

Inleiding tot deelname in Spark SQL
Zoals we weten, worden de joins in SQL gebruikt om gegevens of rijen uit twee of meer tabellen te combineren op basis van een gemeenschappelijk veld daartussen. In dit onderwerp gaan we meer te weten over Join in Spark SQL Join in Spark SQL.
In Spark SQL zijn Dataframe of Dataset een tabelstructuur in het geheugen met rijen en kolommen die over meerdere knooppunten zijn verdeeld. Net als normale SQL-tabellen kunnen we ook join-bewerkingen uitvoeren op Dataframe of Dataset in Spark SQL op basis van een gemeenschappelijk veld daartussen.
Er zijn verschillende soorten Join-bewerkingen beschikbaar in SQL. Afhankelijk van de business use case, maken we de keuze voor Join-bewerking. In de volgende sectie gaan we elk type join met voorbeeld demonstreren.
Soorten Join in Spark SQL
Hier volgen de verschillende typen Joins die beschikbaar zijn in Spark SQL:
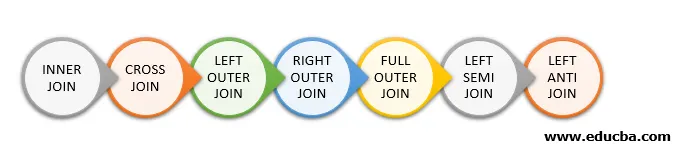
- BINNENKANTE
- CROSS JOIN
- LINKER BUITENKANT
- JUISTE BUITENKANT
- VOLLEDIGE BUITENKANTE
- LINKER SEMI JOIN
- LINKER ANTI-JOIN
Voorbeeld van gegevenscreatie
We zullen de volgende gegevens gebruiken om de verschillende typen joins te demonstreren:
Gegevensset boek:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Writer Dataset:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Soorten Joins
Hieronder worden 7 verschillende soorten Joins genoemd:
1. BINNENKOPPEL
De INNER JOIN retourneert de gegevensset met de rijen met overeenkomende waarden in beide gegevenssets, dwz de waarde van het gemeenschappelijke veld is hetzelfde.
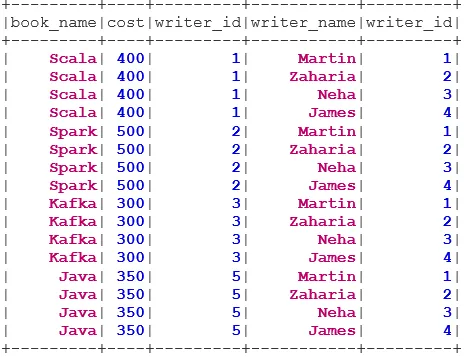
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CROSS JOIN
De CROSS JOIN retourneert de gegevensset, het aantal rijen in de eerste gegevensset vermenigvuldigd met het aantal rijen in de tweede gegevensset. Een dergelijk resultaat wordt het Cartesiaanse product genoemd.
Voorwaarde: voor het gebruik van een cross-join moet spark.sql.crossJoin.enabled zijn ingesteld op true. Anders wordt de uitzondering gegenereerd.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. LINKER BUITENKOPPELING
De LEFT OUTER JOIN retourneert de gegevensset met alle rijen uit de linker gegevensset en de overeenkomende rijen uit de rechter gegevensset.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. JUISTE BUITENKANT
De JUISTE BUITENKANT retourneert de gegevensset met alle rijen uit de rechter gegevensset en de overeenkomende rijen uit de linker gegevensset.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. VOLLEDIGE BUITENKOPPELING
De FULL OUTER JOIN retourneert de gegevensset met alle rijen als er een overeenkomst is in de linker- of rechtergegevensset.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. LINKS SEMI-JOIN
De LEFT SEMI JOIN retourneert de gegevensset met alle rijen uit de linker gegevensset met hun correspondentie in de rechter gegevensset. In tegenstelling tot de LEFT OUTER JOIN, bevat de geretourneerde dataset in LEFT SEMI JOIN alleen de kolommen uit de linker dataset.
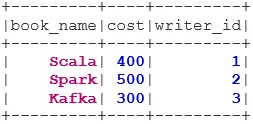
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. LINKS ANTI-JOIN
De ANTI SEMI JOIN retourneert de gegevensset met alle rijen uit de linker gegevensset die niet overeenkomen in de juiste gegevensset. Het bevat ook alleen de kolommen uit de linkergegevensset.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Conclusie - Doe mee aan Spark SQL
Het samenvoegen van gegevens is een van de meest voorkomende en belangrijke bewerkingen om aan onze business use case te voldoen. Spark SQL ondersteunt alle fundamentele typen joins. Terwijl we lid worden, moeten we ook rekening houden met de prestaties, omdat ze mogelijk grote netwerkoverdrachten vereisen of zelfs datasets maken die buiten onze mogelijkheden liggen. Voor prestatieverbetering gebruikt Spark SQL optimizer om filters opnieuw te ordenen of omlaag te duwen. Spark beperkt ook de gevaarlijke join i. e CROSS JOIN. Voor het gebruik van een cross-join moet spark.sql.crossJoin.enabled expliciet op true worden ingesteld.
Aanbevolen artikelen
Dit is een gids voor Join in Spark SQL. Hier bespreken we de verschillende soorten Joins die beschikbaar zijn in Spark SQL met het voorbeeld. U kunt ook het volgende artikel bekijken.
- Typen joins in SQL
- Tabel in SQL
- Query invoegen
- Transacties in SQL
- PHP-filters | Hoe gebruikersinvoer valideren met behulp van verschillende filters?