
Verschil tussen Hive en HBase
Apache Hive en HBase zijn op Hadoop gebaseerde big data-technologieën. Ze hebben allebei gegevens opgevraagd. Hive en HBase draaien op Hadoop en verschillen in functionaliteit. Hive is een op kaart verkleinen gebaseerd SQL-dialect, terwijl HBase alleen MapReduce ondersteunt. HBase slaat gegevens op in de vorm van sleutel / waarde of kolomfamilieparen, terwijl Hive geen gegevens opslaat.
Head to Head verschillen tussen Hive vs HBase (Infographics)
Hieronder staat het top 8-verschil tussen bijenkorf versus HBase
Belangrijkste verschillen tussen Hive versus HBase
- Hbase is compatibel met ACID, terwijl Hive dat niet is.
- Hive ondersteunt partitionering en filtercriteria op basis van de datumnotatie, terwijl HBase automatische partitionering ondersteunt.
- Hive ondersteunt geen update-instructies, terwijl HBase ze ondersteunt.
- Hbase is sneller in vergelijking met Hive bij het ophalen van gegevens.
- Hive wordt gebruikt om gestructureerde gegevens te verwerken, terwijl HBase, omdat het schema-vrij is, elk type gegevens kan verwerken.
- Hbase is sterk (horizontaal) schaalbaar in vergelijking met Hive.
- Hive analyseert de gegevens op de HDFS met behulp van SQL-query's en converteert deze vervolgens naar een kaart en vermindert het aantal taken, terwijl het in Hbase, omdat het in realtime streaming is, rechtstreeks zijn bewerkingen in de database uitvoert door te partitioneren naar tabellen en kolomfamilies.
- wanneer we naar de query van data hive gaan, gebruikt een shell die bekend staat als Hive shell om de opdrachten te geven, terwijl HBase, omdat het een database is, we een opdracht gebruiken om de gegevens in HBase te verwerken.
- Om naar de Hive-shell te gaan, gebruiken we de opdracht hive. Na het geven hiervan lijkt het op een bijenkorf>. In HBase geven we eenvoudigweg als Gebruik HBase.
Hive vs HBase vergelijkingstabel
| Basis voor vergelijking | Bijenkorf | HBase |
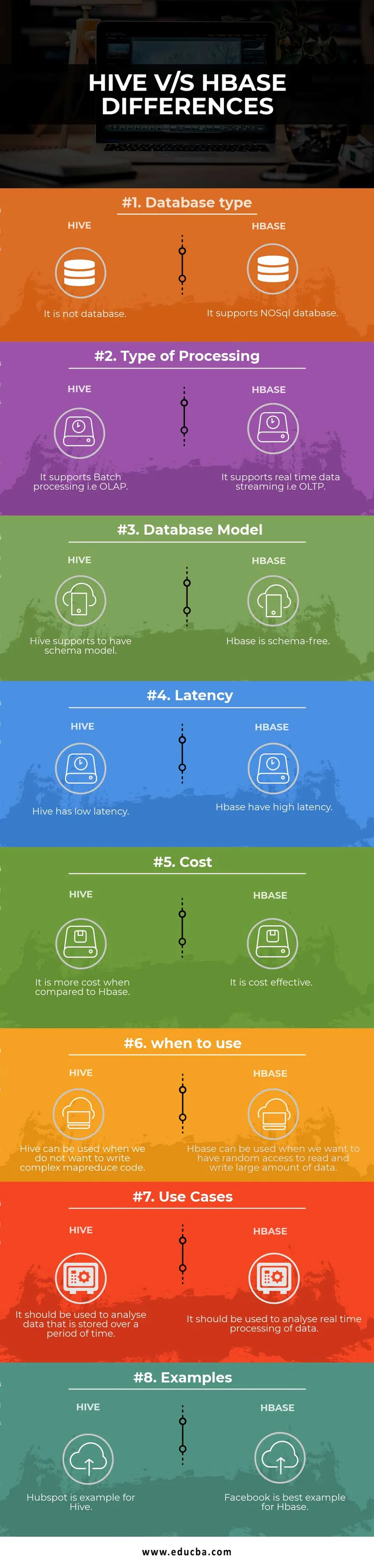
| Databasetype | Het is geen database | Het ondersteunt NoSQL-database |
| Type verwerking | Het ondersteunt batchverwerking, dwz OLAP | Het ondersteunt realtime datastreaming, dat wil zeggen OLTP |
| Databasemodel | Hive ondersteunt een schemamodel | Hbase is zonder schema |
| Wachttijd | Hive heeft een lage latentie | Hbase heeft een hoge latentie |
| Kosten | Het is duurder in vergelijking met HBase | Het is kostenbesparend |
| wanneer te gebruiken | Hive kan worden gebruikt wanneer we geen complexe MapReduce-code willen schrijven | HBase kan worden gebruikt wanneer we willekeurige toegang willen hebben om een grote hoeveelheid gegevens te lezen en te schrijven |
| Gebruik cases | Het moet worden gebruikt om gegevens te analyseren die gedurende een bepaalde periode zijn opgeslagen | Het moet worden gebruikt om de realtime verwerking van gegevens te analyseren. |
| Voorbeelden | Hubspot is een voorbeeld voor Hive | Facebook is het beste voorbeeld voor Hbase |
Verschillen in codering tussen Hive versus HBase
Laten we nu de fundamentele verschillen tussen Hive en HBase in codering bespreken.
| Basis voor vergelijking | Bijenkorf | HBase |
| Om een database aan te maken | DATABASE MAKEN (INDIEN NIET BESTAAT) DATABASE-NAAM; | Omdat Hbase een database is, hoeven we geen specifieke database te maken |
| Een database neerzetten | DROP DATABASE (INDIEN BESTAAT) DATABASE-NAAM (BEPERKING OF CASCADE); | NA |
| Een tabel maken | CREËER (TIJDELIJKE OF EXTERNE) TAFEL (INDIEN NIET BESTAAT) TABELNAAM ((kolomnaam data_type (opmerking kolom-opmerking), …)) (opmerkingstabel_commentaar) (RIJ FORMAT rij-indeling) (Opgeslagen als bestandsindeling) | CREËREN '', '' |
| Een tabel wijzigen | ALTER TABELnaam RENAME NAAR nieuwe naam
ALTER TABLE name DROP (COLUMN) kolomnaam ALTER TABEL naam KOLOM TOEVOEGEN (col-spec (, col-spec ..)) ALTER TABEL naam VERANDEREN kolomnaam nieuw-naam nieuw-type ALTER TABEL naam VERVANG KOLOMMEN (col-spec (, col-spec ..)) | WIJZIG 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Een tabel uitschakelen | NA | schakel 'TABLE-NAME' -> uit om de opgegeven tabelnaam uit te schakelen
disable_all 'r *' -> om alle tabellen uit te schakelen die overeenkomen met de reguliere expressie |
| Een tabel inschakelen | NA | schakel 'TABLE-NAME' in |
| Een tafel neerzetten | DROPTAFEL ALS BESTAAT tabelnaam | Als we een tafel willen laten vallen, moeten we deze eerst uitschakelen
'tabelnaam' uitschakelen drop 'table-name' Op dezelfde manier kunnen we disable_all en drop_all gebruiken om de tabellen te verwijderen die overeenkomen met de opgegeven reguliere expressie. |
| Om databases weer te geven | databases weergeven; | NA |
| Om tabellen in de database weer te geven | toon tabellen; | lijst |
| Om het schema van een tabel te beschrijven | tabelnaam beschrijven; | beschrijf 'tabelnaam' |
Integratie van Hive vs HBase
- Hive installeren en configureren.
- Installeer en configureer HBase.
- Voor integratie van zowel Hive als HBase gebruiken we STORAGE HANDLERS in Hive.
- Storage Handlers is een combinatie van SERDE, InputFormat, OutputFormat die elke externe entiteit als een tabel in Hive accepteert.
- Dus deze functie helpt een gebruiker om SQL-vragen te stellen, of de tabel nu aanwezig is in Hadoop of in de op NOSQL gebaseerde database zoals HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Nu zullen we een voorbeeld bekijken voor het verbinden van Hive met HBase met behulp van HiveStorageHandler:
- Eerst moeten we de Hbase-tabel maken met behulp van de opdracht.
maak 'Student', 'personalinfo', 'dept info' aan
-> Persoonlijke info en afd. Info maken twee verschillende kolomfamilies in de studententabel.
- We moeten enkele gegevens in de studententabel invoegen, zoals hieronder vermeld.
zet 'student', 'sid01 ′, ' personalinfo: name ', ' Ram '
zet 'student', 'sid01 ′, ' personalinfo: mailid ', ' '
zet 'student', 'sid01 ′, ' deptinfo: deptname ', ' Java '
zet 'Student', 'sid01 ′, ' deptinfo: joinyear ', ' 1994 ′
-> Evenzo kunnen we gegevens maken voor sid02, sid03 …
- Nu moeten we Hive-tabel maken die naar HBase-tabel verwijst.
- Voor elke kolom in de Hbase maken we één specifieke tabel voor die kolom in Hive. In dit geval maken we 2 tabellen in Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Op dezelfde manier moeten we een gedetailleerde infotabel in de component maken.
- Nu kunnen we SQL-query's schrijven in een component zoals hieronder vermeld.
select * from student_hbase;
Op deze manier kunnen we Hive integreren met HBase.
Conclusie - Hive vs HBase
Zoals besproken, zijn het beide verschillende technologieën die verschillende functionaliteiten bieden waarbij Hive werkt met behulp van SQL-taal en het kan ook worden genoemd omdat HQL en HBase sleutel / waarde-paren gebruiken om de gegevens te analyseren. Hive en HBase werken beter als ze worden gecombineerd omdat Hive een lage latentie heeft en een enorme hoeveelheid gegevens kan verwerken, maar geen up-to-date gegevens kan behouden en HBase ondersteunt geen analyse van gegevens maar ondersteunt updates op rijniveau voor een grote hoeveelheid Van de gegevens.
Aanbevolen artikel
Dit is een leidraad geweest voor Hive vs HBase, hun betekenis, vergelijking van persoon tot persoon, belangrijkste verschillen, vergelijkingstabel en conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Apache Pig vs Apache Hive - Top 12 nuttige verschillen
- Ontdek de 7 beste verschillen tussen Hadoop en HBase
- Top 12 vergelijking van Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Hive - Ontdek de beste verschillen