

Wat is het boost-algoritme?
Boosting is de methode in algoritmen die een zwakke leerling omzetten in een sterke leerling. Het is een techniek die nieuwe modellen toevoegt om fouten in bestaande modellen te corrigeren.
Voorbeeld:
Laten we dit concept begrijpen met behulp van het volgende voorbeeld. Laten we een voorbeeld nemen van de e-mail. Hoe herkent u uw e-mail, of deze nu spam is of niet? Je herkent het aan de volgende voorwaarden:
- Als een e-mail veel bronnen bevat, betekent dit dat het spam is.
- Als een e-mail slechts één bestandsafbeelding bevat, is dit spam.
- Als een e-mail het bericht 'U bezit een loterij van $ xxxxx' bevat, betekent dit dat het spam is.
- Als een e-mail een bekende bron bevat, is dit geen spam.
- Als het het officiële domein zoals educba.com, enz. Bevat, betekent dit dat het geen spam is.
De bovengenoemde regels zijn niet zo krachtig om spam te herkennen of niet, daarom worden deze regels als zwakke leerlingen genoemd.
Om een zwakke leerling om te zetten in een sterke leerling, combineert u de voorspelling van de zwakke leerling met behulp van de volgende methoden.
- Gemiddeld of gewogen gemiddelde gebruiken.
- Overweeg dat voorspelling een hogere stem heeft.
Overweeg de bovengenoemde 5 regels, er zijn 3 stemmen voor spam en 2 stemmen voor geen spam. Aangezien er spam met een hoge stem is, beschouwen we deze als spam.
Hoe Boosting Algorithms werkt?
Boosting Algorithms combineert elke zwakke leerling om één sterke voorspellingsregel te creëren. Om de zwakke regel te identificeren, is er een basis Learning-algoritme (Machine Learning). Wanneer Base-algoritme wordt toegepast, creëert het nieuwe voorspellingsregels met behulp van het iteratieproces. Na enige iteratie combineert het alle zwakke regels om een enkele voorspellingsregel te maken.
Volg de onderstaande stappen om de juiste verdeling te kiezen:
Stap 1: Base Learning-algoritme combineert elke verdeling en past hetzelfde gewicht toe aan elke verdeling.
Stap 2: Als er een voorspelling optreedt tijdens het eerste basisleeralgoritme, besteden we veel aandacht aan die voorspellingsfout.
Stap 3: Herhaal stap 2 totdat de limiet van het Base Learning-algoritme is bereikt of een hoge nauwkeurigheid.
Stap 4: Ten slotte combineert het alle zwakke leerlingen om één sterke voorspellingstule te maken.
Soorten boost-algoritme
Boosting-algoritmen maakt gebruik van verschillende motoren, zoals beslissingsstempel, marge maximaliserend classificatie-algoritme, enz. Er zijn drie soorten boost-algoritmen die als volgt zijn:
- AdaBoost-algoritme (Adaptive Boosting)
- Gradient Boosting-algoritme
- XG Boost-algoritme
AdaBoost-algoritme (Adaptive Boosting)
Raadpleeg de onderstaande afbeelding om AdaBoost te begrijpen:
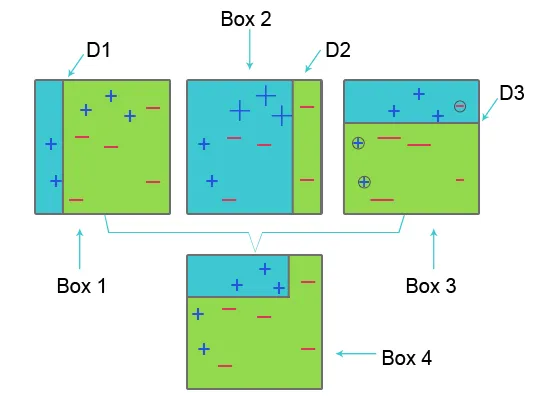
Box 1: In Box 1 hebben we voor elke dataset gelijke gewichten toegewezen en om het plusteken (+) en minteken (-) te classificeren passen we beslissingsstomp D1 toe die een verticale lijn aan de linkerkant van box 1 creëert. voorspelde drie plustekens (+) als min (-) vandaar dat we hogere gewichten toepassen op dit plusteken en een andere beslissingsstomp toepassen.
Box 2: In Box 2 wordt de grootte van drie verkeerd voorspelde plustekens (+) groter in vergelijking met een andere. De tweede beslissingsstomp D2 aan de rechterkant van het blok voorspelt dit onjuist voorspelde plusteken (+) als correct. Maar omdat er een misclassificatiefout is opgetreden vanwege het ongelijke gewicht met een minteken (-), kennen we een hoger gewicht toe aan een minteken (-) en passen we een andere beslissingsstomp toe.
Vak 3: In vak drie heeft een minus teken (-) vanwege misclassificatiefout een hoog gewicht. hier wordt beslissingsstomp D3 toegepast om deze verkeerde classificatie te voorspellen en te corrigeren. Dit keer om de horizontale lijn van het plusteken (+) en minteken (-) te classificeren.
Box 4: In Box 4 worden beslissingsstomp D1, D2 en D3 gecombineerd om een nieuwe sterke voorspelling te creëren.
Adaptive Boosting-werken zijn vergelijkbaar zoals hierboven vermeld. Het combineert de groep van zwakke leerlingen op basis van gewichtleeftijd om een sterke leerling te creëren. In de eerste iteratie weegt elke dataset even zwaar en begint die dataset te voorspellen. Als een onjuiste voorspelling optreedt, wordt die waarneming zwaarder belast. Adaptieve boosting herhaalt deze procedure in de volgende iteratiefase en gaat door totdat de nauwkeurigheid is bereikt. Combineert dit vervolgens om een sterke voorspelling te maken.
Gradiëntversterkend algoritme
Gradient boosting algoritme is een machine learning-techniek om de verliesfunctie te definiëren en te verminderen. Het wordt gebruikt om classificatieproblemen met voorspellingsmodellen op te lossen. Het omvat de volgende stappen:
1. Verliesfunctie
Het gebruik van de verliesfunctie is afhankelijk van het type probleem. Het voordeel van gradiëntversterking is dat er geen behoefte is aan een nieuw versterkingsalgoritme voor elke verliesfunctie.
2. Zwakke leerling
Bij het verhogen van de gradiënt worden beslissingsbomen gebruikt als een zwakke leerling. Een regressieboom wordt gebruikt om echte waarden te geven die kunnen worden gecombineerd om correcte voorspellingen te maken. Net als in het AdaBoost-algoritme worden kleine bomen met een enkele split gebruikt, dwz beslissingsstomp. Grotere bomen worden gebruikt voor grote niveaus i, e 4-8 niveaus.
3. Additief model
In dit model worden bomen één voor één toegevoegd. bestaande bomen blijven hetzelfde. Tijdens het toevoegen van bomen wordt gradiëntdaling gebruikt om de verliesfunctie te minimaliseren.
XG Boost
XG Boost staat voor Extreme Gradient Boosting. XG Boost is een verbeterde implementatie van Gradient Boosting Algorithm dat is ontwikkeld voor hoge berekeningssnelheid, schaalbaarheid en betere prestaties.
XG Boost heeft verschillende functies die als volgt zijn:
- Parallelle verwerking: XG Boost biedt parallelle verwerking voor boomconstructie waarbij CPU-cores worden gebruikt tijdens de training.
- Cross-Validation: XG Boost stelt gebruikers in staat om cross-validatie van het boostproces bij elke iteratie uit te voeren, waardoor het gemakkelijk is om het exacte optimale aantal boost iteraties in één run te krijgen.
- Cache-optimalisatie: het biedt Cache-optimalisatie van de algoritmen voor een hogere uitvoeringssnelheid.
- Distributed Computing : voor het trainen van grote modellen maakt XG Boost Distributed Computing mogelijk.
Aanbevolen artikelen
In dit artikel hebben we gezien wat Boosting Algorithm is, verschillende soorten Boosting Algorithm in machine learning en hun werking. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Wat is machinaal leren? | Een betekenis
- Programmeertalen voor het leren van algoritmen
- Wat is Blockchain-technologie?
- Wat is een algoritme?