
Overzicht van lineaire regressiemodellering
Wanneer je begint te leren over Machine Learning Algorithms, begin je te leren over verschillende manieren van ML-algoritmen, namelijk supervised, onbewaakt, semi-supervised en versterkingsleren. In dit artikel zullen we het hebben over begeleid leren en een van de basis maar krachtige algoritmen: lineaire regressie.

Daarom is begeleid leren het leren waarbij we de machine trainen om de relatie tussen de invoer- en uitvoerwaarden in de trainingsdataset te begrijpen en vervolgens hetzelfde model gebruiken om de outputwaarden voor de testdataset te voorspellen. Dus als we de output of labels al in onze trainingsdataset hebben en we er zeker van zijn dat de geleverde output logisch is in overeenstemming met de input, gebruiken we Supervised Learning. Begeleide leeralgoritmen worden ingedeeld in regressie en classificatie.
Regressie-algoritmen worden gebruikt wanneer u merkt dat de uitvoer een continue variabele is, terwijl classificatie-algoritmen worden gebruikt wanneer de uitvoer is verdeeld in secties zoals Pass / Fail, Good / Average / Bad, etc. We hebben verschillende algoritmen voor het uitvoeren van de regressie of classificatie acties waarbij lineaire regressie-algoritme het basisalgoritme is in regressie.
Als ik naar deze regressie ga, wil ik eerst de basis voor je bepalen voordat ik het algoritme inga. Op school hoop ik dat je je het concept van de lijnvergelijking herinnert. Laat me er een korte uitleg over geven. Je kreeg twee punten op het XY-vlak, bijvoorbeeld (x1, y1) en (x2, y2), waarbij y1 de uitvoer van x1 is en y2 de uitvoer van x2 is, dan is de lijnvergelijking die door de punten loopt (y- y1) = m (x-x1) waarbij m de helling van de lijn is. Als u nu, na het vinden van de lijnvergelijking, een punt krijgt (bijvoorbeeld x3, y3), kunt u gemakkelijk voorspellen of het punt op de lijn ligt of de afstand van het punt tot de lijn. Dit was de basisregressie die ik had gedaan in het onderwijs zonder zelfs maar te beseffen dat dit zo'n groot belang zou hebben in Machine Learning. Wat we hier in het algemeen aan doen, is proberen de vergelijkingslijn of -curve te identificeren die bij de invoer en uitvoer van de treingegevensset zou passen en vervolgens dezelfde vergelijking gebruiken om de uitvoerwaarde van de testgegevensset te voorspellen. Dit zou resulteren in een continu gewenste waarde.
Definitie van lineaire regressie
Lineaire regressie bestaat eigenlijk al heel lang (ongeveer 200 jaar). Het is een lineair model, dwz het veronderstelt een lineair verband tussen de invoervariabelen (x) en een enkele uitvoervariabele (y). De y hier wordt berekend door de lineaire combinatie van de invoervariabelen.
We hebben twee soorten lineaire regressie
Eenvoudige lineaire regressie
Wanneer er een enkele ingangsvariabele is, is de lijnvergelijking c
beschouwd als y = mx + c, dan is het Simple Linear Regression.
Meerdere lineaire regressie
Wanneer er meerdere invoervariabelen zijn, dwz dat de lijnvergelijking wordt beschouwd als y = ax 1 + bx 2 + … nx n, dan is dit meervoudige lineaire regressie. Verschillende technieken worden gebruikt om de regressievergelijking op basis van gegevens voor te bereiden of te trainen en de meest voorkomende daarvan is de gewone minste vierkanten. Het model gebouwd met behulp van de genoemde methode wordt aangeduid als gewone minste vierkanten lineaire regressie of gewoon minste vierkanten regressie. Model wordt gebruikt wanneer de invoerwaarden en de te bepalen uitvoerwaarde numerieke waarden zijn. Wanneer er slechts één invoer en één uitvoer is, is de gevormde vergelijking een lijnvergelijking, dwz
y = B0x+B1
waarbij de coëfficiënten van de lijn moeten worden bepaald met behulp van statistische methoden.
Eenvoudige lineaire regressiemodellen zijn zeer zeldzaam in ML omdat we over het algemeen verschillende inputfactoren hebben om de uitkomst te bepalen. Wanneer er meerdere invoerwaarden en één uitvoerwaarde zijn, is de gevormde vergelijking die van een vlak of hypervlak.
y = ax 1 +bx 2 +…nx n
Het kernidee in het regressiemodel is het verkrijgen van een lijnvergelijking die het beste bij de gegevens past. De best passende lijn is die waarbij de totale voorspellingsfout voor alle gegevenspunten zo klein mogelijk wordt geacht. De fout is de afstand tussen het punt op het vlak tot de regressielijn.
Voorbeeld
Laten we beginnen met een voorbeeld van eenvoudige lineaire regressie.

De relatie tussen de lengte en het gewicht van een persoon is recht evenredig. Er is een onderzoek bij de vrijwilligers uitgevoerd om de lengte en het ideale gewicht van de persoon te bepalen en de waarden zijn vastgelegd. Dit wordt beschouwd als onze set trainingsgegevens. Met behulp van de trainingsgegevens wordt een regressielijnvergelijking berekend die een minimale fout geeft. Deze lineaire vergelijking wordt vervolgens gebruikt om voorspellingen te doen over nieuwe gegevens. Dat wil zeggen, als we de lengte van de persoon geven, dan moet het overeenkomstige gewicht worden voorspeld door het door ons ontwikkelde model met minimale of nulfout.
Y(pred) = b0 + b1*x
De waarden b0 en b1 moeten zo worden gekozen dat ze de fout minimaliseren. Als de som van de kwadraatfout wordt genomen als een metriek om het model te evalueren, dan is het doel om een lijn te verkrijgen die de fout het beste vermindert.
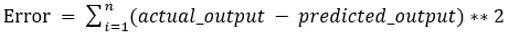
We verhelpen de fout zodat positieve en negatieve waarden elkaar niet opheffen. Voor model met één voorspeller:
Berekening van onderschepping (b0) in de lijnvergelijking wordt gedaan door:
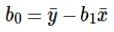
De berekening van de coëfficiënt voor de invoerwaarde x wordt gedaan door:
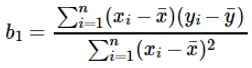
De coëfficiënt b 1 begrijpen:
- Als b 1 > 0, dan zijn x (invoer) en y (uitvoer) direct evenredig. Dat is een toename in x zal y verhogen, zoals lengtetoename, gewichtstoename.
- Als b 1 <0, dan zijn x (voorspeller) en y (doel) omgekeerd evenredig. Dat is een toename in x zal y verminderen, zoals de snelheid van een voertuig, de tijd neemt af neemt af.
De coëfficiënt b 0 begrijpen:
- B 0 neemt de restwaarde voor het model op en zorgt ervoor dat de voorspelling niet bevooroordeeld is. Als we geen B 0- term hebben, wordt de lijnvergelijking (y = B 1 x) gedwongen door de oorsprong te gaan, dwz dat de invoer- en uitvoerwaarden in het model resulteren in 0. Maar dit zal nooit het geval zijn als we 0 hebben bij invoer is B 0 het gemiddelde van alle voorspelde waarden wanneer x = 0. Het instellen van alle voorspellende waarden op 0 in het geval van x = 0 zal leiden tot gegevensverlies en is vaak onmogelijk.
Afgezien van de hierboven genoemde coëfficiënten, kan dit model ook worden berekend met behulp van normale vergelijkingen. Ik zal het gebruik van normale vergelijkingen en het ontwerpen van een eenvoudig / multilineair regressiemodel verder bespreken in mijn aanstaande artikel.
Aanbevolen artikelen
Dit is een gids voor lineaire regressiemodellering. Hier bespreken we de definitie, soorten lineaire regressie die eenvoudige en meervoudige lineaire regressie omvat, samen met enkele voorbeelden. U kunt ook de volgende artikelen bekijken voor meer informatie–
- Lineaire regressie in R
- Lineaire regressie in Excel
- Voorspellende modellen
- Hoe GLM in R te maken?
- Vergelijking van lineaire regressie versus logistieke regressie