

Hoe NLTK te installeren?
Het volgende artikel NLTK installeren biedt een overzicht voor het installeren van NLTK. NLTK is een verzameling bibliotheken voor natuurlijke taalverwerking. Het is een platform voor het bouwen van Python-programma's om natuurlijke taal te verwerken. NLTK is geschreven in de programmeertaal Python. Het werd ontwikkeld door Steven Bird en Edward Loper. Het ondersteunt onderzoek en onderwijs in NLP of nauw verwante gebieden, waaronder cognitieve wetenschappen, empirische taalkunde, het ophalen van informatie, kunstmatige intelligentie en machine learning. NLTK biedt een eenvoudig te gebruiken interface.
NLTK (Natural Language Toolkit)
- Natuurlijke taalverwerking (NLP) is een onderdeel van kunstmatige intelligentie die de taal verwerkt die door mensen wordt gesproken. Het helpt mensen dus om met computers te communiceren, zelfs als ze niet weten hoe ze het moeten gebruiken. Met NLP hoeven mensen alleen het commando aan computers te dicteren. Met de kracht van machinaal leren wordt natuurlijke taalverwerking populair en gemakkelijker te implementeren. Het is eigenlijk de techniek om met mensen te communiceren en acties op spraakopdrachten uit te voeren.
- Hierdoor kunnen apparaten worden gebruikt door zelfs de beginner die geen kennis heeft van technologie. Maar de implementatie van natuurlijke taalverwerking is niet eenvoudig, omdat een taal die door mensen wordt gesproken geen duidelijke structuur heeft. Het is dubbelzinnig en hangt af van contextwoorden die een andere betekenis kunnen hebben.
- NLTK heeft meer dan 50 corpora en lexicale bronnen zoals WordNet, Problem Report Corpus, Penn Treebank Corpus, enz. Het komt ook met een gids die de concepten van taalverwerking door toolkit en programmeerprincipes van Python verklaart, waardoor het gemakkelijk is voor de mensen die geen diepgaande kennis van programmeren hebben. Het heeft een breed scala aan pakketten en is daarmee een van de krachtige toolkits voor NLP. Tokenization, Lemmatization, Stemming, Parsing, Character count, Interpunctie, aantal woorden zijn enkele van deze pakketten.
Installeer NLTK voor Windows
Hieronder staan de instructies om NLTK in Windows te installeren. Deze zijn gebaseerd op de veronderstelling dat Python niet in het systeem is geïnstalleerd. NLTK vereist Python-versies 2.7.3.5 en hoger.
Stap 1: Download de nieuwste versie van Python voor Windows via onderstaande link
https://www.python.org/downloads/

Stap 2: Klik op gedownloade .exe om het uit te voeren.

Stap 3: Selecteer installatie aanpassen.
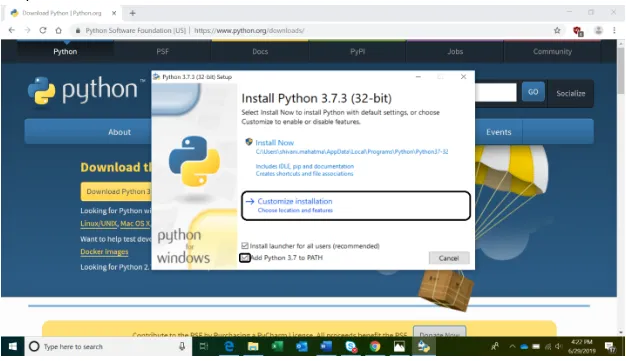
Stap 4: Controleer op alle functies, met name "pip", aangezien het helpt bij het installeren van NLTK en klik op Volgende.
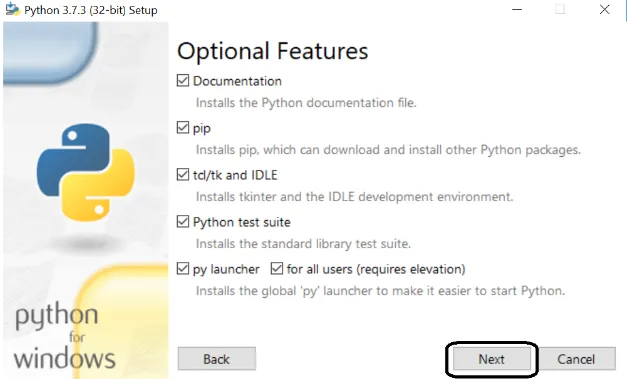
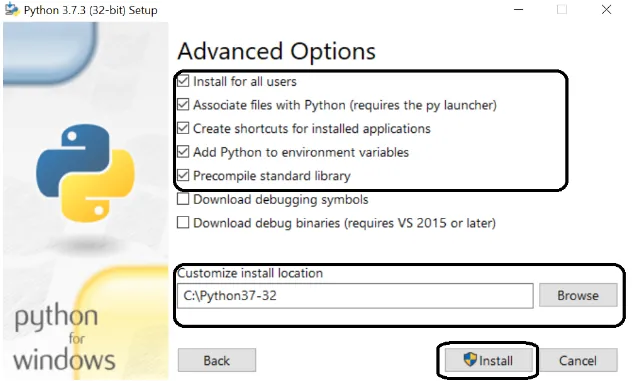
Stap 5: Selecteer in het volgende scherm geavanceerde opties, selecteer het pad en klik op installeren.
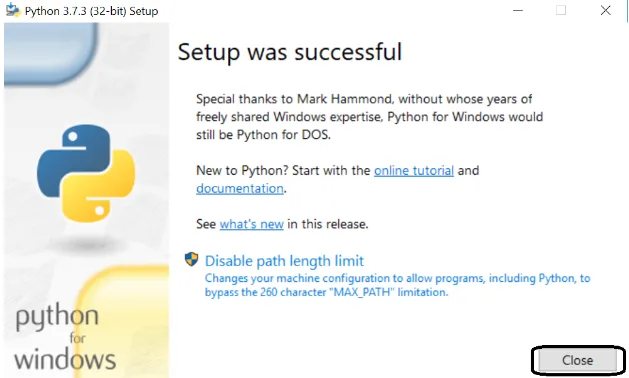
Stap 6: Zodra de installatie is voltooid, dicht bij het venster.
Stap 7: Kopieer het pad van de map Scripts om NLTK in dezelfde map te installeren.
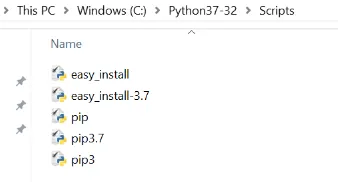
NLTK kan eenvoudig worden geïnstalleerd met behulp van een "pip" -installer. We moeten ook 'numpy' installeren.
Stap 8: Om NLTK te installeren, opent u de opdrachtprompt en typt u de onderstaande opdracht.

Zorg ervoor dat de installatie is geslaagd.
Na een succesvolle installatie is het nu tijd om de NLTK te gebruiken voor natuurlijke taalverwerking.
Stap9: Open Python Shell en typ onderstaande opdracht.


Als het zonder fouten wordt geïmporteerd, betekent dit dat NLTK correct is geïnstalleerd.
Installeer NLTK voor Mac / Linux
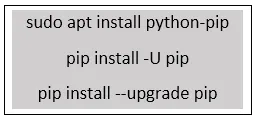
In tegenstelling tot Windows komen Linux-systemen met Python erin geïnstalleerd. Om NLTK in Linux / Mac te installeren, wordt het Pip-pakketinstallatieprogramma van Python gebruikt. Om pip te installeren of bij te werken, typt u onderstaande opdrachten in de opdrachtprompt.
Gebruik de onderstaande opdrachten om python in Linux te installeren.
Stap 1: gebruik de onderstaande opdracht om de pakketindex bij te werken.

Stap 2: Om Python in Linux-systeem te installeren, gebruikt u hieronder.

Stap 3: Typ de onderstaande opdracht in om "pip" te installeren voor Python 3.
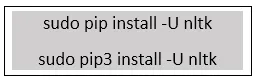
Stap 4: Nadat "Pip" is geïnstalleerd, gebruikt u de volgende opdrachten om NLTK te installeren.
NLTK Dataset
NLTK heeft veel datasets beschikbaar voor natuurlijke taalverwerking, bijvoorbeeld WordNet, WikiCorpus, Gutenberg, Opinion Lexicon, Tweebank, etc. Deze datasets worden corpora genoemd. Kortom, de NLTK-gegevensset bevat een set bestanden of documenten. Elk bestand / document bevat een verzameling woorden, letters of tekst in een enkele taal. Een corpus bestaat dus voornamelijk uit bibliotheken voor het begrijpen / leren van een taal. Het heeft regels voor grammatica en de structuur van een taal.
Na het succesvol installeren van NLTK, kunt u het importeren en ook de corpora downloaden met de volgende opdracht.

NLTK downloader opent een venster om de datasets te downloaden. De grootte van de dataset is groot, dus het zal tijd kosten. Probeer de dataset te importeren en te gebruiken om te testen of datasets correct zijn geïnstalleerd.

Verwerking van NLTK
Er zijn 5 hoofdprocessen van natuurlijke taalverwerking. Dit zijn de stappen voor het verwerken van tekst.
- EOS-detectie : einde spraakherkenning breekt de tekst in een verzameling zinvolle zinnen. Het verdeelt de lange tekst in delen die enige betekenis hebben.
- Tokenization : deze stap splitst de zinnen in tokens. Tokens bevatten niet alleen woorden, maar bevatten ook witruimte, zinsonderbrekingen.
- POS-tagging : POS betekent 'pat-of-speech'. Hier wordt informatie toegewezen aan het token. Deze informatie suggereert wat voor soort spraak het is als gespannen, werkwoord, bijvoeglijk naamwoord, zelfstandig naamwoord, enz.
- Chunking : Chunking betekent het verzamelen van tekst op basis van tags.
- Extractie: Extractie is een continu proces van het doorlopen van brokken en het taggen ervan als benoemde entiteiten zoals mensen, locaties, organisaties, etc.
Conclusie:
NLTK wordt gebruikt voor tekstclassificatie, beeldbijschriften, spraakherkenning, vragen beantwoorden, taalmodellering, documentoverzicht en vele andere bewerkingen. Er zijn veel andere hulpmiddelen voor natuurlijke taalverwerking. Maar NLTK heeft een breed scala aan bibliotheken, waardoor het een van de krachtige natuurlijke taalverwerkingstools is. Het is nauwkeuriger dan elk ander hulpmiddel, maar vanwege een groot aantal bibliotheken is het een beetje traag. Het hangt dus allemaal af van de eisen van de gebruiker. Als de gebruiker snelheid wil, dan kunnen ze ook andere tools verkiezen, maar dan zullen ze een compromis moeten sluiten met de nauwkeurigheid van de inhoud. Maar als nauwkeurigheid een prioriteit is, moeten ze zeker voor NLTK gaan.
Aanbevolen artikelen:
Dit is een handleiding voor het installeren van NLTK geweest. Hier bespreken we het basisconcept en verschillende stappen om NLTK op Windows en Linux \ Mac te installeren. U kunt ook de volgende artikelen bekijken voor meer informatie-
- Kubernetes-dashboard installeren
- Hoe JDK te installeren
- Docker installeren
- Hoe Magento installeren?
- Versies van Magento | Kenmerken van Magento-versies