliciteren bij MapReduce
- Wat is MapReduce in Hadoop?
- Hoe werkt MapReduce?
- Wat is MapReduce?
- Verschillen tussen Hadoop versus MapReduce
- Verschillende bewerkingen met betrekking tot Tuples