

Verschil tussen Hadoop en Hive
Hadoop:
Hadoop is een Framework of Software die is uitgevonden om enorme gegevens of Big Data te beheren. Hadoop wordt gebruikt voor het opslaan en verwerken van de grote gegevens die over een cluster van commodity-servers zijn verdeeld.
Hadoop slaat de gegevens op met het door Hadoop gedistribueerde bestandssysteem en verwerkt / bevraagt deze met behulp van het Map Reduce-programmeermodel.
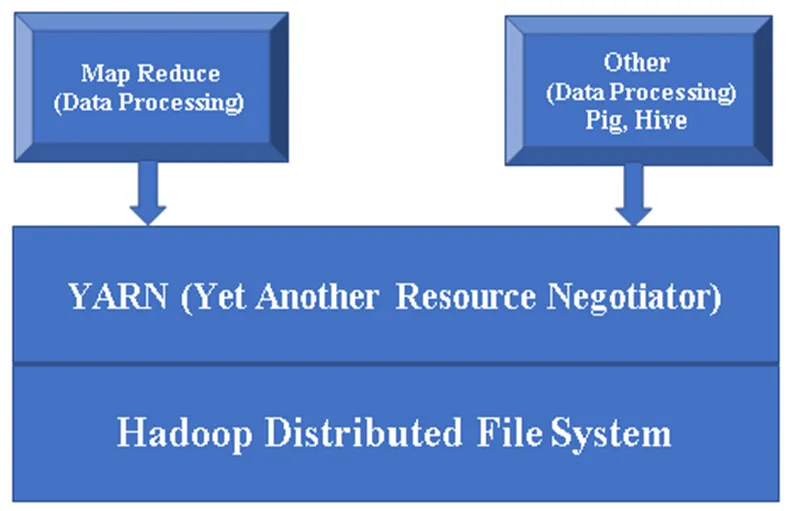
Afbeelding 1, een basisarchitectuur van een Hadoop-component.
De belangrijkste componenten van Hadoop:
Hadoop Base / Common: Hadoop common biedt u één platform om alle componenten te installeren.
HDFS (Hadoop Distributed File System): HDFS is een belangrijk onderdeel van het Hadoop-framework en zorgt voor alle gegevens in Hadoop Cluster. Het werkt op Master / Slave Architecture en slaat de gegevens op met behulp van replicatie.
Master / Slave-architectuur & replicatie:
- Hoofdknooppunt / naamknooppunt: Naamknooppunt slaat de metagegevens op van elk blok / bestand dat is opgeslagen in HDFS, HDFS kan slechts één hoofdknooppunt hebben (in het geval van HA werkt een andere hoofdknooppunt als secundaire hoofdknooppunt).
- Slave-knooppunt / gegevensknooppunt: gegevensknooppunten bevatten feitelijke gegevensbestanden in blokken. HDFS kan meerdere gegevensknooppunten hebben.
- Replicatie: HDFS slaat zijn gegevens op door ze in blokken te verdelen. Standaard blokgrootte is 64 MB. Vanwege replicatiegegevens worden opgeslagen in 3 (standaardreplicatiefactor, kan worden verhoogd als per eis) verschillende dataknopen, daarom is er de minste mogelijkheid om de gegevens te verliezen in het geval van een knooppuntfout.
YARN (Yet Another Resource Negotiator): Het wordt in principe gebruikt voor het beheer van Hadoop-bronnen en speelt ook een belangrijke rol in de planning van de toepassing van gebruikers.
MR (Map Reduce): dit is het basisprogrammeermodel van Hadoop. Het wordt gebruikt om de gegevens binnen Hadoop-framework te verwerken / opvragen.
Bijenkorf:
Hive is een applicatie die over het Hadoop-framework loopt en een SQL-achtige interface biedt voor het verwerken / opvragen van de gegevens. Hive is ontworpen en ontwikkeld door Facebook voordat hij deel ging uitmaken van het Apache-Hadoop-project.
Hive voert zijn query uit met behulp van HQL (Hive query language). Hive heeft dezelfde structuur als RDBMS en bijna dezelfde opdrachten kunnen in Hive worden gebruikt.
Hive kan de gegevens opslaan in externe tabellen, dus het is niet verplicht om HDFS te gebruiken en ondersteunt ook bestandsformaten zoals ORC, Avro-bestanden, Sequence-bestanden en tekstbestanden enz.
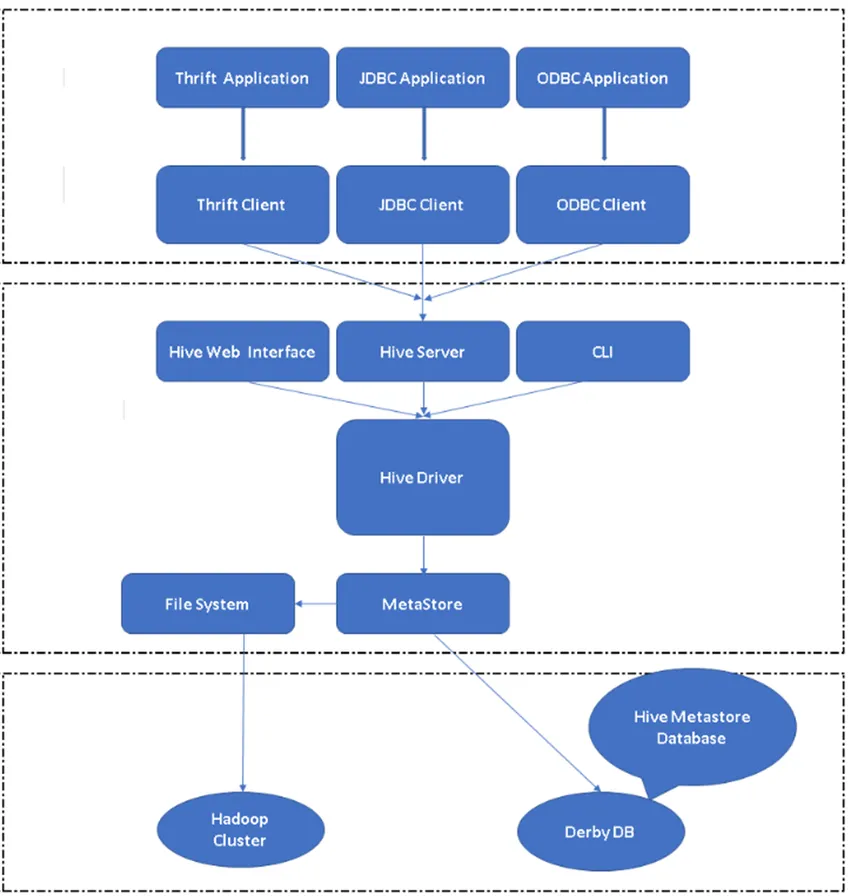
Figuur 2, Hive's Architecture & It's belangrijkste componenten.
Hive's belangrijkste component:
Hive Clients: niet alleen SQL, Hive ondersteunt ook programmeertalen zoals Java, C, Python met behulp van verschillende stuurprogramma's zoals ODBC, JDBC en Thrift. Je kunt elke client-applicatie in andere talen schrijven en met deze clients in Hive uitvoeren.
Hive Services: onder Hive services vinden opdrachten en query's plaats. Hive webinterface heeft vijf subcomponenten.
- CLI: standaard opdrachtregelinterface geleverd door Hive voor uitvoering van Hive-query's / -opdrachten.
- Hive Web Interfaces: het is een eenvoudige grafische gebruikersinterface. Het is een alternatief voor de opdrachtregel van Hive en wordt gebruikt om de query's en opdrachten in de toepassing Hive uit te voeren.
- Hive Server: het wordt ook wel Apache Thrift genoemd. Het is verantwoordelijk om opdrachten uit verschillende opdrachtregelinterfaces te nemen en alle opdrachten / query's naar Hive in te dienen, ook wordt het eindresultaat opgehaald.
- Apache Hive Driver: het is verantwoordelijk voor het nemen van de invoer van de CLI, de web UI, ODBC, JDBC of Thrift-interfaces door een client en geeft de informatie door aan metastore waar alle bestandsinformatie is opgeslagen.
- Metastore: Metastore is een repository voor het opslaan van alle Hive metadata-informatie. Hive's metadata slaat de informatie op zoals de structuur van tabellen, partities & kolomtype enz …
Hive Storage: dit is de locatie waar de daadwerkelijke taak wordt uitgevoerd. Alle vragen die vanuit Hive worden uitgevoerd, hebben de actie in Hive Storage uitgevoerd.
Head to Head-vergelijking tussen Hadoop vs Hive (infographics)
Hieronder is het top 8 verschil tussen Hadoop versus Hive
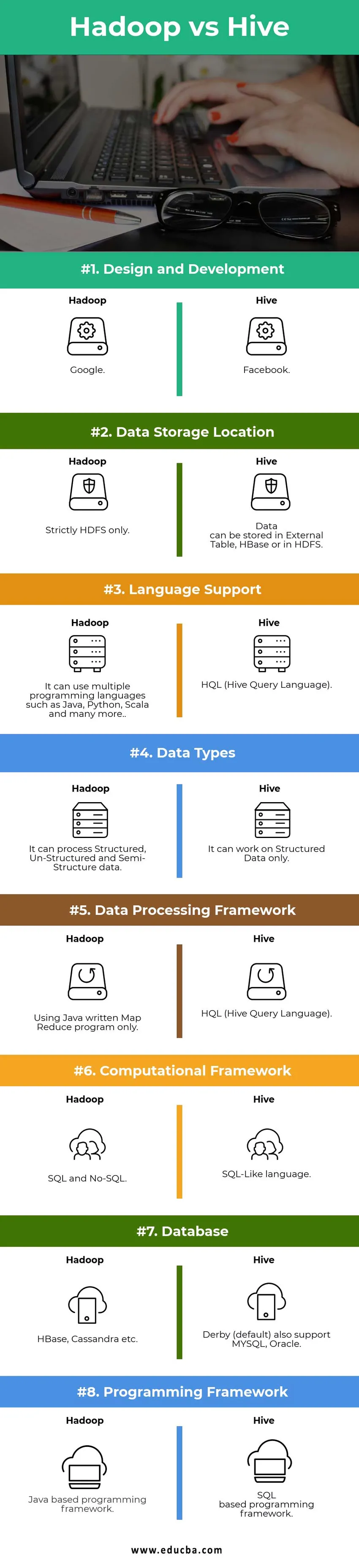
Belangrijkste verschillen tussen Hadoop versus Hive:
Hieronder staan de lijst met punten, beschrijf de belangrijkste verschillen tussen Hadoop en Hive:
1) Hadoop is een framework voor het verwerken / doorzoeken van de Big data, terwijl Hive een op SQL gebaseerd hulpmiddel is dat over Hadoop is gebouwd om de gegevens te verwerken.
2) Hive-proces / query alle gegevens met behulp van HQL (Hive Query Language), het is SQL-achtige taal, terwijl Hadoop alleen Map Reduce kan begrijpen.
3) Map Reduce is een integraal onderdeel van Hadoop, de zoekopdracht van Hive wordt eerst omgezet in Map Reduce en vervolgens verwerkt door Hadoop om de gegevens op te vragen.
4) Hive werkt op SQL-achtige query, terwijl Hadoop het begrijpt met alleen Java-gebaseerde Map Reduce.
5) In Hive kunnen eerder gebruikte traditionele "Relational Database's" -opdrachten ook worden gebruikt om de big data op te vragen, terwijl in Hadoop complexe Map Reduce-programma's moeten schrijven met behulp van Java die niet vergelijkbaar zijn met de traditionele Java.
6) Hive kan alleen de gestructureerde gegevens verwerken / opvragen, terwijl Hadoop bedoeld is voor alle soorten gegevens, ongeacht of deze gestructureerd, ongestructureerd of semi-gestructureerd zijn.
7) Met behulp van Hive kan men de gegevens verwerken / opvragen zonder complexe programmering, terwijl in het Simple Hadoop-ecosysteem een complex Java-programma moet worden geschreven voor dezelfde gegevens.
8) Eén kant Hadoop-frameworks hebben een regel van 100 seconden nodig voor het voorbereiden van een op Java gebaseerd MR-programma. Een andere kant Hadoop met Hive kan dezelfde gegevens opvragen met 8 tot 10 regels HQL.
9) In Hive is het erg moeilijk om de uitvoer van een query in te voegen als invoer van een andere, terwijl dezelfde query eenvoudig kan worden gedaan met Hadoop met MR.
10) Het is niet verplicht om Metastore in Hadoop-cluster te hebben Terwijl Hadoop al zijn metadata in HDFS (Hadoop Distributed File System) opslaat.
Vergelijkingstabel Hadoop vs Hive
| Vergelijkingspunten | Bijenkorf | Hadoop |
|
Ontwerp en ontwikkeling | ||
| Gegevensopslaglocatie |
Gegevens kunnen worden opgeslagen in Extern Tabel, HBase of in HDFS. | Strikt alleen HDFS. |
| Taalondersteuning | HQL (Hive Query Language) |
Het kan meerdere programmeertalen gebruiken zoals Java, Python, Scala en nog veel meer. |
| Gegevenstypen | Het kan alleen op gestructureerde gegevens werken. |
Het kan gestructureerde, niet-gestructureerde en semi-gestructureerde gegevens verwerken. |
| Data Processing Framework |
HQL (Hive Query Language) | Alleen met Java geschreven Map Reduce-programma. |
|
Computationeel kader | SQL-achtige taal. | SQL en No-SQL. |
| Database |
Derby (standaard) ondersteunt ook MYSQL, Oracle… | HBase, Cassandra enz … |
| Programmeer Framework |
Op SQL gebaseerd programmeerraamwerk. | Op Java gebaseerd programmeerraamwerk. |
Conclusie - Hadoop vs Hive
Hadoop en Hive worden beide gebruikt om de Big data te verwerken. Hadoop is een framework dat platform biedt voor andere applicaties om de Big Data te bevragen / verwerken, terwijl Hive slechts een op SQL gebaseerde applicatie is die de data verwerkt met behulp van HQL (Hive Query Language)
Hadoop kan zonder Hive worden gebruikt om de big data te verwerken, terwijl het niet eenvoudig is om Hive zonder Hadoop te gebruiken.
Concluderend kunnen we Hadoop en Hive hoe dan ook in geen enkel opzicht vergelijken. Zowel Hadoop als Hive zijn compleet anders. Door beide technologie samen te gebruiken, kan het Big Data-queryproces voor Big Data-gebruikers veel eenvoudiger en comfortabeler worden.
Aanbevolen artikelen:
Dit is een leidraad geweest voor Hadoop vs Hive, hun betekenis, vergelijking van persoon tot persoon, belangrijkste verschillen, vergelijkingstabel en conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Hadoop vs Apache Spark - interessante dingen die u moet weten
- HADOOP versus RDBMS | Ken de 12 nuttige verschillen
- Hoe big data het gezicht van de gezondheidszorg verandert
- Top 12 vergelijking van Apache Hive vs Apache HBase (Infographics)
- Geweldige gids over Hadoop vs Spark