

Introductie tot Map Join in Hive
Map join is een functie die wordt gebruikt in Hive-zoekopdrachten om de efficiëntie ervan te verhogen wat betreft snelheid. Join is een voorwaarde die wordt gebruikt om de gegevens uit 2 tabellen te combineren. Dus als we een normale join uitvoeren, wordt de taak verzonden naar een Map-Reduce-taak die de hoofdtaak splitst in 2 fasen - "Mapfase" en "Stage verkleinen". De kaartfase interpreteert de invoergegevens en retourneert de uitvoer naar de verkleinfase in de vorm van sleutel / waarde-paren. Deze gaat vervolgens door de shuffle-fase waar ze worden gesorteerd en gecombineerd. Het verloopstuk neemt deze gesorteerde waarde en voltooit de join-taak.
Een tabel kan volledig in het geheugen worden geladen binnen een mapper en zonder het Map / Reducer-proces te gebruiken. Het leest de gegevens van de kleinere tabel en slaat deze op in een hashtabel in het geheugen en serialiseert deze vervolgens naar een hashgeheugenbestand waardoor de tijd aanzienlijk wordt verkort. Het wordt ook wel Map Side Join in Hive genoemd. Kort gezegd gaat het om het uitvoeren van joins tussen 2 tabellen door alleen de kaartfase te gebruiken en de fase Verkleinen over te slaan. Een tijdsafname in de berekening van uw vragen kan worden waargenomen als ze regelmatig een kleine tabel-join gebruiken.
Syntaxis voor Map Join in Hive
Als we een join-query met map-join willen uitvoeren, moeten we een trefwoord "/ * + MAPJOIN (b) * /" opgeven in de instructie zoals hieronder:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Voor dit voorbeeld moeten we 2 tabellen maken met de namen tablename1 en tablename2 met 2 kolommen: emp_id en emp_name. Een moet een groter bestand zijn en een moet een kleinere zijn.
Voordat we de query uitvoeren, moeten we de onderstaande eigenschap instellen op true:
hive.auto.convert.join=true
De joinquery voor map join is zoals hierboven geschreven en het resultaat dat we krijgen is:
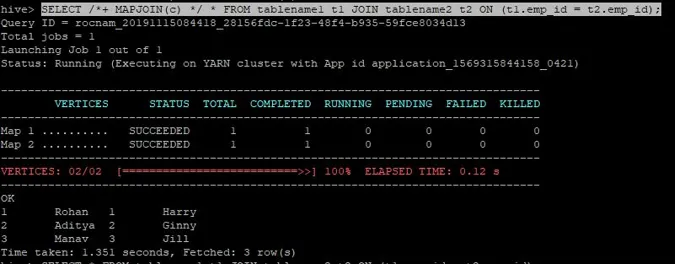
De vraag werd binnen 1.351 seconden voltooid.
Voorbeelden van Map Join in Hive
Hier zijn de volgende voorbeelden die hieronder worden genoemd
1. Voorbeeld van kaartkoppeling
Laten we voor dit voorbeeld 2 tabellen met de naam table1 en table2 maken met respectievelijk 100 en 200 records. U kunt de onderstaande opdracht en schermafbeeldingen raadplegen om hetzelfde uit te voeren:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

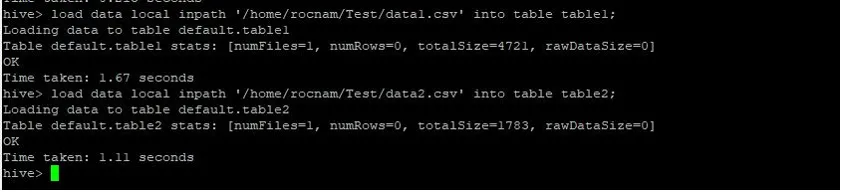
Nu laden we de records in beide tabellen met onderstaande opdrachten:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Laten we een normale map-join-zoekopdracht uitvoeren op hun ID's zoals hieronder wordt getoond en de tijd verifiëren die daarvoor nodig is:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
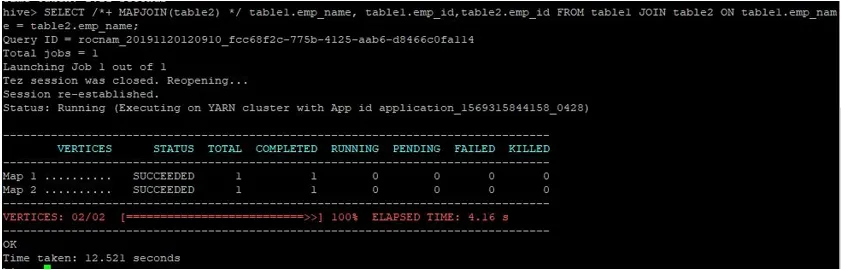
Zoals we kunnen zien, duurde een normale map-join-zoekopdracht 12.521 seconden.
2. Bucket-Map Join-voorbeeld
Laten we nu Bucket-map join gebruiken om hetzelfde uit te voeren. Er zijn een paar beperkingen die moeten worden opgevolgd voor bucketing:
- De emmers kunnen alleen met elkaar worden verbonden als het totale aantal emmers van een tabel een veelvoud is van het aantal emmers in de andere tabel.
- Moet geslepen tafels hebben om bucketing uit te voeren. Laten we daarom hetzelfde creëren.
Hier volgen de opdrachten die worden gebruikt om tabellen met tabellen table1 en table2 te maken:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

We zullen dezelfde records van tabel 1 ook in deze ingepakte tabellen invoegen:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
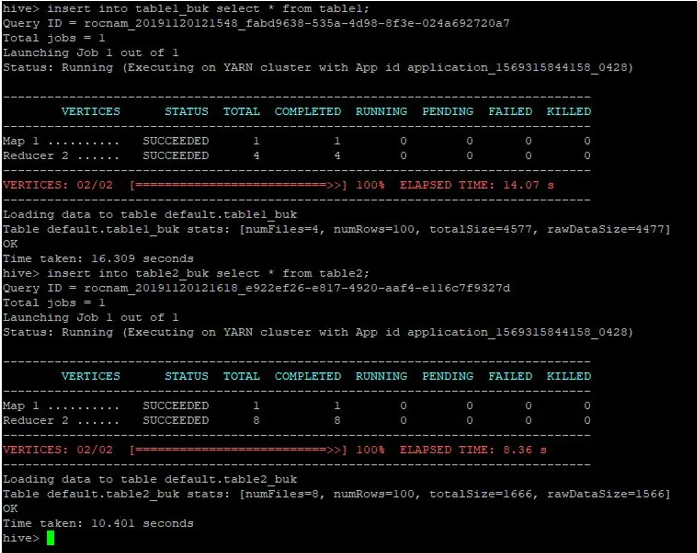
Nu we onze 2 bucketed tabellen hebben, laten we hier een bucket-map mee uitvoeren. De eerste tabel heeft 4 emmers, terwijl de tweede tabel 8 emmers heeft die op dezelfde kolom zijn gemaakt.
Om de bucket-join-query te laten werken, moeten we de onderstaande eigenschap instellen op true in de component:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
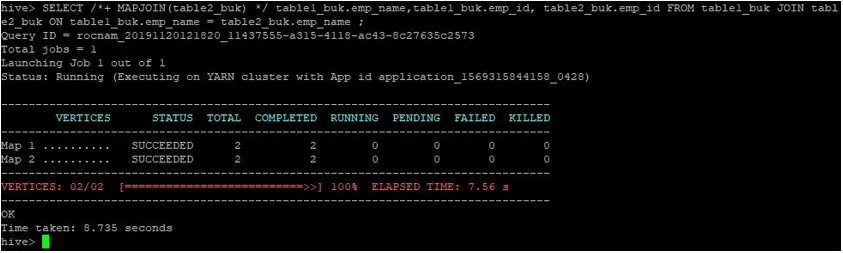
Zoals we kunnen zien, werd de zoekopdracht voltooid in 8.735 seconden, wat sneller is dan een normale kaart-join.
3. Sorteer voorbeeld samenvoegingskaartmap-join (SMB)
SMB kan worden uitgevoerd op buckettabellen met hetzelfde aantal buckets en als de tabellen moeten worden gesorteerd en bucket op join-kolommen. Mapper-niveau voegt zich dienovereenkomstig bij deze emmers.
Hetzelfde als in Bucket-map join, er zijn 4 emmers voor table1 en 8 emmers voor table2. Voor dit voorbeeld maken we nog een tafel met 4 emmers.
Om SMB-query uit te voeren, moeten we de volgende bijenkorfeigenschappen instellen, zoals hieronder weergegeven:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Om SMB-join uit te voeren, moeten gegevens worden gesorteerd volgens de join-kolommen. Daarom overschrijven we de gegevens in tabel 1 zoals hieronder weergegeven:
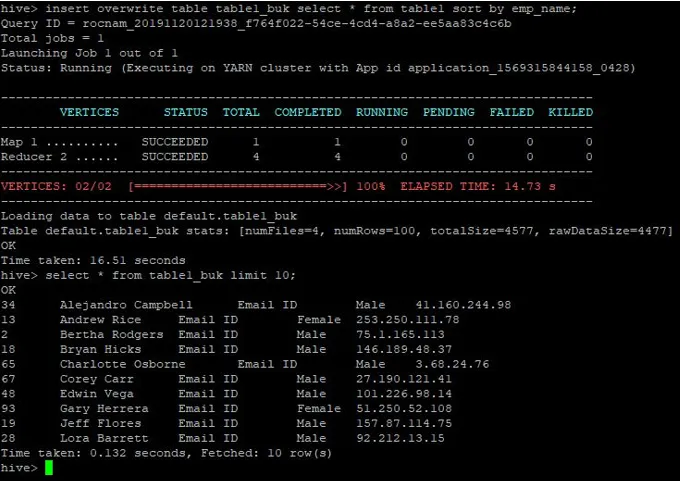
>insert overwrite table table1_buk select * from table1 sort by emp_name;
De gegevens zijn nu gesorteerd, wat te zien is in de onderstaande screenshot:
We zullen ook gegevens in bucketed table2 overschrijven zoals hieronder:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Laten we de join voor bovenstaande 2 tabellen als volgt uitvoeren:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
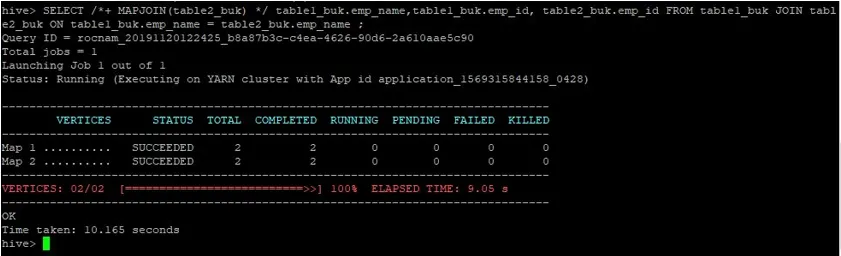
We kunnen zien dat de zoekopdracht 10.165 seconden duurde, wat weer beter is dan een normale kaart-join.
Laten we nu een andere tabel maken voor table2 met 4 emmers en dezelfde gegevens gesorteerd met emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
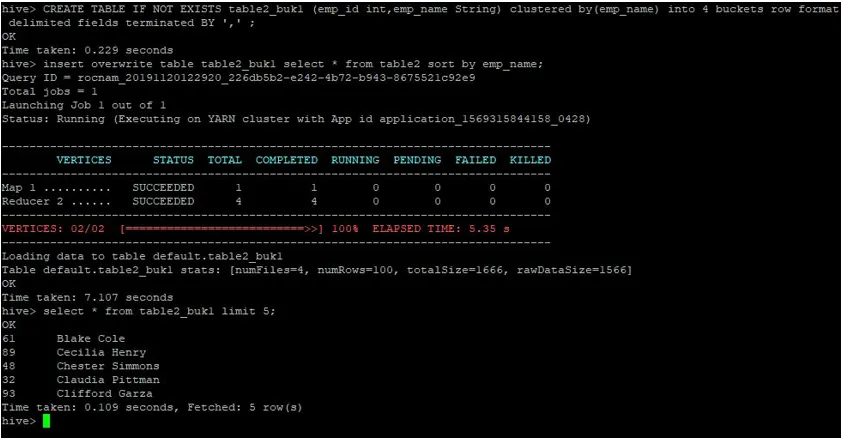
Aangezien we nu beide tabellen met 4 emmers hebben, kunnen we opnieuw een joinquery uitvoeren.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
De zoekopdracht heeft opnieuw 8.851 seconden sneller genomen dan de normale zoekopdracht voor het samenvoegen van kaarten.
voordelen
- Map join vermindert de tijd die nodig is voor sorteer- en samenvoegprocessen die plaatsvinden in de shuffle en reduceert fasen waardoor ook de kosten worden geminimaliseerd.
- Het verhoogt de prestatie-efficiëntie van de taak.
beperkingen
- Dezelfde tabel / alias mag niet worden gebruikt voor het samenvoegen van verschillende kolommen in dezelfde query.
- Map join-query kan geen volledige outer joins omzetten in de map-side joins.
- Het samenvoegen van kaarten kan alleen worden uitgevoerd als een van de tabellen klein genoeg is om in het geheugen te passen. Daarom kan het niet worden uitgevoerd waar de tabelgegevens enorm zijn.
- Een linkse join is alleen mogelijk met een map-join wanneer de juiste tabelgrootte klein is.
- Een juiste join is alleen mogelijk met een map-join als de grootte van de linkertabel klein is.
Conclusie
We hebben geprobeerd de best mogelijke punten van Map Join in Hive op te nemen. Zoals we hierboven hebben gezien, werkt Map-side join het beste wanneer een tabel minder gegevens bevat, zodat de taak snel wordt voltooid. De tijd die nodig is voor de hier weergegeven zoekopdrachten is afhankelijk van de grootte van de gegevensset. De hier weergegeven tijd is dus alleen voor analyse. Map join kan eenvoudig in realtime-applicaties worden geïmplementeerd, omdat we enorme gegevens hebben, waardoor het netwerk-I / O-verkeer wordt verminderd.
Aanbevolen artikelen
Dit is een gids voor Map Join in Hive. Hier bespreken we de voorbeelden van Map Join in Hive samen met de voordelen en beperkingen. U kunt ook het volgende artikel bekijken voor meer informatie -
- Sluit zich aan bij Hive
- Bijenkorf ingebouwde functies
- Wat is een bijenkorf?
- Hive Commands