

Verschil tussen Big Data en Apache Hadoop
Alles is op internet. Internet heeft veel gegevens. Daarom is alles Big Data. Weet je dat er elke dag 2, 5 Quintillion Bytes-gegevens worden gemaakt die zich opstapelen als Big Data? Onze dagelijkse activiteiten zoals reacties, likes, posts etc. op sociale media zoals Facebook, LinkedIn, Twitter en Instagram worden steeds groter als Big Data. Aangenomen wordt dat tegen 2020 voor elke persoon op aarde bijna 1, 7 megabytes aan gegevens zal worden aangemaakt. U kunt zich voorstellen en overwegen hoeveel gegevens worden verondersteld door elke persoon op aarde. Vandaag zijn we verbonden en delen we onze levens online. De meesten van ons zijn online verbonden. We leven in een smart home en gebruiken slimme voertuigen en zijn allemaal verbonden met onze smartphones. Stel je je ooit voor hoe deze apparaten slim worden? Ik wil je graag een heel eenvoudig antwoord geven omdat het de zeer grote hoeveelheid gegevens, namelijk Big Data, analyseert. Binnen vijf jaar zullen er wereldwijd meer dan 50 miljard smart connected apparaten zijn, allemaal ontwikkeld om gegevens te verzamelen, analyseren en delen om ons leven comfortabeler te maken.
Hierna volgen de inleidingen van Big Data versus Apache Hadoop
Introductie van Term Big Data
Wat is big data? Welke gegevensgrootte wordt als groot beschouwd en wordt Big Data genoemd? We hebben veel relatieve aannames voor de term Big Data. Het is mogelijk dat de hoeveelheid gegevens, zeg 50 terabytes, kan worden beschouwd als big data voor Start-ups, maar het kan geen Big Data zijn voor bedrijven als Google en Facebook. Het is omdat ze de infrastructuur hebben om die hoeveelheid gegevens op te slaan en te verwerken. Ik zou de term Big Data willen definiëren als:
- Big Data is de hoeveelheid gegevens die de technologie niet kan opslaan, beheren en efficiënt verwerken.
- Big Data zijn gegevens waarvan de schaal, diversiteit en complexiteit nieuwe architectuur, technieken, algoritmen en analyses vereisen om deze te beheren en er waarde en verborgen kennis uit te halen.
- Big data zijn hoogvolume en hoge snelheden en een grote verscheidenheid aan informatieactiva die kosteneffectieve, innovatieve vormen van informatieverwerking vereisen die verbeterd inzicht, besluitvorming en procesautomatisering mogelijk maken.
- Big Data verwijst naar technologieën en initiatieven die gegevens bevatten die te divers, snel veranderend of te groot zijn voor conventionele technologieën, vaardigheden en infrastructuur om efficiënt aan te pakken. Anders gezegd, het volume, de snelheid of de verscheidenheid aan gegevens is te groot.
3 V's van Big Data
- Volume: Volume verwijst naar de hoeveelheid / hoeveelheid waarmee gegevens worden gecreëerd, zoals elk uur dat transacties van Wal-Mart-klanten het bedrijf ongeveer 2, 5 petabyte aan gegevens opleveren.
- Velocity: Velocity verwijst naar de snelheid waarmee gegevens worden verplaatst, zoals Facebook-gebruikers gemiddeld 31, 25 miljoen berichten verzenden en elke minuut op elke dag 2, 77 miljoen video's bekijken via internet.
- Variety: Variety verwijst naar verschillende gegevensindelingen die zijn gemaakt zoals gestructureerde, semi-gestructureerde en ongestructureerde gegevens. Zoals het verzenden van e-mails met de bijlage op Gmail ongestructureerde gegevens is, terwijl het plaatsen van opmerkingen met sommige externe links ook ongestructureerde gegevens wordt genoemd. Het delen van afbeeldingen, audioclips, videoclips zijn een ongestructureerde vorm van gegevens.
Het opslaan en verwerken van dit enorme volume, snelheid en verscheidenheid aan gegevens is een groot probleem. We moeten denken aan andere technologie dan RDBMS voor Big Data. Dit komt omdat RDBMS alleen gestructureerde gegevens kan opslaan en verwerken. Dus hier komt Apache Hadoop als een redding.
Introductie van Term Apache Hadoop
Apache Hadoop is een open-source softwareframework voor het opslaan van gegevens en het uitvoeren van applicaties op clusters van hardware voor basisproducten. Apache Hadoop is een softwareframework waarmee gedistribueerde verwerking van grote gegevenssets over clusters van computers mogelijk is met behulp van eenvoudige programmeermodellen. Het is ontworpen om op te schalen van afzonderlijke servers naar duizenden machines, die elk lokale berekeningen en opslag bieden. Apache Hadoop is een framework voor het opslaan en verwerken van Big Data. Apache Hadoop kan alle gegevensformaten opslaan en verwerken, zoals gestructureerde, semi-gestructureerde en ongestructureerde gegevens. Apache Hadoop is open source en commodity hardware bracht een revolutie teweeg in de IT-industrie. Het is gemakkelijk toegankelijk voor elk niveau van bedrijven. Ze hoeven niet meer te investeren om het Hadoop-cluster en op verschillende infrastructuur op te zetten. Dus laten we in dit bericht het nuttige verschil tussen Big Data en Apache Hadoop gedetailleerd bekijken.
Framework van Apache Hadoop
Het Apache Hadoop-framework bestaat uit twee delen:
- Hadoop Distributed File System (HDFS): deze laag is verantwoordelijk voor het opslaan van gegevens.
- MapReduce: deze laag is verantwoordelijk voor de verwerking van gegevens op Hadoop Cluster.
Hadoop Framework is verdeeld in master- en slave-architectuur. Laag van Hadoop Distributed File System (HDFS) Naam Knooppunt is hoofdcomponent, terwijl Gegevensknoop een Slave-component is, terwijl in MapReduce-laag Job Tracker een hoofdcomponent is, terwijl task tracker een slave-component is. Hieronder is het diagram voor het Apache Hadoop-framework.
Waarom is Apache Hadoop belangrijk?
- Mogelijkheid om snel grote hoeveelheden gegevens op te slaan en te verwerken
- Rekenkracht: het gedistribueerde rekenmodel van Hadoop verwerkt big data snel. Hoe meer rekenknooppunten u gebruikt, hoe meer rekenkracht u hebt.
- Fouttolerantie: gegevens- en applicatieverwerking zijn beschermd tegen hardwarefouten. Als een knooppunt uitvalt, worden taken automatisch omgeleid naar andere knooppunten om ervoor te zorgen dat de gedistribueerde computerverwerking niet mislukt. Meerdere kopieën van alle gegevens worden automatisch opgeslagen.
- Flexibiliteit: u kunt zoveel gegevens opslaan als u wilt en later beslissen hoe u deze wilt gebruiken. Dat omvat ongestructureerde gegevens zoals tekst, afbeeldingen en video's.
- Lage kosten: het open-source framework is gratis en maakt gebruik van standaardhardware om grote hoeveelheden gegevens op te slaan.
- Schaalbaarheid: u kunt uw systeem eenvoudig laten groeien om meer gegevens te verwerken, eenvoudig door knooppunten toe te voegen. Er is weinig administratie vereist
Head-to-head vergelijking tussen Big Data versus Apache Hadoop (Infographics)
Hieronder vindt u de Top 4-vergelijking tussen Big Data en Apache Hadoop
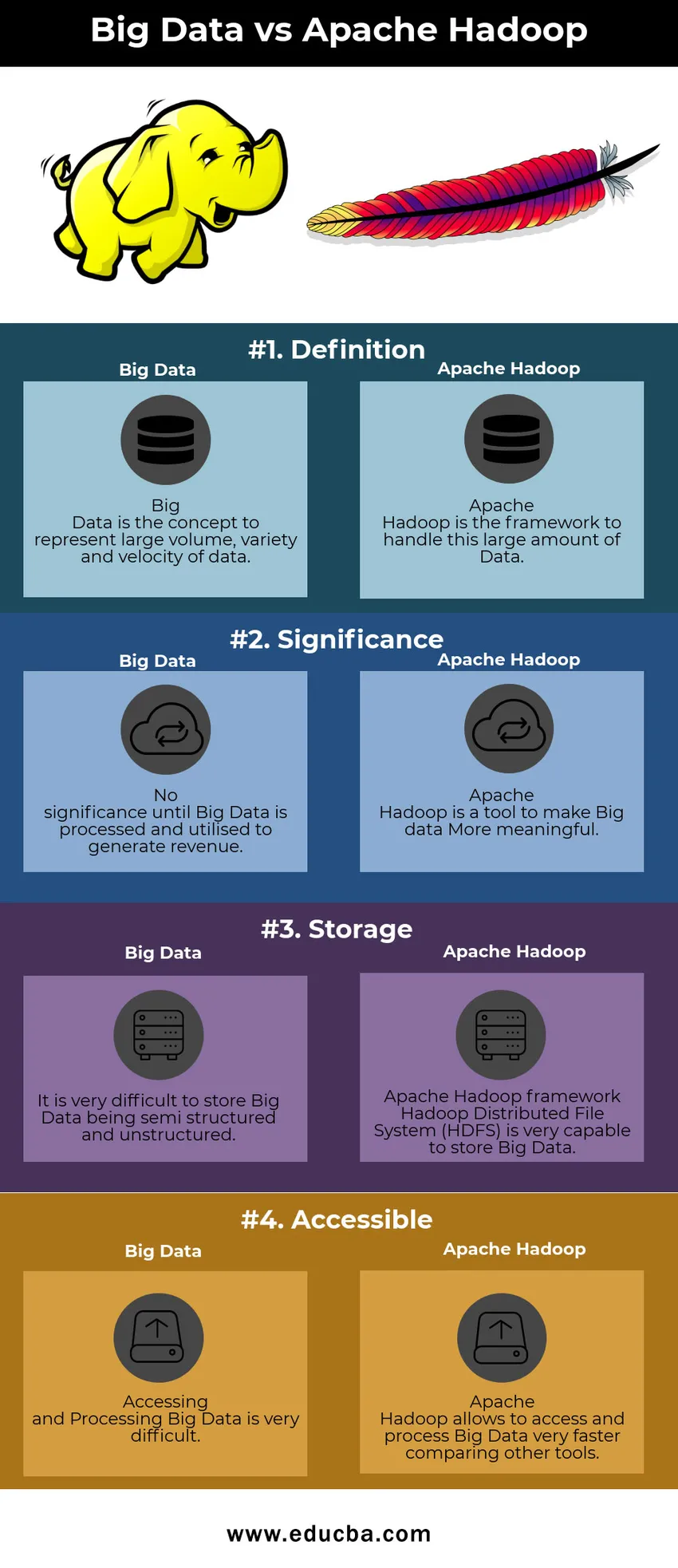
Big Data vs Apache Hadoop-vergelijkingstabel
Ik bespreek belangrijke artefacten en maak onderscheid tussen Big Data versus Apache Hadoop
| Big Data | Apache Hadoop | |
| Definitie | Big Data is het concept om een grote hoeveelheid, variëteit en snelheid van gegevens weer te geven | Apache Hadoop is het raamwerk om deze grote hoeveelheid gegevens te verwerken |
| Betekenis | Geen betekenis totdat Big Data wordt verwerkt en gebruikt om inkomsten te genereren | Apache Hadoop is een hulpmiddel om Big data zinvoller te maken |
| opslagruimte | Het is heel moeilijk om Big Data semi-gestructureerd en ongestructureerd op te slaan | Apache Hadoop-framework Hadoop Distributed File System (HDFS) is zeer geschikt om Big Data op te slaan |
| Beschikbaar | Toegang tot en verwerking van Big Data is erg moeilijk | Met Apache Hadoop kunt u Big Data zeer snel openen en verwerken in vergelijking met andere tools |
Conclusie - Big Data versus Apache Hadoop
Je kunt Big Data en Apache Hadoop niet vergelijken. Het is omdat Big Data een probleem is, terwijl Apache Hadoop Solution is. Omdat de hoeveelheid gegevens exponentieel toeneemt in alle sectoren, is het erg moeilijk om gegevens op te slaan en te verwerken vanuit één systeem. Dus om deze grote hoeveelheid gegevens te verwerken, hebben we gedistribueerde verwerking en opslag van gegevens nodig. Daarom komt Apache Hadoop met de oplossing voor het opslaan en verwerken van een zeer grote hoeveelheid gegevens. Ten slotte zal ik concluderen dat Big Data een grote hoeveelheid complexe gegevens is, terwijl Apache Hadoop een mechanisme is om Big Data zeer efficiënt en soepel op te slaan en te verwerken.
Aanbevolen artikel
Dit is een leidraad geweest voor Big Data versus Apache Hadoop, hun betekenis, vergelijking van persoon tot persoon, belangrijkste verschillen, vergelijkingstabel en conclusie. dit artikel bestaat uit alle nuttige verschillen tussen Big Data en Apache Hadoop. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Big Data versus Data Science - Hoe zijn ze anders?
- Top 5 Big Data-trends die bedrijven moeten beheersen
- Hadoop vs Apache Spark - interessante dingen die u moet weten
- Apache Hadoop vs Apache Spark | Top 10 vergelijkingen die u moet weten!