
Overzicht van neurale netwerkalgoritmen
- Laten we eerst weten wat een neuraal netwerk betekent? Neurale netwerken zijn geïnspireerd door de biologische neurale netwerken in de hersenen of we kunnen zeggen het zenuwstelsel. Het heeft veel opwinding gegenereerd en er wordt nog steeds onderzoek gedaan naar deze subset van Machine Learning in de industrie.
- De basisberekeningseenheid van een neuraal netwerk is een neuron of een knooppunt. Het ontvangt waarden van andere neuronen en berekent de output. Elke knoop / neuron wordt geassocieerd met gewicht (w). Dit gewicht wordt gegeven volgens het relatieve belang van dat bepaalde neuron of knooppunt.
- Dus als we f als de knooppuntfunctie nemen, levert de knooppuntfunctie f uitvoer zoals hieronder wordt weergegeven: -
Uitgang van neuron (Y) = f (w1.X1 + w2.X2 + b)
- Waar w1 en w2 gewicht zijn, zijn X1 en X2 numerieke ingangen, terwijl b de voorspanning is.
- De bovenstaande functie f is een niet-lineaire functie, ook wel activeringsfunctie genoemd. Het basisdoel is niet-lineariteit te introduceren, omdat bijna alle gegevens uit de praktijk niet-lineair zijn en we willen dat neuronen deze representaties leren.
Verschillende neurale netwerkalgoritmen
Laten we nu eens kijken naar vier verschillende neurale netwerkalgoritmen.
1. Verloop afdaling
Het is een van de meest populaire optimalisatie-algoritmen op het gebied van machine learning. Het wordt gebruikt tijdens het trainen van een machine learning-model. In eenvoudige woorden, het wordt in principe gebruikt om waarden van de coëfficiënten te vinden die de kostenfunctie eenvoudigweg zoveel mogelijk verminderen. Allereerst beginnen we met het definiëren van enkele parameterwaarden en vervolgens met behulp van calculus beginnen we de waarden iteratief aan te passen zodat de verloren functie is verminderd.
Laten we nu naar het gedeelte gaan wat gradiënt is ?. Dus een gradiënt betekent in grote mate dat de uitvoer van een functie zal veranderen als we de invoer met weinig verminderen of met andere woorden we de helling kunnen noemen. Als de helling steil is, leert het model sneller, op dezelfde manier stopt een model met leren wanneer de helling nul is. Dit komt omdat het een minimalisatie-algoritme is dat een bepaald algoritme minimaliseert.
Hieronder wordt de formule voor het vinden van de volgende positie weergegeven in het geval van verloopdaling.
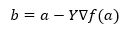
Waar b de volgende positie is
a is huidige positie, gamma is een wachtfunctie.
Dus, zoals je kunt zien, is gradiëntdaling een zeer degelijke techniek, maar er zijn veel gebieden waar gradiëntdaling niet goed werkt. Hieronder worden er enkele gegeven:
- Als het algoritme niet correct wordt uitgevoerd, kunnen we zoiets als het probleem van het verdwijnen van de gradiënt tegenkomen. Deze treden op wanneer het verloop te klein of te groot is.
- Er ontstaan problemen wanneer de gegevensindeling een niet-convex optimalisatieprobleem oplevert. Gradiënt fatsoenlijk werkt alleen met problemen die het convexe geoptimaliseerde probleem zijn.
- Een van de zeer belangrijke factoren om op te letten bij het toepassen van dit algoritme zijn middelen. Als we minder geheugen hebben toegewezen voor de toepassing, moeten we algoritme voor het verloop van de gradiënt vermijden.
2. Newton's methode
Het is een optimalisatie-algoritme van de tweede orde. Het wordt een tweede orde genoemd omdat het gebruik maakt van de Hessische matrix. De Hessische matrix is dus niets anders dan een vierkante matrix van tweede-orde partiële afgeleiden van een scalaire waarde. In Newton's methode-optimalisatie-algoritme wordt het toegepast op de eerste afgeleide van een dubbele differentieerbare functie f zodat het de wortels kan vinden / stationaire punten. Laten we nu ingaan op de stappen die Newton's optimalisatiemethode nodig heeft.
Het evalueert eerst de verliesindex. Vervolgens wordt gecontroleerd of de stopcriteria waar of onwaar zijn. Als het niet waar is, berekent het vervolgens de trainingsrichting van Newton en de trainingssnelheid en verbetert het vervolgens de parameters of gewichten van het neuron en opnieuw gaat dezelfde cyclus verder.Dus je kunt nu zeggen dat het minder stappen neemt in vergelijking met gradiëntdaling om het minimum te krijgen waarde van de functie. Hoewel het minder stappen neemt in vergelijking met het algoritme voor het verloop van de gradiënt, wordt het nog steeds niet veel gebruikt, omdat de exacte berekening van jute en zijn inverse rekenkundig erg duur is.
3. Vervoeg gradiënt
Het is een methode die kan worden beschouwd als iets tussen gradiëntdaling en de methode van Newton. Het belangrijkste verschil is dat het de langzame convergentie versnelt die we meestal associëren met gradiëntdaling. Een ander belangrijk feit is dat het kan worden gebruikt voor zowel lineaire als niet-lineaire systemen en het is een iteratief algoritme.
Het werd ontwikkeld door Magnus Hestenes en Eduard Stiefel. Zoals hierboven al vermeld dat het snellere convergentie produceert dan gradiëntdaling, is de reden dat het in staat is om in het Conjugate Gradient-algoritme te zoeken samen met de conjugaatrichtingen, waardoor het sneller convergeert dan gradiëntdalingalgoritmen. Een belangrijk punt om op te merken is dat γ de conjugaatparameter wordt genoemd.
De trainingsrichting wordt periodiek opnieuw ingesteld op het negatief van het verloop. Deze methode is effectiever dan gradiëntdaling bij het trainen van het neurale netwerk, omdat er geen Hessiaanse matrix nodig is die de rekenbelasting verhoogt en ook sneller convergeert dan gradiëntdaling. Het is geschikt om te gebruiken in grote neurale netwerken.
4. Quasi-Newton-methode
Het is een alternatieve benadering voor de methode van Newton, omdat we ons er nu van bewust zijn dat de methode van Newton rekenkundig duur is. Deze methode lost die nadelen op in een mate dat in plaats van de Hessische matrix te berekenen en vervolgens de inverse direct te berekenen, deze methode een benadering voor inverse Hessian opbouwt bij elke iteratie van dit algoritme.
Nu wordt deze benadering berekend met behulp van de informatie uit de eerste afgeleide van de verliesfunctie. We kunnen dus zeggen dat het waarschijnlijk de meest geschikte methode is om met grote netwerken om te gaan, omdat het rekentijd bespaart en het is ook veel sneller dan gradiëntdaling of geconjugeerde gradiëntmethode.
Conclusie
Voordat we dit artikel beëindigen, laten we de berekeningssnelheid en het geheugen voor de bovengenoemde algoritmen vergelijken. Volgens geheugenvereisten vereist gradiëntdaling het minste geheugen en is het ook de langzaamste. In tegenstelling tot die methode vereist de methode van Newton meer rekenkracht. Dus met al deze overwegingen is de Quasi-Newton-methode het meest geschikt.
Aanbevolen artikelen
Dit is een gids geweest voor neurale netwerkalgoritmen. Hier bespreken we ook het overzicht van het neurale netwerkalgoritme samen met respectievelijk vier verschillende algoritmen. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Machine learning versus neuraal netwerk
- Machine Learning Frameworks
- Neurale netwerken versus diep leren
- K- betekent clusteringalgoritme
- Gids voor classificatie van neuraal netwerk